Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation (GR-1)
Overview
GR-1 addresses a fundamental bottleneck in robot learning: the scarcity of diverse, high-quality robot demonstration data. The key insight is that robot trajectories are fundamentally video sequences, and the ability to predict future visual states from past observations and language instructions can serve as a powerful foundation for learning robot policies. Rather than training exclusively on expensive robot data, GR-1 leverages large-scale human egocentric video (Ego4D) to pre-train a generative video model, then fine-tunes on robot data for manipulation control.
The approach follows a two-phase training paradigm inspired by the generative pre-training success of GPT-style models in NLP. In Phase 1, a GPT-style transformer is pre-trained on approximately 800,000 video clips from the Ego4D dataset to learn video prediction conditioned on language descriptions. In Phase 2, the model is fine-tuned on robot manipulation data, where it jointly predicts future video frames and robot actions. This joint video-action prediction is critical -- the video prediction objective acts as an auxiliary loss that regularizes the policy and transfers visual dynamics understanding from pre-training.
GR-1 achieves strong results on the CALVIN benchmark, reaching 94.9% success rate on multi-task learning (vs. 88.9% for HULC) and 85.4% on zero-shot generalization to unseen scenes (vs. 53.3% for RT-1). On real robot experiments, GR-1 reaches 79% success on seen object transportation (vs. 27% for RT-1). The work from ByteDance Research demonstrates that cross-domain transfer from non-robotics video data to robot control is not only feasible but highly effective, particularly for data efficiency and generalization.
Key Contributions
- Video generative pre-training for robotics: Demonstrates that pre-training on large-scale human egocentric video (Ego4D, 800K clips) transfers effectively to robot manipulation, establishing a new paradigm for addressing robot data scarcity
- Unified video-action architecture: A single GPT-style transformer jointly predicts future video frames and robot actions using learnable
[ACT]and[OBS]tokens, with strategic temporal masking to maintain autoregressive properties - Frozen encoder strategy: Preserves pre-learned visual representations by freezing the image encoder during robot fine-tuning, preventing catastrophic forgetting of video understanding
- Strong zero-shot and data-efficient generalization: Achieves 85.4% success on unseen CALVIN scenes and 77.8% with only 10% of training data, demonstrating that video pre-training provides robust priors for generalization
Architecture
┌──────────────────────────────────────────────────────────┐
│ GR-1 Architecture │
│ │
│ Phase 1: Video Generative Pre-training (Ego4D, 800K) │
│ ───────────────────────────────────────────────────── │
│ Language l Observations o_{t-h:t} │
│ │ │ │
│ ▼ ▼ │
│ ┌──────┐ ┌───────────┐ │
│ │ Text │ │ Frozen ViT│ │
│ │Encoder│ │ Encoder │ │
│ └──┬───┘ └─────┬─────┘ │
│ │ [OBS] │ [OBS] │
│ └──────┼───────┼──────┤ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────┐ │
│ │ GPT-style Transformer │ │
│ │ (causal attention) │ │
│ └──────────┬───────────────┘ │
│ ▼ │
│ Predicted o_{t+1} │
│ │
│ Phase 2: Robot Fine-tuning │
│ ───────────────────────────────────────────────────── │
│ Language Observations Proprio s_{t-h:t} │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────┐ ┌────────┐ ┌─────────┐ │
│ │ Text │ │Frozen │ │ MLP │ │
│ │Encoder│ │ ViT │ │Projector│ │
│ └──┬───┘ └───┬────┘ └────┬────┘ │
│ │ [OBS] │ [ACT] │ │
│ └────┼─────┼────┼─────────┘ │
│ ▼ ▼ ▼ │
│ ┌──────────────────────────┐ │
│ │ GPT-style Transformer │ │
│ └──────┬──────────┬────────┘ │
│ ▼ ▼ │
│ o_{t+1} a_t (arm + gripper) │
└──────────────────────────────────────────────────────────┘
Architecture / Method
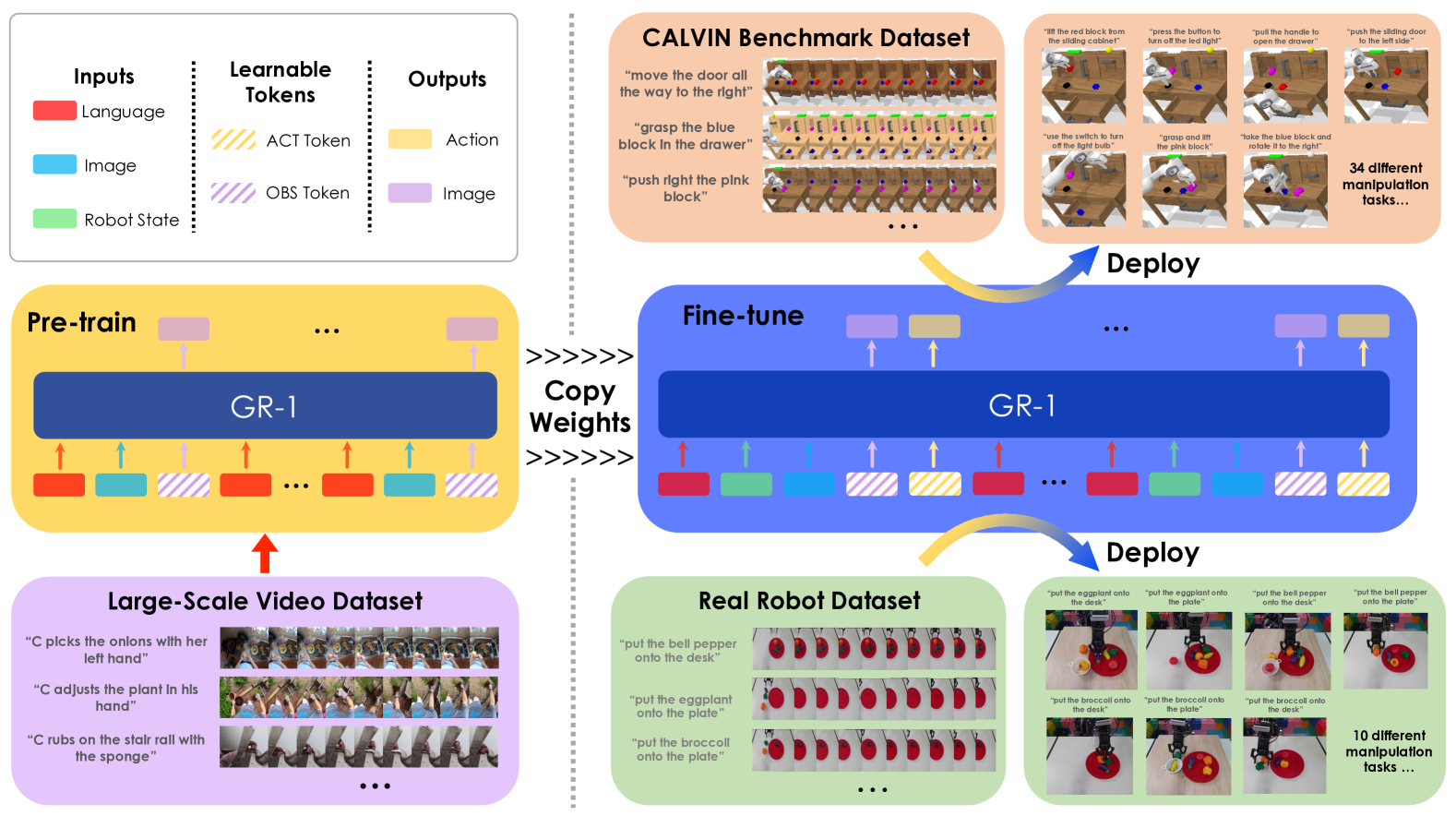
GR-1 uses a unified GPT-style transformer architecture with specialized encoders for multiple input modalities. The model processes sequences of visual observations, language instructions, and robot states to predict both future video frames and robot actions.
Input processing: Visual observations are encoded by a frozen MAE-pretrained ViT image encoder (global CLS token + patch tokens via Perceiver Resampler). Language instructions are encoded by a frozen CLIP text encoder. Robot proprioceptive states (6D end-effector pose and binary gripper state) are projected through linear layers. The architecture introduces two types of learnable tokens: [ACT] tokens for action prediction and [OBS] tokens for future image prediction, which are interleaved into the input sequence.
Phase 1 -- Video Generative Pre-training: The model learns to predict future frames conditioned on past observations and language instructions:
$$\pi(l, o_{t-h:t}) \rightarrow o_{t+\Delta t}$$
This is trained on ~800K Ego4D video clips with paired text descriptions. The model learns visual dynamics, object interactions, and the relationship between language descriptions and visual outcomes.
Phase 2 -- Robot Fine-tuning: The model is adapted for robot control by adding proprioceptive state inputs and action prediction:
$$\pi(l, o_{t-h:t}, s_{t-h:t}) \rightarrow o_{t+\Delta t}, a_t$$
The combined fine-tuning loss is:
$$L_{\text{finetune}} = L_{\text{arm}} + L_{\text{gripper}} + L_{\text{video}}$$
where $L_{\text{arm}}$ is Smooth-L1 loss on arm joint actions (delta XYZ + delta Euler angles), $L_{\text{gripper}}$ is binary cross-entropy on gripper open/close, and $L_{\text{video}}$ is MSE loss on reconstructed image pixels (analogous to MAE reconstruction), which serves as an auxiliary regularizer. Strategic masking during training maintains the autoregressive property of the transformer, ensuring that predictions at each timestep only attend to past context.
Results

CALVIN Benchmark
| Setting | GR-1 | HULC | RT-1 |
|---|---|---|---|
| Multi-task learning | 94.9% | 88.9% | -- |
| Zero-shot (unseen scenes) | 85.4% | -- | 53.3% |
| 10% training data | 77.8% | 66.8% | -- |
| Language generalization (GPT-4 instructions) | 76.4% | 71.5% | -- |
GR-1 achieves state-of-the-art results across all CALVIN evaluation settings. The zero-shot generalization result (85.4% vs. 53.3% for RT-1) is particularly significant, demonstrating that video pre-training provides robust visual priors that transfer across scenes. The data efficiency result (77.8% with only 10% of data) suggests that video pre-training substantially reduces the need for robot demonstrations.
Real Robot Experiments

| Task | GR-1 | RT-1 |
|---|---|---|
| Object transportation (seen) | 79% | 27% |
| Unseen object instances | 73% | -- |
| Unseen object categories | 30% | -- |
| Articulated object manipulation | 75% | -- |
Real robot results confirm that the benefits of video pre-training extend beyond simulation. The 79% vs. 27% gap on seen object transportation demonstrates that GR-1's learned visual dynamics provide substantially better manipulation policies than training on robot data alone.
Limitations & Open Questions
- Limited to tabletop manipulation: Evaluated only on single-arm manipulation tasks; unclear how the approach scales to mobile manipulation, locomotion, or multi-arm coordination
- Ego4D domain gap: Human egocentric video differs from robot camera perspectives in viewpoint, embodiment, and interaction dynamics. The extent of negative transfer from domain mismatch is not fully characterized
- Unseen category generalization is modest: 30% success on unseen object categories suggests that category-level generalization remains a significant challenge despite video pre-training
- Video prediction quality vs. action quality: The relationship between video prediction fidelity and downstream manipulation success is not ablated in detail -- it is unclear whether better video prediction always yields better actions
- Scaling behavior: The paper uses a single model scale. Whether the video pre-training benefit increases with model size (analogous to LLM scaling laws) remains unexplored
Connections
Related papers in the wiki: - Rt 1 Robotics Transformer For Real World Control At Scale -- RT-1 is a primary baseline; GR-1 substantially outperforms it on zero-shot generalization (85.4% vs. 53.3%) - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 transfers web knowledge via VLM fine-tuning; GR-1 transfers via video generative pre-training, a complementary approach - Palm E An Embodied Multimodal Language Model -- PaLM-E uses LLM-scale pretraining for embodied reasoning; GR-1 uses video prediction pretraining instead - Openvla An Open Source Vision Language Action Model -- OpenVLA democratized VLA research; GR-1 predates it and shows that video prediction is an alternative to language-based action modeling - Video Prediction Policy A Generalist Robot Policy With Predictive Visual Representations -- Related approach using video prediction for robot policy learning - Groot N1 An Open Foundation Model For Generalist Humanoid Robots -- GR00T N1 (NVIDIA) extends generalist robot control to humanoids, evaluated on GR-1 benchmark tasks - Cosmos World Foundation Model Platform For Physical Ai -- Cosmos addresses data scarcity through world model video generation, complementary to GR-1's video prediction approach - Robotics -- GR-1 is a key paper in the VLA revolution in robotics - Vision Language Action -- GR-1 demonstrates the video-prediction path to VLA, distinct from the language-token path (RT-2/EMMA)