RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Overview
RT-2 is the defining paper for the modern Vision-Language-Action (VLA) paradigm. It demonstrates that large vision-language models (VLMs) pretrained on internet-scale data can be directly fine-tuned for robotic control by representing robot actions as text tokens in the model's output vocabulary. This simple idea -- that actions are just another language to be predicted -- enables the transfer of vast web knowledge (semantic understanding, visual reasoning, common sense) to physical robot manipulation without any architectural modification to the underlying VLM.
The key finding is that this transfer is not just possible but dramatically beneficial: RT-2 nearly doubles performance on tasks requiring semantic reasoning (e.g., "pick up the object that is a fruit" when presented with novel objects) compared to RT-1, which had no web pretraining. The model can perform rudimentary chain-of-thought reasoning about which actions to take, interpret novel visual concepts it never encountered in robot data, and even follow instructions involving abstract concepts like "move the banana to the country that is on the flag."
Built on top of PaLM-E (a 12B-parameter VLM) and PaLI-X (a 55B-parameter VLM), RT-2 establishes the scaling hypothesis for robotics: larger VLMs with more web pretraining produce better robot policies, even with the same amount of robot data. This paper launched a wave of VLA research and directly inspired driving-domain VLAs like Senna, ORION, and DriveMoE.
Key Contributions
- Actions as tokens: Represents robot actions as text strings (e.g., "1 128 91 241 5 101 127") that are tokenized and predicted by the VLM's standard language head, requiring zero architectural changes to accommodate action output
- Web-to-robot knowledge transfer: Demonstrates that semantic knowledge from internet pretraining (object categories, spatial relationships, common sense physics) directly improves robotic manipulation performance on novel objects and concepts
- VLA model class definition: Establishes the Vision-Language-Action model as a new model class where a single model jointly handles vision understanding, language comprehension, and action generation
- Chain-of-thought for robotics: Explores a chain-of-thought-style fine-tuned variant that emits an intermediate natural-language plan before action tokens, showing qualitative evidence that VLA models can combine simple planning text with low-level control
- Scaling laws for robot VLMs: Larger VLM backbones (PaLI-X 55B vs PaLM-E 12B) yield better robot performance even with identical robot training data
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ RT-2 (VLA Model) │
│ PaLM-E (12B) or PaLI-X (55B) backbone │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────────┐ ┌────────────────┐ │
│ │ Camera │ │ Language │ │ Web Data │ │
│ │ Image │ │ Instruction │ │ (VQA, capts) │ │
│ └────┬─────┘ └──────┬───────┘ └───────┬────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Vision-Language Model (VLM) │ │
│ │ Image Encoder ──► Transformer Decoder │ │
│ │ (co-fine-tuned on web + robot data) │ │
│ └──────────────────────┬──────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Text Token Output │ │
│ │ "1 128 91 241 ..." │ │
│ └──────────┬──────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ De-discretize to │ │
│ │ 7-DoF Actions │ │
│ │ (256 bins/dim) │ │
│ └──────────┬──────────┘ │
│ │ │
└─────────────────────────┼───────────────────────────────┘
▼
┌─────────────┐
│ Robot │
│ Control │
└─────────────┘
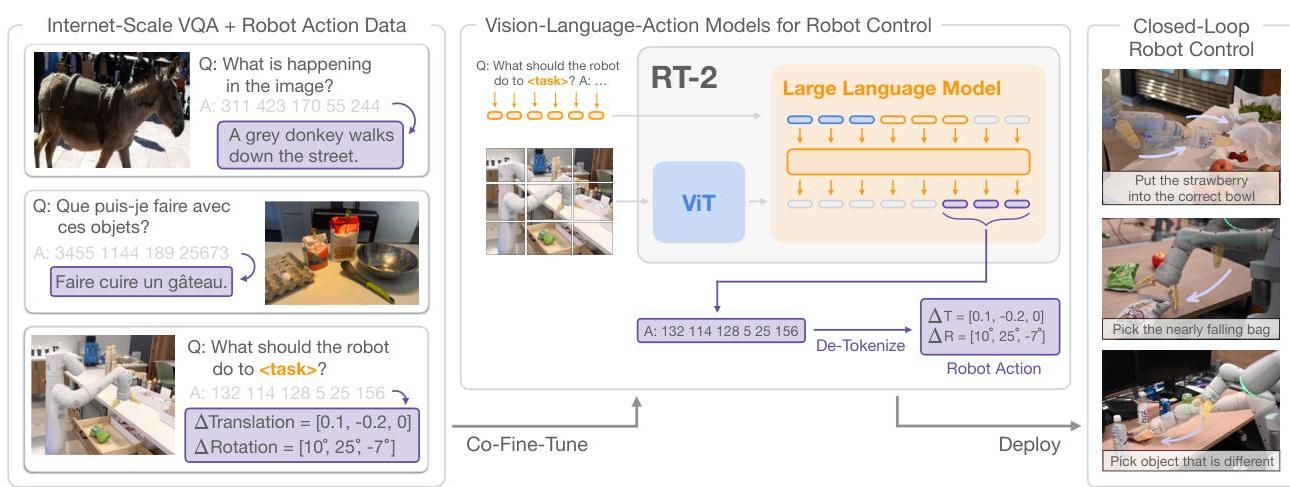
RT-2 takes two existing VLMs -- PaLM-E (12B) and PaLI-X (55B) -- and co-fine-tunes them on a mixture of their original web data and approximately 100,000 robot demonstration episodes from the RT-1 dataset. The robot actions (7-DoF arm + gripper + base + termination = 11 dimensions) are each discretized into 256 bins and represented as integer strings. The action string is appended to the instruction text, and the model is trained with standard next-token prediction loss.
At inference, the model receives a camera image and a natural language instruction, then autoregressively generates text tokens. The output is parsed: if the tokens form valid action integers, they are de-discretized into continuous actions and sent to the robot. If the model outputs regular text (e.g., during chain-of-thought), that text is consumed as reasoning before action tokens are generated.
Co-fine-tuning maintains performance on the original VLM tasks while adding robotic capabilities. The training mixture ratio (web vs robot data) is a key hyperparameter -- too much robot data degrades VLM capabilities, too little limits action quality. The paper finds that a roughly 50/50 mixture works well.
Results
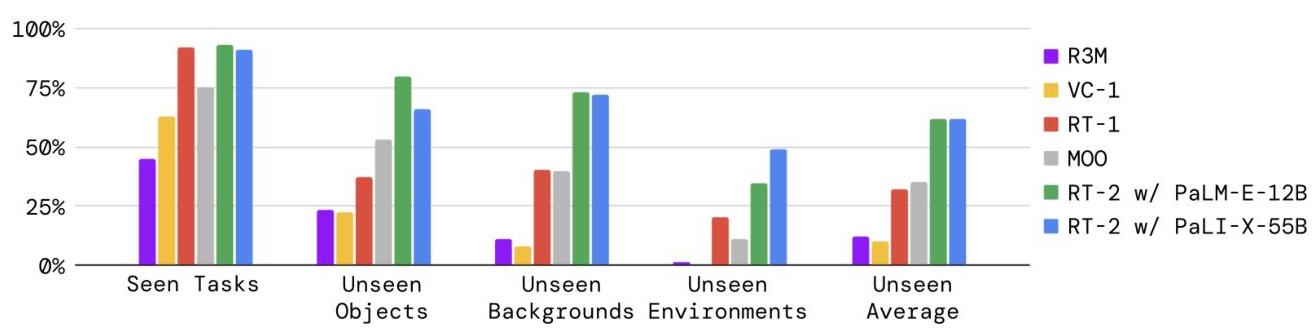
- Emergent semantic generalization: RT-2 achieves 60% average success across emergent evaluation categories (symbol understanding, reasoning, human recognition) versus 20% for RT-1, a 3x improvement. Validated across 6K evaluation trials demonstrating improved generalization to novel objects and environments
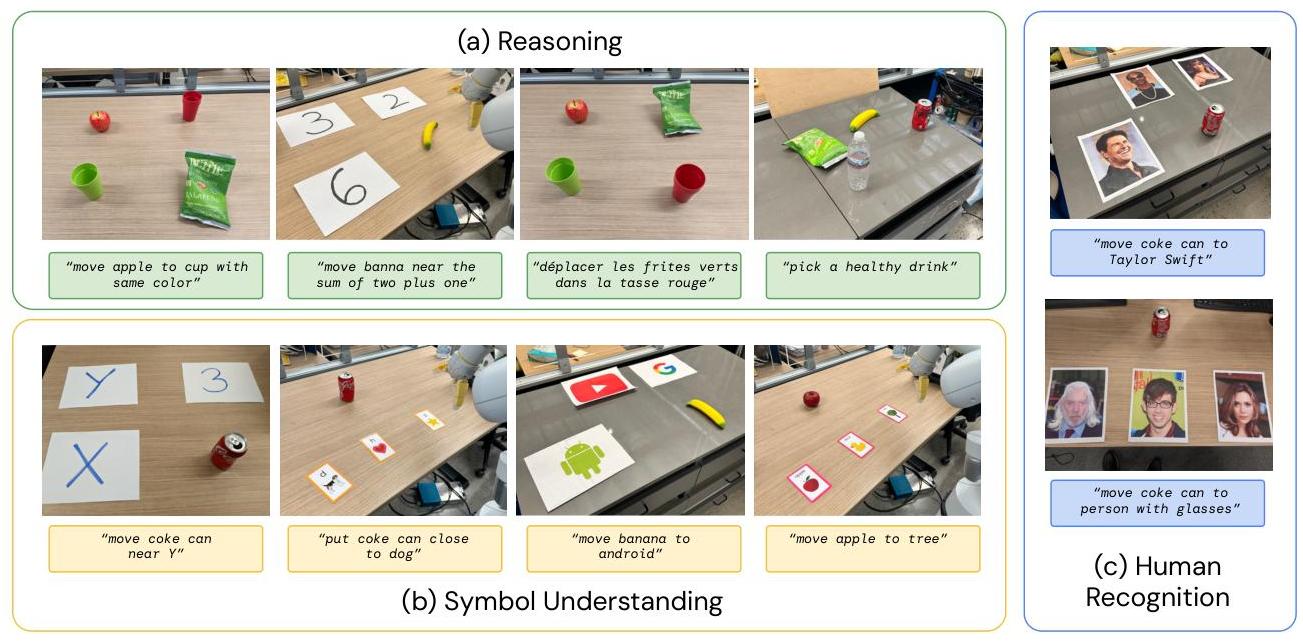
- Symbol understanding: Can interpret visual symbols (e.g., picking the object that matches a flag's country) and perform rudimentary visual reasoning that was never present in robot training data
- Numerical reasoning: Demonstrated emergent abilities like numerical reasoning (e.g., "move object to the position that is the sum of 2+1"), showcasing capabilities well beyond the robot training distribution
- Chain-of-thought-style rollouts: The paper presents qualitative examples of a plan-then-act RT-2 variant, but does not make this a main quantified benchmark gain
- Maintains RT-1 performance on seen tasks: 97% success rate on original RT-1 evaluation tasks, showing that web co-training does not degrade core manipulation skills
- Larger models are better: PaLI-X (55B) outperforms PaLM-E (12B) across all evaluation categories, with the gap largest on semantic generalization tasks
- Performance on emergent evaluation categories (symbol understanding, reasoning, human recognition) averages 60% for RT-2-PaLI-X-55B vs 20% for RT-1, a 3x improvement
Limitations & Open Questions
- The model requires enormous compute for both training and inference (55B parameter model), making real-time deployment on robot hardware challenging without distillation
- Action discretization into 256 bins per dimension limits precision, and the text-token representation adds latency compared to direct continuous action prediction
- The model has no explicit planning or world model -- it remains a reactive policy mapping current observation to next action, limiting performance on tasks requiring multi-step planning
- Generalization is primarily demonstrated on a single robot platform (Everyday Robots) in structured environments; transfer to diverse robot morphologies and unstructured settings remains unvalidated
Connections
- Vision Language Action
- Robotics
- Foundation Models
- Rt 1 Robotics Transformer For Real World Control At Scale
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Drivemoe Mixture Of Experts For Vision Language Action In Autonomous Driving