Overview
AutoRT addresses the critical data scarcity problem in robotics by using foundation models not as end-effectors but as intelligent orchestrators of large-scale robot data collection. Developed by Google DeepMind, the system deploys fleets of 20+ robots simultaneously across real office environments, using VLMs for scene understanding and LLMs for task generation. Over 7 months, AutoRT collected 77,000 real-world episodes across 53 robots in 4 buildings -- a scale unprecedented in robotic data collection. A "Robot Constitution" inspired by constitutional AI embeds safety rules directly into task generation, improving safe task proposals from 26% to 87% under adversarial testing.
Key Contributions
- Foundation model orchestration paradigm: Shifts from using LLMs/VLMs for robot control to using them as coordinators of the entire data collection pipeline through scene understanding and task generation
- Robot Constitution: Applies constitutional AI principles to physical robotics, embedding foundational, safety, embodiment, and guidance rules into LLM prompts for safe task generation
- Adaptive policy selection: Dynamically routes between teleoperation, scripted policies, and learned RT-2 execution based on supervisor availability, enabling one human to oversee 3-5 robots
- Scale demonstration: 77,000 episodes, 6,650+ unique tasks, 53 robots -- the largest real-world robotic data collection campaign reported
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ AutoRT Orchestration Pipeline │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────────┐ ┌──────────────┐ │
│ │ Exploration │───►│ Task Generation │───►│ Affordance │ │
│ │ (Nav + Map) │ │ (VLM + LLM) │ │ Filtering │ │
│ └──────────────┘ └──────────────────┘ └──────┬───────┘ │
│ │ │ │ │
│ Object Detection Robot Constitution LLM Validator │
│ + Semantic Map (Safety Rules) (Feasibility) │
│ │ │
│ ┌────────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Hybrid Data Collection │ │
│ ├──────────┬───────┬───────┤ │
│ │ Teleop │Script │ RT-2 │ │
│ │ (human) │(auto) │(VLA) │ │
│ └──────────┴───────┴───────┘ │
│ 1:3-5 human:robot ratio │
│ │ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ 77K episodes, 53 robots │ │
│ │ 6,650+ unique tasks │ │
│ └──────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
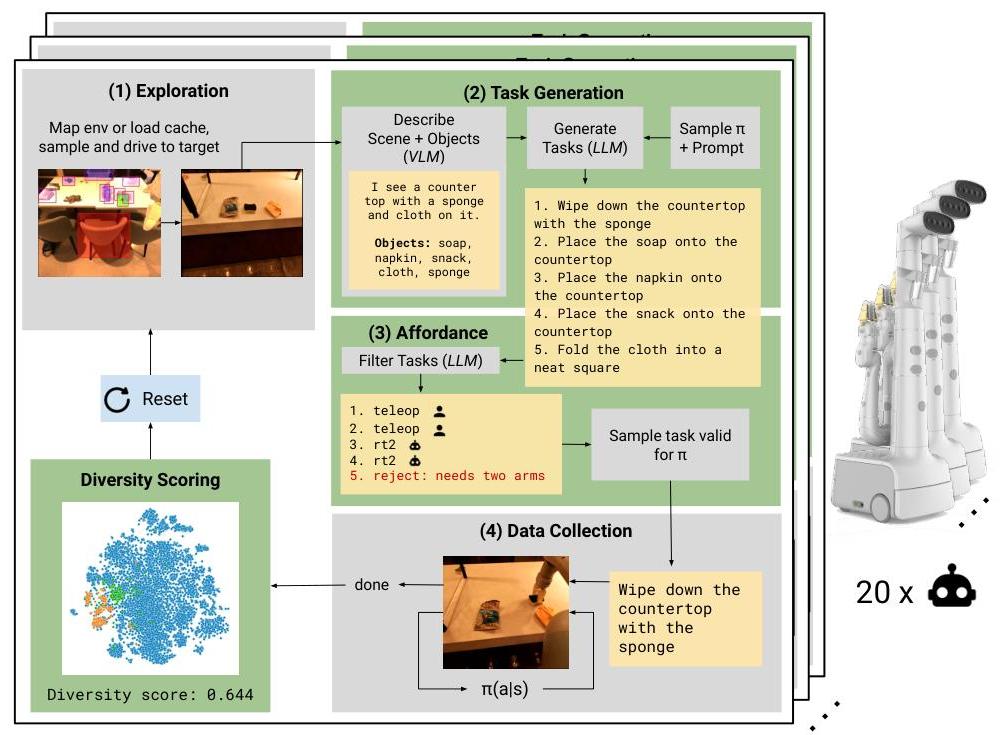
AutoRT operates through a four-stage pipeline:
- Exploration: Robots autonomously navigate using natural language maps built from object detections, sampling targets based on semantic similarity to previously encountered objects
- Task Generation: VLMs analyze camera feeds to generate scene descriptions and identify objects. LLMs (with Robot Constitution constraints) generate diverse manipulation tasks tailored to available policies
- Affordance Filtering: A separate LLM validates proposals against the Robot Constitution and available policies, rejecting unsafe or infeasible tasks (correctly filtering 55% of unsuitable tasks)
- Hybrid Data Collection: Three complementary approaches -- teleoperation (maximum diversity), scripted pick policies (simple autonomous), and RT-2 (learned VLA execution)
The Robot Constitution comprises foundational rules (modified Asimov's laws), safety rules (operational constraints), embodiment rules (physical limitations), and guidance rules (optional human objectives).
Results
| Metric | Value |
|---|---|
| Total episodes collected | 77,000 |
| Unique task instructions | 6,650+ |
| Robots deployed | 53 |
| Buildings | 4 |
| Peak simultaneous robots | 20+ |
| Human:robot supervision ratio | 1:3-5 |
| Safe task rate (adversarial) | 87% (vs. 26% without constitution) |
| LLM task feasibility | 77-83% (vs. 52% template-based) |
Language diversity (measured via embedding distance) exceeded RT-1 baseline (1.100-1.137 vs 1.073). Co-fine-tuning RT-1 on AutoRT data improved picking from different heights (0% to 12.5%) and wiping tasks (10% to 30%).
Limitations
- Task success rates for learned policies remain modest -- the system is better at data collection than at execution
- Constitutional filtering is heuristic and not formally verified for safety guarantees
- Evaluation is primarily open-loop (data quality metrics) rather than closed-loop downstream task performance
- Scaling beyond office environments to unstructured outdoor settings is untested
Connections
- Builds directly on Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control as one of the execution policies in the hybrid collection pipeline
- Related to Self Improving Embodied Foundation Models in addressing the data bottleneck for robot learning, but through orchestrated collection rather than autonomous practice
- The Robot Constitution concept connects to safety alignment work in Foundation Models
- Complements Cosmos World Foundation Model Platform For Physical Ai which addresses data scarcity through synthetic generation rather than real-world collection
- Robotics -- foundational work in scaling real-world robot data