A Simple Neural Network Module for Relational Reasoning
Citation
Santoro, Raposo, Barrett, Malinowski, Pascanu, Battaglia, Lillicrap (DeepMind), NeurIPS, 2017.
Overview
Relation Networks (RNs) are a simple neural network module for relational reasoning that achieve superhuman performance on visual question answering by explicitly computing learned functions over all pairwise object combinations. The key insight is that relational reasoning -- comparing, relating, and reasoning about multiple entities -- is a distinct cognitive capability that standard neural networks lack an inductive bias for, and a dedicated module can provide this bias with minimal architectural complexity.
The module computes answer = f_phi(sum_{i,j} g_theta(o_i, o_j, q)), where g_theta is a learned pairwise relation function, the sum provides permutation invariance, and f_phi produces the final output. Objects are extracted from CNN feature maps by treating each spatial location as an "object" representation, avoiding explicit object detection. The question embedding q is concatenated with each pair, allowing question-specific relation computation. This plug-and-play module can be appended to any encoder and trained end-to-end.
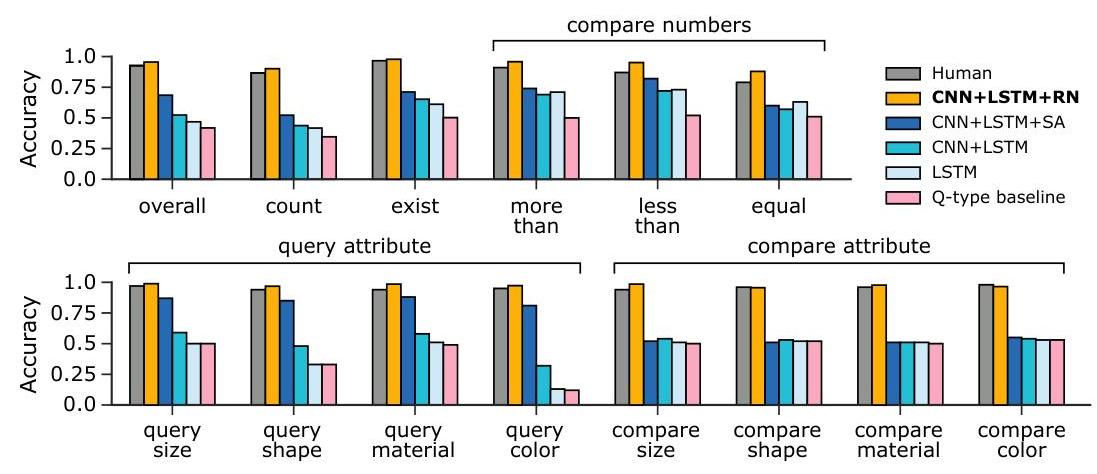
This paper demonstrated that the bottleneck in visual reasoning was not perceptual but relational -- the RN module achieved 95.5% on CLEVR (vs. 52.3% for CNN+LSTM and 76.6% for CNN+LSTM+SA* baselines, and 92.6% for humans). The work influenced the broader trend toward structured, compositional reasoning modules in deep learning and directly informed later work on graph neural networks and relational inductive biases.
Key Contributions
- Relation Network module: Computes answer = f_phi(sum_{i,j} g_theta(o_i, o_j, q)) where g_theta is a learned pairwise relation function, the sum provides permutation invariance, and f_phi produces the final output
- Object extraction from CNNs: Treats each spatial location in a CNN feature map as an "object" representation, avoiding the need for explicit object detection or segmentation
- Question conditioning: The question embedding q is concatenated with each object pair (o_i, o_j, q), allowing the relation function to compute question-specific relations
- Cross-domain generality: The same module architecture works for visual QA (CLEVR), text-based reasoning (bAbI), and dynamic physical scenes, demonstrating domain-agnostic relational reasoning
- O(n^2) explicit enumeration: Rather than learning implicit attention patterns, enumerates all pairs explicitly, ensuring no relational signal is missed
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ Relation Network (RN) │
├──────────────────────────────────────────────────────────────┤
│ │
│ Image Question │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ 4-layer │ │ LSTM │ │
│ │ CNN │ │ Encoder │ │
│ └────┬─────┘ └────┬─────┘ │
│ ▼ │ │
│ d x d feature map │ │
│ (d^2 "objects") │ q (question embedding) │
│ │ │ │
│ ▼ │ │
│ Form all n^2 pairs │ │
│ (o_i, o_j) for i,j │ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ g_theta( o_i, o_j, q ) │ MLP (4 layers, │
│ │ for each pair (i,j) │ 256 units, ReLU) │
│ └──────────────┬─────────────────────┘ │
│ ▼ │
│ Element-wise SUM over all pairs │
│ │ │
│ ▼ │
│ ┌────────────┐ │
│ │ f_phi(.) │ MLP ──► Answer │
│ └────────────┘ │
└──────────────────────────────────────────────────────────────┘
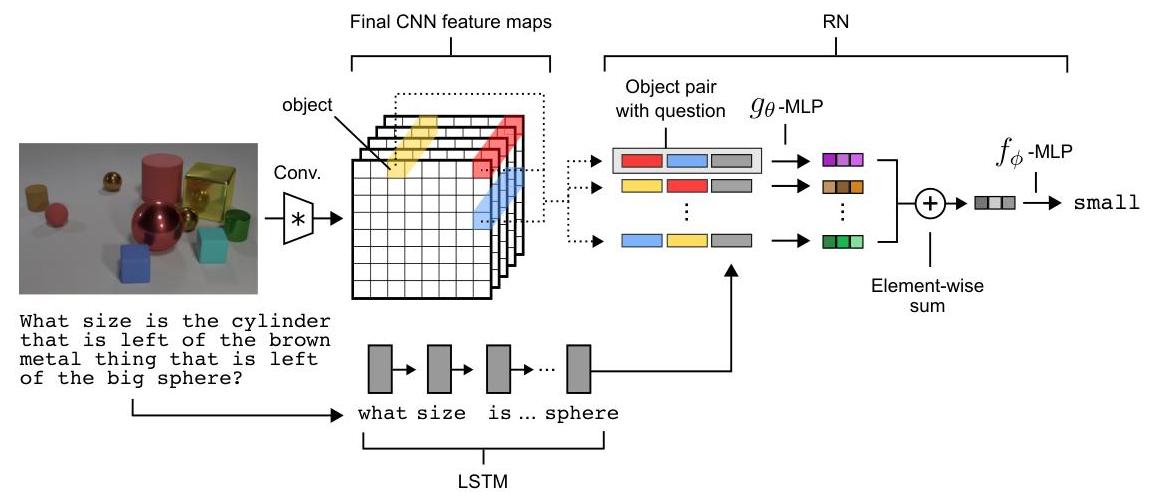

The RN module sits on top of a task-specific encoder. For visual QA (CLEVR), a 4-layer CNN processes the image into a d x d feature map, where each of the d^2 spatial positions is treated as an object vector o_i. For text-based reasoning (bAbI), each sentence is encoded by an LSTM into an object vector. The question is encoded separately (LSTM for text questions, CNN for visual questions) into a fixed-size vector q.
All n^2 pairs (o_i, o_j) are formed and concatenated with q to produce inputs to g_theta, a small MLP (typically 4 layers with 256 units and ReLU activations). The outputs of g_theta are summed element-wise across all pairs, and the aggregate is passed through f_phi (another MLP) to produce the final answer. Both g_theta and f_phi are trained end-to-end with cross-entropy loss.
For the Sort-of-CLEVR diagnostic dataset, the authors created a simplified version of CLEVR with explicit relational and non-relational question types, allowing clean ablation of the relational reasoning contribution.
Results
| Dataset | Model | Accuracy |
|---|---|---|
| CLEVR | CNN+LSTM+RN | 95.5% |
| CLEVR | Human baseline | 92.6% |
| CLEVR | CNN+LSTM+SA* (RN authors' impl.) | 76.6% |
| CLEVR | CNN+LSTM | 52.3% |
| Sort-of-CLEVR (relational) | CNN+RN | 94% |
| Sort-of-CLEVR (relational) | CNN+MLP | 63% |
| bAbI | RN | 18/20 tasks solved |
- Superhuman CLEVR performance: 95.5% accuracy on CLEVR vs. 92.6% human baseline, 76.6% for CNN+LSTM+SA* (the authors' own optimized stacked-attention implementation), and 52.3% for the published CNN+LSTM baseline, with near-perfect accuracy on relational question subtypes (compare relations, spatial reasoning)
- Relational vs. non-relational separation: On Sort-of-CLEVR, RN achieves 94% on relational questions where CNN+MLP achieves only 63%, while both perform similarly on non-relational questions, isolating the contribution of explicit relational reasoning
- Near-perfect bAbI performance: Achieves >95% accuracy on all 20 bAbI tasks including the hardest relational reasoning tasks, matching or exceeding memory-augmented networks
- Dynamic physical scenes: The RN module successfully predicts future states of interacting objects in a physics simulation, demonstrating relational reasoning beyond static scenes
Limitations & Open Questions
- O(n^2) pairwise computation limits scalability to scenes with many objects; for n=100 objects, 10,000 pairs must be processed
- The module computes only binary relations; higher-order relations (ternary, quaternary) require stacking or architectural extensions
- Object extraction via CNN spatial locations is a crude proxy; the approach assumes a fixed spatial grid rather than true object-centric representations