Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
:page_facing_up: Read on arXiv
Overview
Video Prediction Policy (VPP) by Hu, Guo et al. (ICML 2025 Spotlight) proposes that video diffusion models (VDMs) are not just generators of future frames but also powerful visual encoders whose internal representations encode both current scene understanding and future dynamics prediction. Rather than using VDMs to generate future frames and then planning on them, VPP extracts the predictive visual representations from a single forward pass through a fine-tuned VDM and feeds them into a Diffusion Policy head (Diffusion Transformer) to predict robot actions.
This reinterpretation of video diffusion models as predictive encoders (rather than generators) yields a simple but effective robot policy: fine-tune a video foundation model on robot data, extract internal representations, and learn a lightweight action head. VPP achieves an 18.6% relative improvement on the CALVIN ABC-D generalization benchmark (4.33 vs. prior SOTA of 3.65 from RoboUniview) and a 31.6% success rate increase on complex real-world dexterous manipulation tasks.
Key Contributions
- Video diffusion models as predictive visual encoders: Demonstrates that the internal representations of VDMs inherently encode future dynamics, making them powerful visual backbones for robot policies without requiring explicit future frame generation
- Two-stage training pipeline: Stage 1 fine-tunes a video foundation model on robot datasets + internet human manipulation data; Stage 2 trains a Diffusion Policy action head (Diffusion Transformer) conditioned on the VDM's internal representations
- Generalist robot policy: A single model handles multiple robot embodiments (Franka Panda arm, Xarm dexterous hand) and diverse manipulation tasks with language conditioning
- Strong empirical results: 18.6% relative improvement on CALVIN ABC-D over prior SOTA (RoboUniview, 3.65→4.33), 10.8% relative improvement on MetaWorld over GR-1, 31.6% real-world dexterous improvement
Architecture
┌──────────────────────────────────────────────────────────┐
│ Video Prediction Policy (VPP) │
│ │
│ Stage 1: Fine-tune Video Diffusion Model │
│ ────────────────────────────────────── │
│ Robot demos + Internet manipulation videos │
│ │ │
│ ▼ │
│ ┌────────────────────────────────┐ │
│ │ Video Diffusion Model (SVD) │ │
│ │ (pre-trained, then fine-tuned)│ │
│ └────────────────────────────────┘ │
│ │
│ Stage 2: Extract Representations + Action Head │
│ ────────────────────────────────────────── │
│ Current Observation Language Instruction │
│ │ │ │
│ ▼ │ │
│ ┌────────────────────────┐ │ │
│ │ Fine-tuned VDM │ │ │
│ │ (single forward pass) │◄─┘ │
│ │ │ │
│ │ Internal features ─────┼──► Predictive representations │
│ │ (multi-layer, multi-t) │ (encode future dynamics) │
│ └────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────┐ │
│ │ Diffusion Policy Head │ Diffusion Transformer │
│ │ (trained on demos) │ │
│ └───────────┬────────────┘ │
│ ▼ │
│ Robot Actions (arm joints + gripper) │
└──────────────────────────────────────────────────────────┘
Architecture / Method
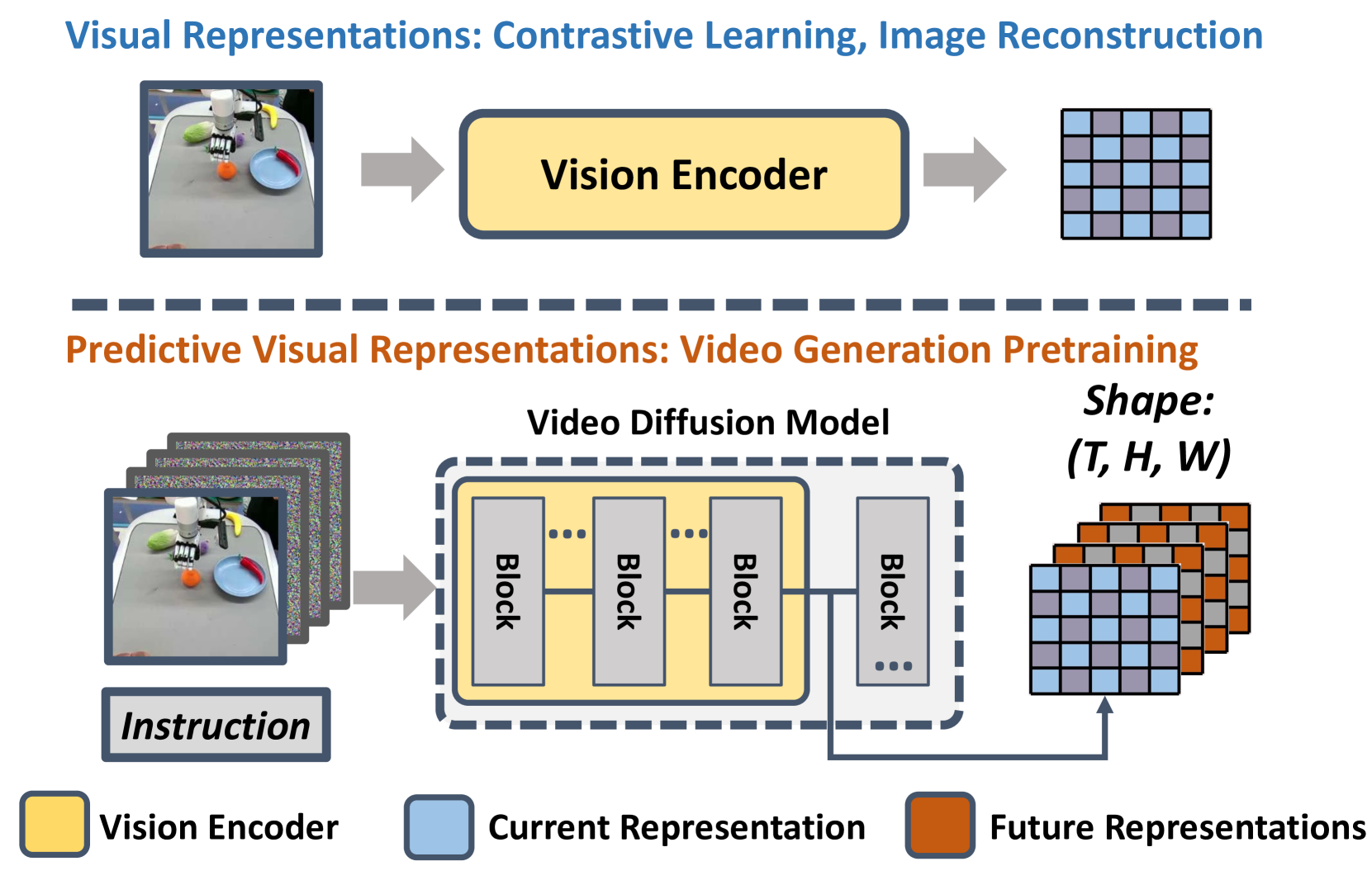
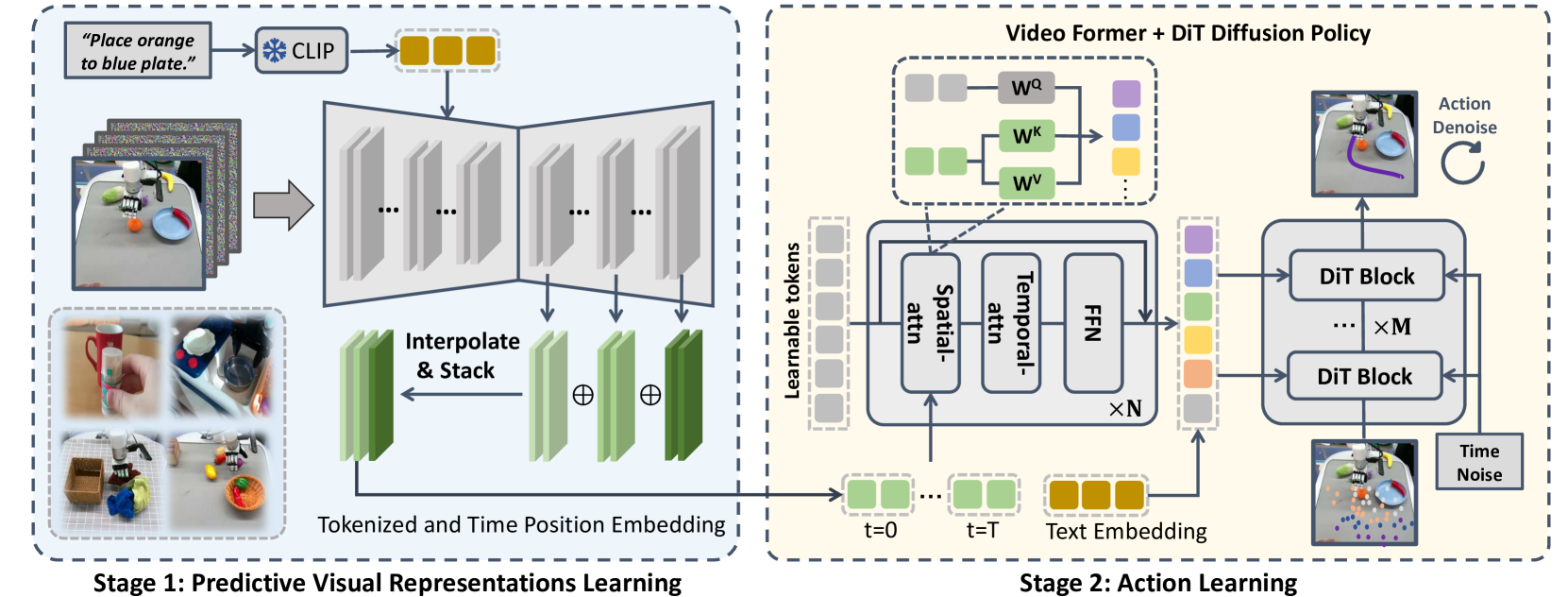
Stage 1 -- Video Foundation Model Fine-tuning: A pre-trained video diffusion model (e.g., based on Stable Video Diffusion) is fine-tuned on a mixture of robot demonstration videos and internet human manipulation videos. The fine-tuning adapts the model's learned visual dynamics to the robot manipulation domain. The key insight is that this fine-tuning process causes the model's internal representations to encode task-relevant dynamics (what will happen next) rather than just static scene features.
Stage 2 -- Diffusion Policy Action Head: Given a current observation, a single forward pass through the fine-tuned VDM produces internal feature representations at multiple up-sampling layers. These representations -- which encode predicted future visual states -- are aggregated and compressed by a Video Former module (learnable query tokens processed through spatial-temporal attention), then fed into a Diffusion Policy head (Diffusion Transformer) that denoises actions conditioned on the compressed representations. The action head is trained on paired (observation, action) data from robot demonstrations.
The critical design choice is using the VDM's internal representations rather than generated frames. Generated frames introduce compounding errors and are expensive to produce; internal representations capture the same predictive information in a compact, differentiable form suitable for policy learning.
Data: Training uses a combination of robot-specific demonstration data and internet-scale human manipulation videos. The internet data provides broad visual understanding of manipulation dynamics, while robot data provides embodiment-specific action labels.

Results
CALVIN ABC-D Benchmark (Language-conditioned)
| Method | Avg. Task Completion (5 tasks) |
|---|---|
| SuSIE | 2.69 |
| GR-1 | 3.06 |
| Vidman | 3.42 |
| RoboUniview | 3.65 |
| VPP | 4.33 (+18.6% over prior SOTA RoboUniview; +41.5% over GR-1) |
MetaWorld Multi-task
| Method | Success Rate |
|---|---|
| GR-1 | 0.574 |
| VPP | 0.682 (+10.8% over GR-1) |
Real-world Dexterous Manipulation (XHand)
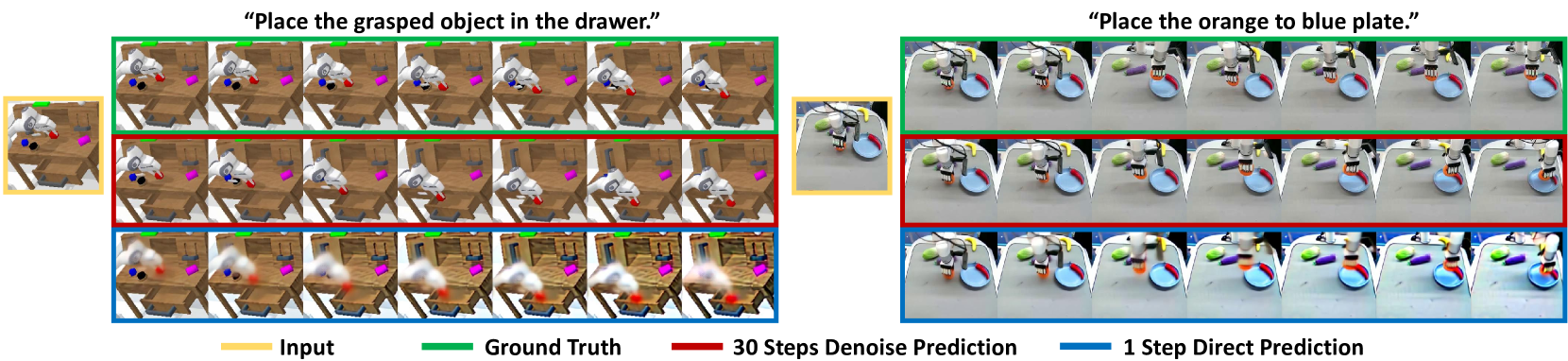
VPP achieves a 31.6% success rate increase over baselines on complex real-world dexterous manipulation tasks with a dexterous hand (Xarm), demonstrating that video diffusion representations transfer effectively to high-DoF control.

Limitations
- Requires fine-tuning a large video diffusion model, which is computationally expensive (Stage 1)
- Action frequency is limited by the forward pass speed of the VDM backbone
- Relies on quality of internet manipulation data for generalization; domain gap between internet videos and robot workspace may limit transfer
- Currently predicts actions via a Diffusion Policy head rather than explicit planning, which may limit long-horizon task performance
Connections
- Extends the VLA paradigm from Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control (web knowledge transfer to robot control) but uses video diffusion instead of VLMs
- Builds on the generalist agent concept from A Generalist Agent (Gato) but with a stronger visual backbone
- Related to Openvla An Open Source Vision Language Action Model as an alternative approach to generalist robot policies
- The video prediction paradigm connects to world models like Cosmos World Foundation Model Platform For Physical Ai which also use generative models for physical AI
- The dual-stage training connects to Helix A Vla For Generalist Humanoid Control which also separates high-level understanding from low-level control
- Self-improvement connections to Self Improving Embodied Foundation Models which addresses robot policy improvement