RT-1: Robotics Transformer for Real-World Control at Scale
Overview
RT-1 is a landmark paper from Google/Everyday Robots demonstrating that a 35M-parameter Transformer model, trained on a large and diverse dataset of real-robot demonstrations, can learn robust policies that generalize across hundreds of manipulation tasks. The key insight is that robotics has a data problem more than an architecture problem: by collecting 130k demonstrations across 700+ tasks on a fleet of mobile manipulators, a relatively simple model achieves 97% success rate on seen tasks and 76% on novel task-object combinations, far exceeding prior specialist approaches.
The paper established the paradigm of "scaling robot data" as the primary lever for improving robot generalization, directly paralleling the scaling insights from NLP. Rather than engineering task-specific modules or reward functions, RT-1 treats robot control as a sequence modeling problem: given a language instruction and camera images, the model outputs discretized action tokens autoregressively. This formulation naturally handles multi-task learning and enables transfer across task categories.
RT-1 became the foundation upon which RT-2 was built, demonstrating that the same architecture could absorb web-scale vision-language pretraining. Together they define the modern VLA (Vision-Language-Action) paradigm for robotics. The paper's contribution is as much about the data collection infrastructure and evaluation methodology as it is about the model architecture itself.
Key Contributions
- Large-scale real-robot dataset: 130,000+ demonstrations across 700+ tasks collected on a fleet of 13 Everyday Robots mobile manipulators over 17 months, establishing the first dataset of this scale for real-world manipulation
- Tokenized action space: Discretizes continuous robot actions (7-DoF arm + base movement + gripper) into 256 bins per dimension, enabling autoregressive token prediction with a standard Transformer decoder
- FiLM-conditioned EfficientNet backbone: Uses FiLM (Feature-wise Linear Modulation) to condition visual features on the language instruction embedding from Universal Sentence Encoder, efficiently fusing language and vision
- TokenLearner compression: Applies TokenLearner to reduce the number of visual tokens before the Transformer, dramatically cutting inference time to achieve real-time control (3Hz) on a physical robot
- Systematic generalization evaluation: Introduces a rigorous evaluation framework testing generalization across unseen object-task combinations, backgrounds, and distractor environments
Architecture
Language Instruction 6 RGB Images (history @ 3Hz)
│ │
▼ ▼ (per image)
┌───────────────────┐ ┌─────────────────────┐
│ Universal Sentence│ │ EfficientNet-B3 │
│ Encoder │──FiLM──►│ (FiLM-conditioned │
│ → fixed embedding │ layers │ on language emb) │
└───────────────────┘ └──────────┬──────────┘
│
▼
┌─────────────────────┐
│ TokenLearner │
│ 81 tokens → 8 │
│ (per image) │
└──────────┬──────────┘
│
8 × 6 = 48 tokens
│
▼
┌─────────────────────┐
│ Decoder-Only │
│ Transformer │
│ (8 layers, 8 heads │
│ 512-dim) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ 11 Action Tokens │
│ (7 arm + 3 base │
│ + 1 gripper) │
│ 256 bins each │
└─────────────────────┘
│
@ 3Hz on robot
Method

RT-1 takes as input a natural language instruction and a history of 6 RGB images (at 3Hz). Each image is processed by an EfficientNet-B3 backbone conditioned on the language instruction via FiLM layers. The language instruction is encoded by Universal Sentence Encoder to produce a fixed embedding that modulates the convolutional features at each EfficientNet block.
The resulting spatial feature maps are passed through TokenLearner, which learns to select and compress the spatial tokens from ~81 per image down to 8 tokens, yielding 48 tokens total for the 6-image history. These tokens are fed into a decoder-only Transformer (8 layers, 8 heads, 512-dim) that autoregressively predicts 11 action tokens: 7 for arm joint velocities, 3 for base velocity (x, y, yaw), and 1 for gripper open/close. Each action dimension is discretized into 256 uniform bins.
Training uses a standard cross-entropy loss on the action tokens. At inference, actions are decoded greedily and executed on the robot at 3Hz. The model runs entirely on-robot using a TPU accelerator.
Results
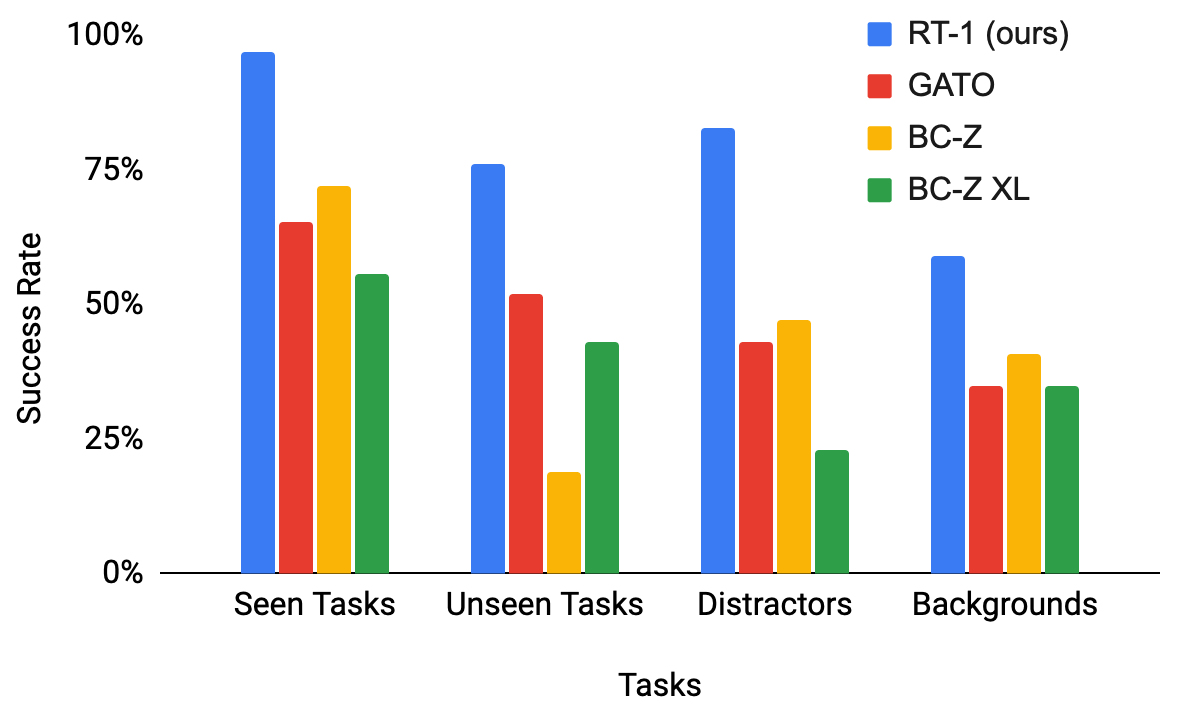
Core Performance Comparison
| Evaluation | RT-1 | BC-Z | Gato |
|---|---|---|---|
| Seen Tasks | 97% | 72% | 65% |
| Unseen Tasks | 76% | 18% | 52% |
| With Distractors | 83% | 47% | - |
| Changed Backgrounds | 59% | 41% | - |
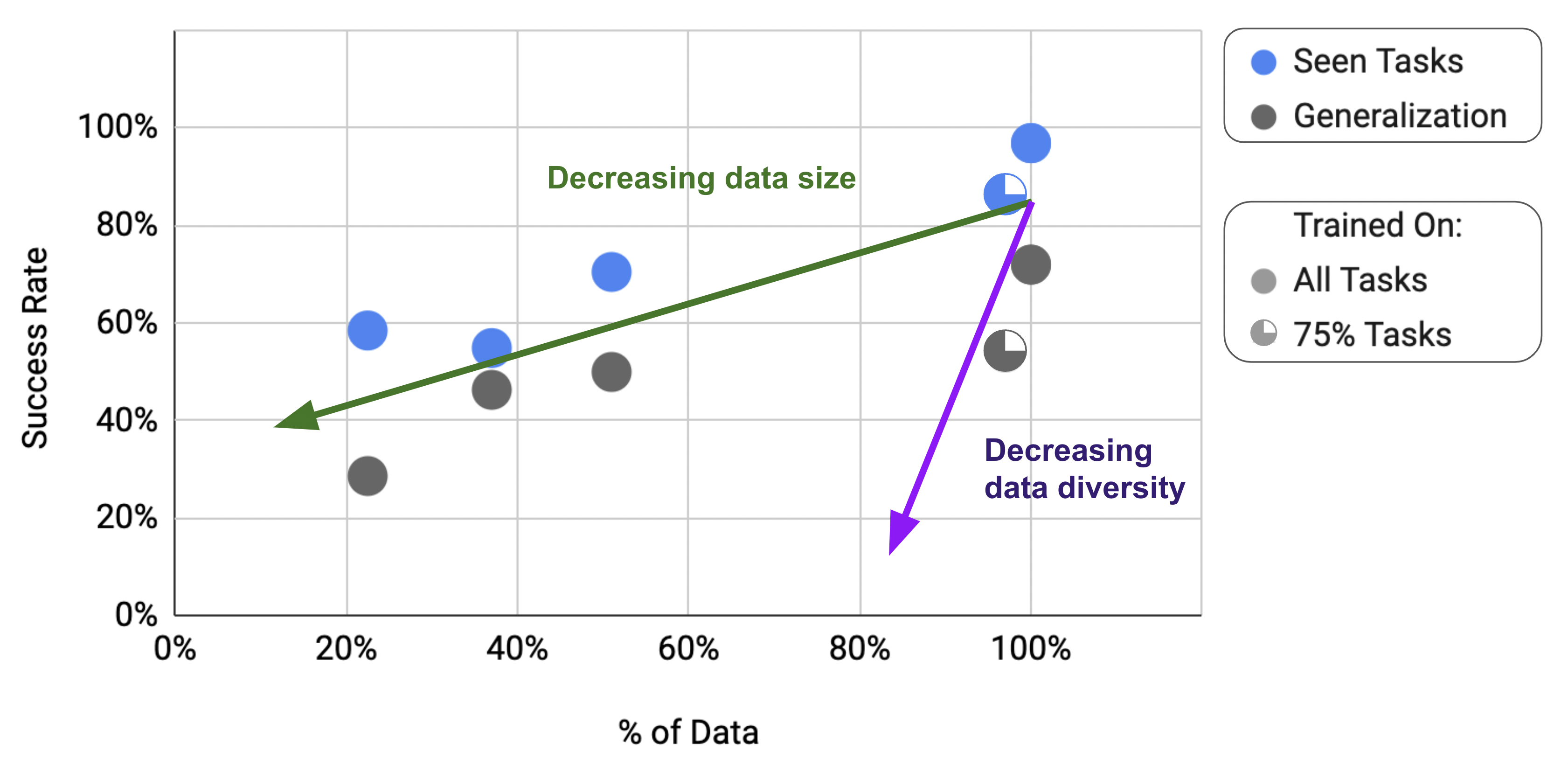
Data Diversity vs. Quantity
| Condition | Unseen Task Performance |
|---|---|
| Full dataset | 76% |
| 25% tasks removed (97% data retained) | 54% |
| 50% data removed (full task diversity) | 50% |
- 97% success rate on 200 seen tasks in controlled evaluation, demonstrating robust multi-task learning across a wide variety of manipulation skills (picking, placing, opening drawers, etc.)
- 76% success rate on novel task-object combinations not seen during training, showing meaningful compositional generalization (e.g., "pick up the unseen object" when the object category was seen with different verbs)
- Outperforms Gato and BC-Z baselines significantly on both seen and unseen tasks, with Gato achieving only 65% on seen tasks despite being a much larger generalist model
- Robustness to distractors and backgrounds: 83% success rate with distractors present, 36 percentage points higher than the BC-Z baseline; performance degrades gracefully (to ~70-80%) when tested in new kitchen environments with different lighting, backgrounds, and distractor objects
- Simulation and cross-morphology data integration: Effectively incorporates 518K simulated trajectories and data from different robot morphologies to boost generalization
- Environment transfer: Maintains 67% performance consistency across drastically different environments
- Real-time inference: TokenLearner compression enables 3Hz control loop on robot hardware, critical for practical deployment
- Data diversity matters more than data quantity: Ablations show that increasing task diversity improves generalization more than simply collecting more demonstrations of existing tasks
Limitations & Open Questions
- The action space discretization (256 bins) limits precision for fine manipulation tasks requiring sub-millimeter accuracy
- The model requires a massive real-robot data collection effort (17 months, 13 robots) that is infeasible for most research groups, raising questions about data efficiency
- Language conditioning via Universal Sentence Encoder limits instruction understanding compared to large language models -- the model cannot follow complex multi-step or compositional instructions
- No explicit state estimation, memory, or planning -- the model is purely reactive, mapping the current observation window to the immediate next action without look-ahead