GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Overview
GR-2 is a generalist robot manipulation agent from ByteDance Research that leverages large-scale video-language pretraining to build a world model for robotic control. The central insight is that web-scale video data (38 million clips) encodes rich physical priors about how the world works -- object interactions, spatial reasoning, dynamics -- and that these priors transfer directly to robot manipulation when the model is fine-tuned on robot-specific data. This addresses a fundamental bottleneck in robotics: the scarcity of robot demonstration data relative to the vast visual and physical knowledge available in internet video.
The architecture is a GPT-style autoregressive transformer that processes a unified token sequence of text, video frames, and robot actions. Training proceeds in two stages: (1) large-scale video-language pretraining on 38M video clips to learn a generative world model capable of predicting future video frames conditioned on text, and (2) robot-specific fine-tuning that integrates a conditional Variational Autoencoder (cVAE) for action generation. The video generation capability serves dual purposes: it provides interpretable action visualization (the model generates prediction videos aligned with real executions) and it encodes the physical priors that make downstream manipulation robust.
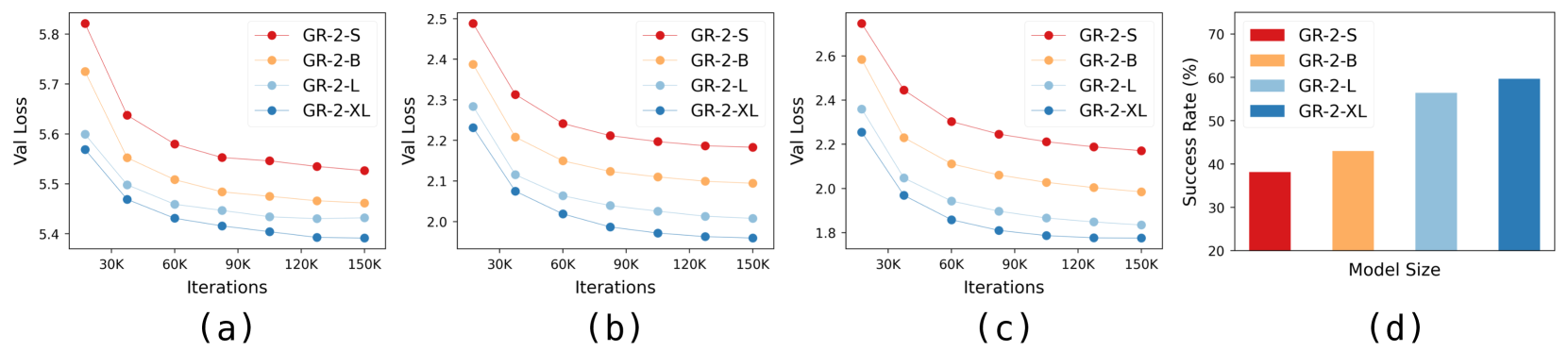
GR-2 achieves a 97.7% success rate across more than 100 tabletop manipulation tasks (with 400 demonstrations per task), 73.9% success with only 50 demonstrations per task, and 79.0% on industrial bin-picking (vs. GR-1's 33.3%). On the CALVIN benchmark, it reaches 98.6% single-task success with an average task completion length of 4.64. Notably, success rates scale monotonically with model size across four evaluated sizes (30M–719M trainable parameters), providing evidence for scaling laws in robotic VLA.
Key Contributions
- Web-scale video pretraining for robotics: Demonstrates that pretraining on 38M internet video clips provides transferable physical priors that dramatically improve robot manipulation, bridging the data gap between web-scale vision and scarce robot demonstrations
- Unified video-language-action architecture: A single GPT-style transformer processes text, video, and action tokens in a shared sequence, enabling joint video prediction and action generation without modality-specific architectural changes
- Conditional VAE for action generation: Integrates a cVAE module during robot fine-tuning to handle the multimodal nature of action distributions, improving over deterministic action prediction
- Scaling evidence for robotic VLA: Shows clear performance scaling across four model sizes (30M–719M trainable parameters), providing among the earliest scaling law evidence for embodied foundation models
- Interpretable video predictions: The model generates high-quality prediction videos that align with real-world executions, providing a built-in interpretability mechanism for robot behavior
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ GR-2: Video-Language-Action Model │
│ │
│ Stage 1: Video-Language Pretraining (38M clips) │
│ ┌────────────┐ ┌────────────┐ ┌──────────────────┐ │
│ │ Text │ │ Video │ │ GPT-Style │ │
│ │ Description│──│ Frames │──│ Autoregressive │ │
│ │ Tokens │ │ (encoded) │ │ Transformer │ │
│ └────────────┘ └────────────┘ │ │ │
│ │ Objective: │ │
│ │ predict future │ │
│ │ video frames │ │
│ └────────┬─────────┘ │
│ │ │
│ Stage 2: Robot Fine-tuning ▼ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Unified Token Sequence │ │
│ │ [text] [video_t] [video_t+1] ... [action] │ │
│ │ │ │
│ │ ┌─────────────────────────────────┐ │ │
│ │ │ Pretrained Transformer │ │ │
│ │ │ (world model backbone) │ │ │
│ │ └───────────────┬─────────────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────────┐ │ │
│ │ │ Conditional VAE (cVAE) │ │ │
│ │ │ ┌─────────┐ ┌────────────┐ │ │ │
│ │ │ │ Encoder │──►│ Latent z │ │ │ │
│ │ │ │(train) │ │ │ │ │ │
│ │ │ └─────────┘ └─────┬──────┘ │ │ │
│ │ │ ▼ │ │ │
│ │ │ ┌────────────┐ │ │ │
│ │ │ │ Decoder │────┼──► Actions │ │
│ │ │ └────────────┘ │ │ │
│ │ └─────────────────────────────────┘ │ │
│ └─────────────────────────────────────────────────┘ │
│ │
│ Scaling: 30M ──► 95M ──► 312M ──► 719M (trainable params) │
└─────────────────────────────────────────────────────────────┘
GR-2 uses a GPT-style autoregressive transformer as its backbone. The model operates over a unified token sequence that interleaves text tokens, visual tokens (from video frames encoded via a vision encoder), and robot action tokens.
Stage 1: Video-Language Pretraining. The model is pretrained on 38 million video clips to predict future video frames conditioned on text descriptions. This stage learns a generative world model that captures physical dynamics, object permanence, spatial relationships, and cause-effect patterns from web-scale data. The video generation objective forces the model to learn structured internal representations of how the physical world evolves.
Stage 2: Robot Fine-tuning with cVAE. The pretrained model is fine-tuned on robot demonstration data. A conditional Variational Autoencoder (cVAE) is integrated to model the multimodal distribution of possible actions given an observation. The cVAE encodes demonstration actions into a latent space during training and samples from this space during inference, allowing the model to capture the inherent ambiguity in manipulation tasks (e.g., multiple valid grasp poses for the same object). The robot's proprioceptive state and action tokens are injected into the transformer's token sequence alongside the visual and language tokens.

The video prediction capability is preserved during fine-tuning: GR-2 can generate prediction videos showing the expected outcome of planned actions, providing a natural interpretability mechanism. These predicted videos align well with actual robot executions.
Results
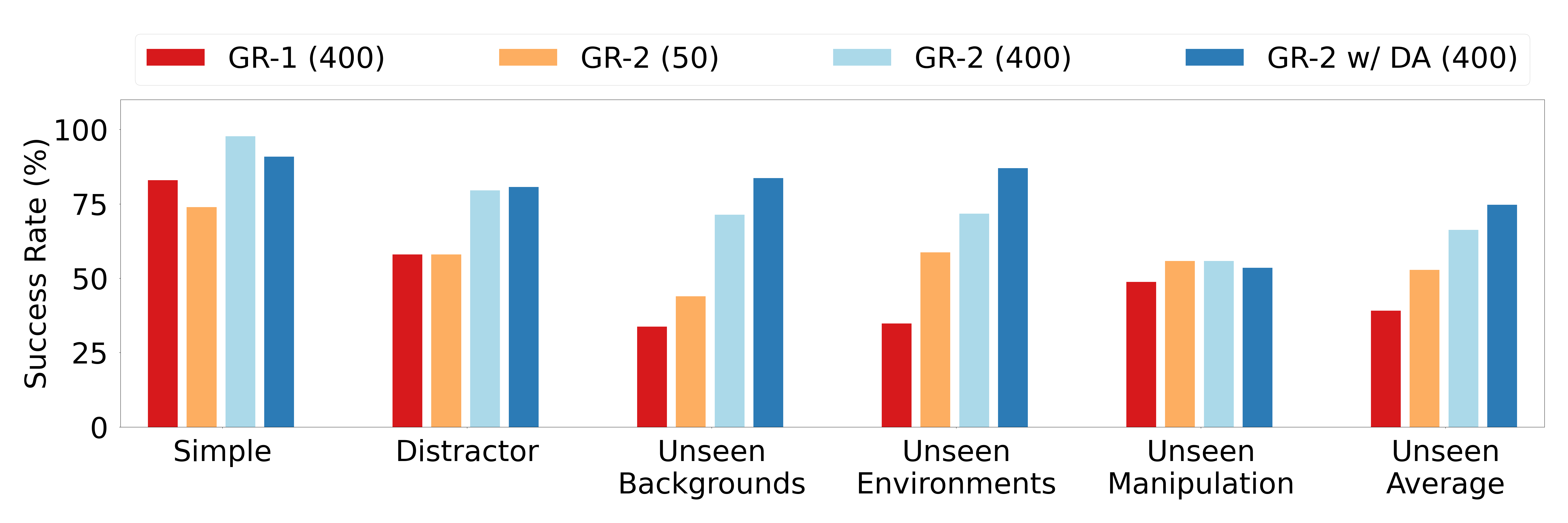
| Setting | Metric | GR-2 | GR-1 | Notes |
|---|---|---|---|---|
| Multi-task tabletop (400 demos/task) | Success rate | 97.7% | -- | 100+ tasks |
| Multi-task tabletop (50 demos/task) | Success rate | 73.9% | -- | Low-data regime |
| Industrial bin-picking | Success rate | 79.0% | 33.3% | 2.4x improvement |
| CALVIN (single-task) | Success rate | 98.6% | -- | Standard benchmark |
| CALVIN (chained) | Avg. task length | 4.64 | -- | Long-horizon |
Scaling behavior:
| Model size (trainable) | Success rate (relative trend) |
|---|---|
| 30M (GR-2-S) | lowest |
| 95M (GR-2-B) | ↑ |
| 312M (GR-2-L) | ↑ |
| 719M (GR-2-XL) | highest |
The paper evaluates four model sizes (30M, 95M, 312M, 719M trainable parameters) and shows monotonically increasing success rate with model size (reported as a figure, not exact numbers per size). This suggests continued scaling may yield further gains, aligning with scaling trends observed in HPT and the broader hypothesis that the language model scaling paradigm transfers to robotics.
Limitations & Open Questions
- Compute cost of video pretraining: Pretraining on 38M video clips requires substantial compute, and the paper does not provide detailed ablations on how much video data is truly necessary for the transfer benefit
- Action space generality: The cVAE action generation is demonstrated primarily on tabletop manipulation and bin-picking; generalization to higher-DoF platforms (humanoids, mobile manipulation) remains unvalidated
- Real-time inference: The paper does not report inference latency; large GPT-style models with video generation may struggle with the real-time requirements of dynamic manipulation
- Video prediction fidelity: While prediction videos align with executions qualitatively, it is unclear how prediction errors compound over longer horizons
- Comparison breadth: Direct comparisons are primarily against GR-1; more extensive benchmarking against RT-2, OpenVLA, or pi0 would better contextualize the results
Connections
Related papers in the wiki:
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 established the VLA paradigm of transferring web knowledge to robot control; GR-2 extends this by using video generation (not just VLM features) as the pretraining objective
- Openvla An Open Source Vision Language Action Model — OpenVLA democratized VLA research at 7B scale; GR-2 explores a complementary scaling axis via video-language pretraining rather than pure VLM fine-tuning
- Pi0 A Vision Language Action Flow Model For General Robot Control — pi0 uses flow matching for action generation on PaliGemma; GR-2 uses a cVAE instead and emphasizes video generation as a world model
- Groot N1 An Open Foundation Model For Generalist Humanoid Robots — GR00T N1 evaluated on GR-1 humanoid hardware; GR-2 provides the video-pretrained backbone that complements such downstream platforms
- Cosmos World Foundation Model Platform For Physical Ai — Cosmos provides world model infrastructure for physical AI; GR-2 demonstrates that video world models can be directly integrated into the robot policy rather than used only for data generation
- Video Prediction Policy A Generalist Robot Policy With Predictive Visual Representations — VPP reinterprets video diffusion as a predictive encoder; GR-2 takes the more direct approach of training a generative video model end-to-end with action prediction
- Hpt Scaling Proprioceptive Visual Learning With Heterogeneous Pre Trained Transformers — HPT provides cross-embodiment scaling laws; GR-2's 1.1B-to-6.8B scaling results complement this with model-size scaling evidence
- Robotics — broader context on the VLA revolution in robotics
- Vision Language Action — the VLA design space and key axes