LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Overview
LLARVA addresses the "embodiment gap" between large multimodal models (LMMs) and robotic control. While VLMs trained on internet-scale data excel at visual understanding and reasoning, they struggle to produce precise, low-level robot actions because their training data contains no embodied control signals. LLARVA bridges this gap by adapting open-source LMMs through structured instruction tuning that pairs visual observations with structured prompts containing robot type, control mode, task description, and proprioceptive state.
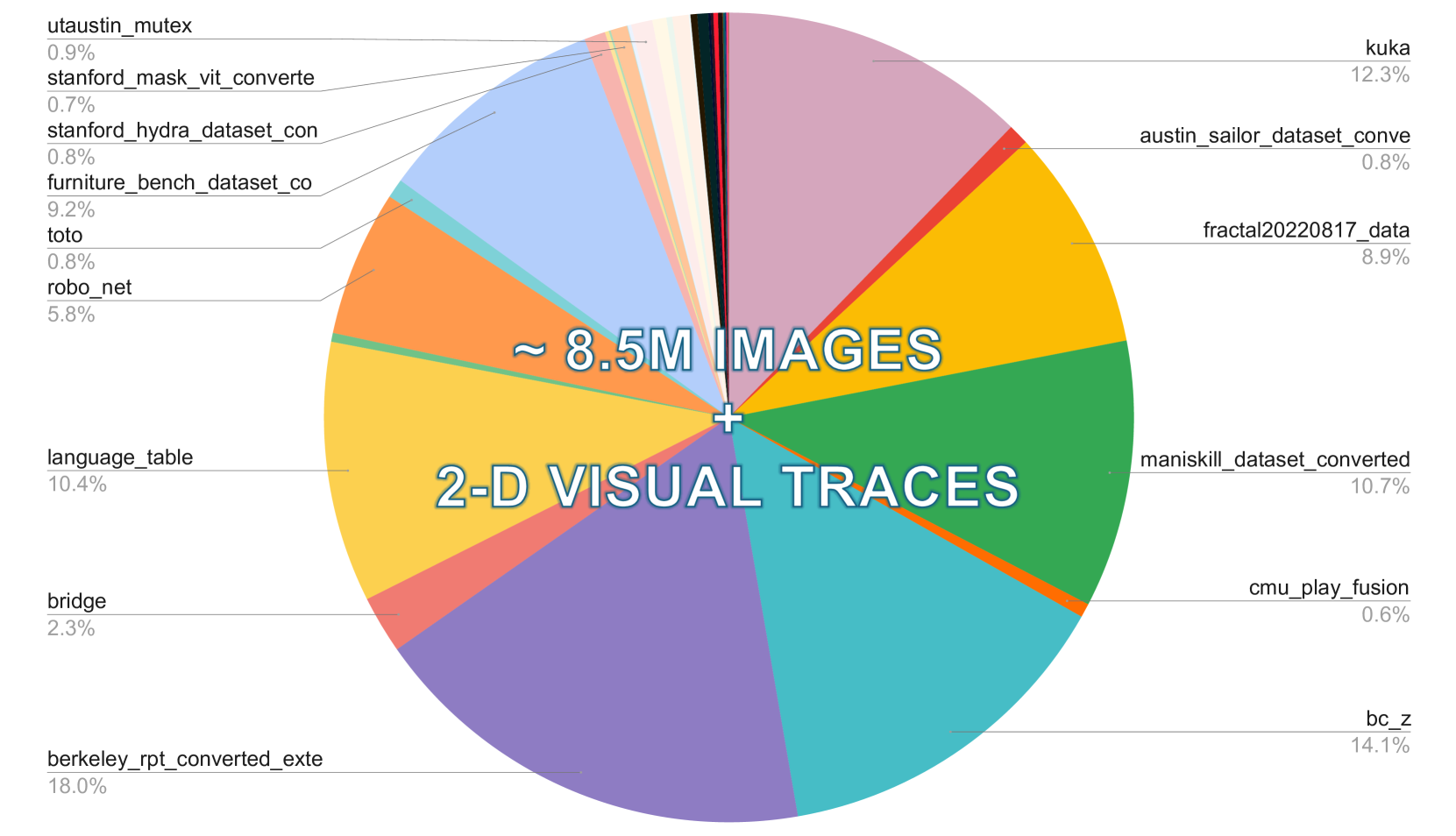
The core insight is that 2D visual traces -- projected end-effector trajectories overlaid on camera images -- serve as an interpretable intermediate representation that bridges the gap between vision and action. By training the model to jointly predict these visual traces alongside robot actions, LLARVA forces the LMM to develop a grounded spatial understanding of how actions manifest visually. The model is trained on approximately 8.5 million image-visual trace pairs from diverse robotic datasets, creating a scalable approach that does not require specialized 3D sensors or per-embodiment engineering.
LLARVA achieves 43.3% average success rate on simulated RLBench tasks, dramatically outperforming a 2D behavioral cloning baseline (1.3%). Instruction pre-training contributes +17.5% and visual traces contribute an additional +15% to performance. Real-robot experiments further demonstrate improved manipulation performance compared to image-only alternatives, validating that the visual trace representation transfers from simulation to physical hardware.
Key Contributions
- Structured instruction format for robotics: A unified prompt schema (robot type, control mode, task, proprioceptive state) that creates a "lingua franca" for robot control across different embodiments and datasets
- 2D visual traces as intermediate representation: Projected end-effector trajectories on camera images that provide interpretable, sensor-agnostic spatial grounding without requiring 3D perception
- Large-scale instruction pre-training pipeline: Training on ~8.5M image-visual trace pairs from diverse robotic datasets, demonstrating that instruction tuning at scale improves downstream robot control
- Ablation evidence for each component: Systematic experiments showing that both instruction pre-training (+17.5%) and visual traces (+15%) independently improve performance
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ LLARVA Pipeline │
│ │
│ ┌──────────────┐ ┌──────────────────────────────────────┐ │
│ │ Camera Image │──►│ Vision Encoder (ViT) │ │
│ │ + Visual Trace│ └──────────────┬───────────────────────┘ │
│ │ (2D proj.) │ │ visual tokens │
│ └──────────────┘ ▼ │
│ ┌─────────────────┐ │
│ ┌──────────────┐ │ LMM Backbone │ │
│ │ Structured │───────►│ (LLaVA-style) │──┬──► Action Head │
│ │ Instruction │ text │ │ │ (EE pose, │
│ │ ┌──────────┐ │ tokens └─────────────────┘ │ gripper) │
│ │ │Robot Type │ │ │ │
│ │ │Ctrl Mode │ │ └──► Visual Trace│
│ │ │Task Desc │ │ Prediction │
│ │ │Proprio. │ │ (2D coords) │
│ │ └──────────┘ │ │
│ └──────────────┘ │
│ │
│ Training: Stage 1 (8.5M pairs pre-train) ──► Stage 2 (finetune)│
└─────────────────────────────────────────────────────────────────┘
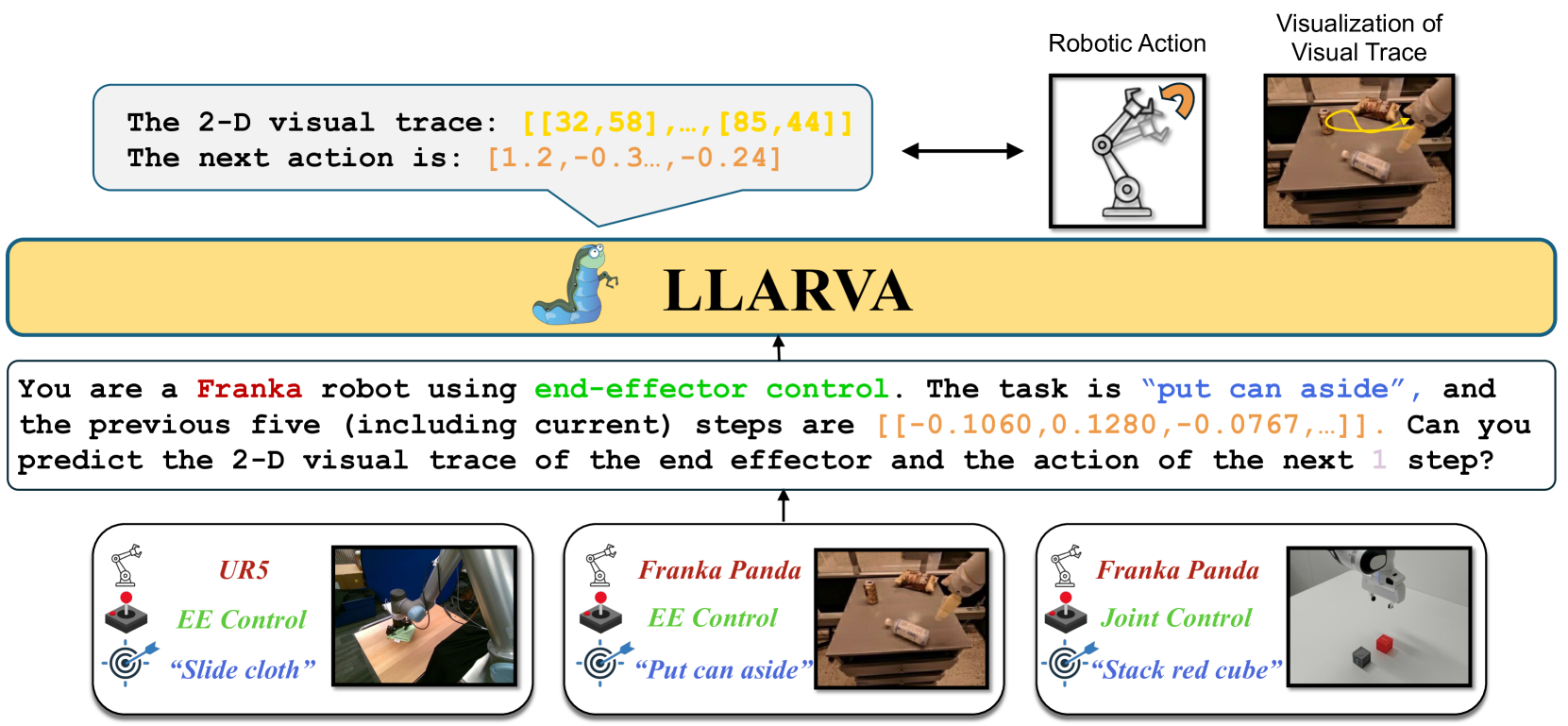
LLARVA builds on an open-source large multimodal model backbone (LLaVA-style architecture). The system processes visual observations through a vision encoder and combines them with structured text prompts through the LMM's language backbone. The key modifications are:
-
Structured instruction encoding: Each training example includes a structured prompt specifying the robot embodiment, control mode (e.g., end-effector position, joint velocities), task description in natural language, and current proprioceptive state. This standardized format allows training across heterogeneous robot datasets.
-
Visual trace generation and prediction: For each demonstration, 2D visual traces are computed by projecting the future end-effector trajectory onto the camera image plane. The model is trained to predict these traces as an auxiliary output, forcing it to develop spatial reasoning about how actions relate to visual observations.
-
Action prediction head: The model outputs robot actions (end-effector poses, gripper commands) conditioned on both the visual input and the structured instruction context.
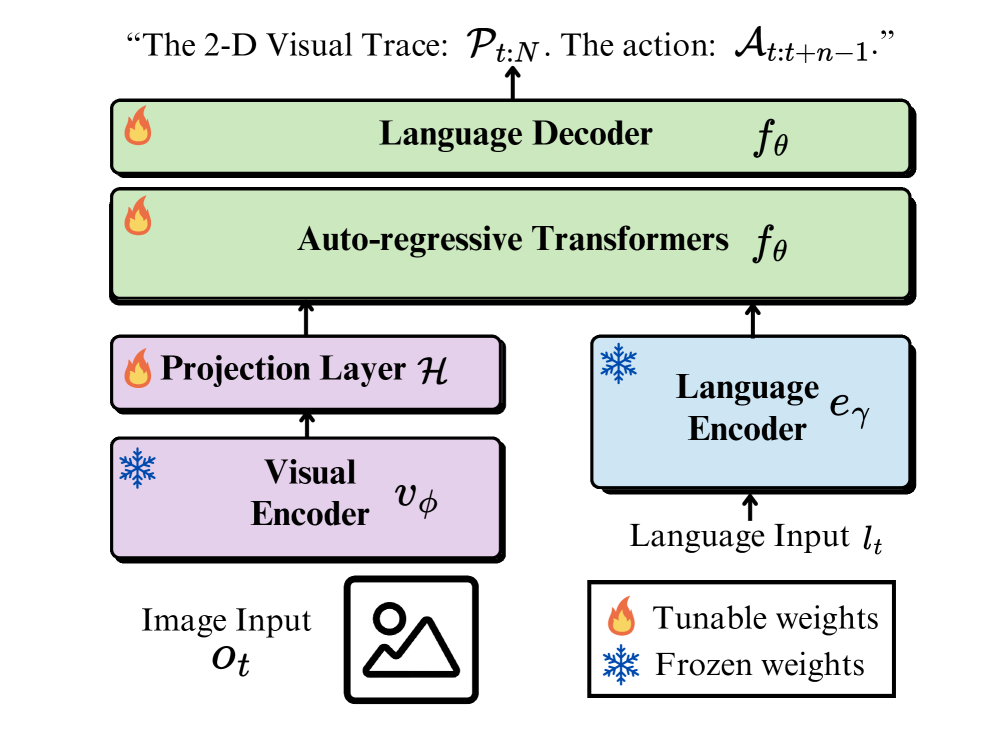
The training proceeds in two stages: (1) large-scale instruction pre-training on the full 8.5M dataset to learn general vision-action correspondences, followed by (2) task-specific fine-tuning on target benchmarks. The visual traces are represented as sequences of 2D pixel coordinates, making them compatible with the language model's token-based output format.

Results
LLARVA demonstrates strong performance on RLBench simulation tasks and real-robot manipulation:
| Method | RLBench Avg. Success (%) | Notes |
|---|---|---|
| LLARVA (full) | 43.3 | Instruction pre-training + visual traces |
| LLARVA (no traces) | ~28 | Instruction pre-training only |
| LLARVA (no pre-training) | ~26 | Visual traces without instruction pre-training |
| 2D Behavioral Cloning | 1.3 | Standard image-conditioned BC |
Key ablation findings: - Instruction pre-training contributes +17.5% absolute improvement, confirming that large-scale multi-dataset training provides useful inductive biases - Visual traces contribute +15% absolute improvement, validating 2D projected trajectories as effective intermediate representations - The two contributions are roughly additive, suggesting they address complementary aspects of the vision-to-action problem

Real-robot experiments confirm that improvements transfer from simulation to physical hardware, with LLARVA outperforming image-based alternatives on manipulation tasks.
Limitations & Open Questions
- Limited 3D reasoning: Using 2D projections necessarily loses depth information; tasks requiring precise 3D spatial reasoning (e.g., stacking, insertion) may benefit from explicit 3D representations
- Single-camera-view processing: The current architecture processes a single camera view, limiting applicability to multi-view robotic setups common in industrial settings
- Scalability for longer-horizon tasks: Performance on extended multi-step manipulation sequences remains to be demonstrated
- Open question: Can visual traces be extended to multi-step planning with intermediate subgoal traces? This connects to chain-of-thought reasoning approaches like ECoT
- Open question: How do 2D visual traces compare to 3D approaches (e.g., VoxPoser's 3D value maps) as the task complexity increases?
Connections
Related papers in the wiki: - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 established the VLA paradigm of fine-tuning VLMs for robotic control; LLARVA offers an alternative via instruction tuning with visual traces rather than direct action token prediction - Openvla An Open Source Vision Language Action Model -- OpenVLA similarly adapts a VLM for robot control on Open X-Embodiment data; LLARVA's structured instruction format and visual traces provide complementary innovations - Palm E An Embodied Multimodal Language Model -- PaLM-E showed LLM-scale models can reason about embodied tasks; LLARVA operates at much smaller scale but with more structured action grounding - Ecot Embodied Chain Of Thought Reasoning For Vision Language Action Models -- ECoT adds chain-of-thought reasoning to VLAs; LLARVA's visual traces provide a complementary form of intermediate representation (spatial rather than linguistic) - Rt 1 Robotics Transformer For Real World Control At Scale -- RT-1 demonstrated large-scale robotic transformer training; LLARVA builds on this data scaling philosophy with instruction tuning - Voxposer Composable 3D Value Maps For Robotic Manipulation With Language Models -- VoxPoser uses 3D value maps for manipulation; LLARVA's 2D visual traces offer a sensor-agnostic alternative that trades depth precision for scalability - Vision Language Action -- LLARVA contributes to the VLA paradigm by showing that instruction tuning with intermediate visual representations can bridge the embodiment gap - Robotics -- Part of the broader trajectory of adapting foundation models for robotic control