PaLM-E: An Embodied Multimodal Language Model
Overview
PaLM-E is a 562-billion parameter embodied multimodal language model created by Google that injects continuous sensor observations (images, point clouds, robot state vectors) directly into the token embedding space of a PaLM large language model, which is fine-tuned end-to-end alongside the input encoders. Rather than converting sensor data to text descriptions before feeding them to an LLM, PaLM-E treats visual and state features as "embodied tokens" that are interleaved with text tokens in the same sequence, enabling the model to ground language understanding in physical sensor data and generate actionable plans for robotic tasks.
The central insight is that a sufficiently large pretrained language model can serve as a general-purpose reasoning backbone for embodied tasks if continuous observations are mapped into its embedding space through learned encoders. PaLM-E demonstrates this across three robot platforms (a mobile manipulator for tabletop tasks, a SayCan kitchen robot, and a simulated manipulation environment) while simultaneously maintaining strong performance on standard vision-language benchmarks (VQA, image captioning, visual reasoning). At the 562B scale, the model exhibits "positive transfer" -- training on robot data actually improves vision-language performance compared to the vision-only baseline.
PaLM-E is significant because it showed that the foundation model paradigm scales to embodied AI: one model can reason about images, answer questions, and plan robot actions. It directly influenced the subsequent wave of VLA models (RT-2, OpenVLA) by establishing that large VLMs can be adapted for action generation without sacrificing language capabilities.
Key Contributions
- Embodied token injection: Continuous sensor inputs (images via ViT, point clouds via PointNet-like encoders, robot state via MLPs) are projected into the same embedding space as text tokens and interleaved in the input sequence, enabling grounded multimodal reasoning
- Scale enables positive transfer: At 562B parameters, training on robotic manipulation data improves VQA and captioning performance compared to the vision-only model, suggesting the embodied grounding helps general visual understanding
- Multi-embodiment generalization: A single model operates across three physically different robots (tabletop manipulator, mobile kitchen robot, simulated arm) by conditioning on embodiment-specific state tokens
- Long-horizon planning via language: PaLM-E generates multi-step plans in natural language (e.g., "1. Pick up the sponge. 2. Move to the sink. 3. Place the sponge in the sink.") grounded in the current visual observation, combining high-level reasoning with perceptual grounding
- Fine-tuned LLM backbone: Both fine-tuning the PaLM language model and keeping it frozen (training only encoders/projections) were explored; fine-tuning yields significantly better results and is the adopted approach in PaLM-E
Architecture / Method
PaLM-E Architecture
───────────────────
Images Point Clouds Robot State Text
│ │ │ │
▼ ▼ ▼ ▼
┌────────┐ ┌───────────┐ ┌──────────┐ ┌──────────┐
│ ViT-22B│ │ OSRT │ │ MLP │ │ Token │
│ Encoder │ │ (3D scene │ │ Encoder │ │ Embed. │
│ │ │ repr.) │ │ │ │ │
└───┬────┘ └─────┬─────┘ └────┬─────┘ └────┬─────┘
│ patch │ │ │
│ tokens │ scene tokens │ state tokens │ text tokens
│ │ │ │
└──────────────┴───────┬───────┴──────────────┘
│ Interleaved "multimodal sentence"
▼
┌──────────────────────────────┐
│ PaLM LLM (fine-tuned) │
│ (8B / 62B / 562B) │
│ │
│ Autoregressive generation │
└──────────────┬───────────────┘
│
┌──────────┴──────────┐
▼ ▼
Plan Steps VQA / Caption
(natural language) (text output)
│
▼
Low-level Skill
Policy Execution
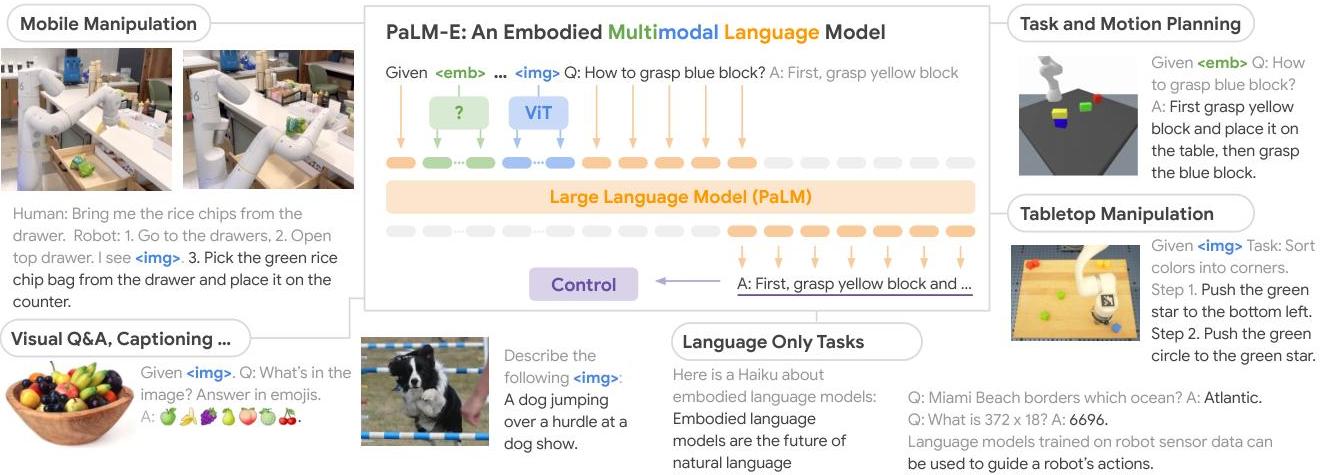
The architecture combines a PaLM language model (available at 8B, 62B, and 562B total scales, corresponding to PaLM backbone sizes of 8B, 62B, and 540B) with modality-specific encoders; the LLM is fine-tuned jointly with the encoders. The unified Transformer architecture creates "multimodal sentences" where text and continuous observations are interleaved as latent vectors. The mathematical encoding maps observations to the embedding space: X = phi(o) in R^d. Multiple encoder types handle different modalities: - ViT-22B for 2D images, producing patch tokens linearly projected into PaLM's embedding dimension - MLPs for state estimation (joint angles, gripper state, end-effector pose) - Object Scene Representation Transformer (OSRT) for 3D scene representations from point clouds
The input to PaLM-E is a sequence like: [image tokens] [text: "Pick up the blue block"] [robot state tokens]. The model autoregressively generates text that either describes the scene (for VQA tasks) or specifies a plan step (for robot tasks). For robotic execution, each generated plan step is dispatched to a low-level skill policy (e.g., a pick-and-place primitive) that executes the action, after which a new observation is captured and fed back to generate the next step.
Training combines multiple task datasets: robot manipulation demonstrations (with language-annotated plans), VQA datasets (VQAv2, OK-VQA), image captioning (COCO), and visual reasoning (Winoground). The multi-task training objective is standard next-token prediction with task-specific prompting. Fine-tuning the full LLM yields better results than freezing it and training only the visual encoders. Model scaling is investigated at 8B, 62B, and 540B PaLM backbone sizes (producing PaLM-E models up to 562B total parameters), with larger models retaining more language capabilities during multimodal training.
The key architectural decision is that all sensor modalities are encoded as "soft tokens" in the LLM's continuous embedding space, rather than being converted to discrete text. This preserves geometric and continuous information that would be lost in text serialization.
Results
| Task / Benchmark | PaLM-E Result | Notes |
|---|---|---|
| VQAv2 | 80.0% | Best generalist (one model) result |
| OK-VQA | SOTA | State-of-the-art at 562B |
| Tabletop manipulation | 94.9% success | Full data mixture |
| TAMP planning | 91.5% success | Single model, multiple task families |
| Single-robot training | 48.6% success | Without multi-task transfer |
- PaLM-E 562B achieves 80.0% on VQAv2 as a single generalist model (without task-specific finetuning) while simultaneously being capable of robotic planning; also achieves state-of-the-art on OK-VQA (66.1%, outperforming task-specifically finetuned models)
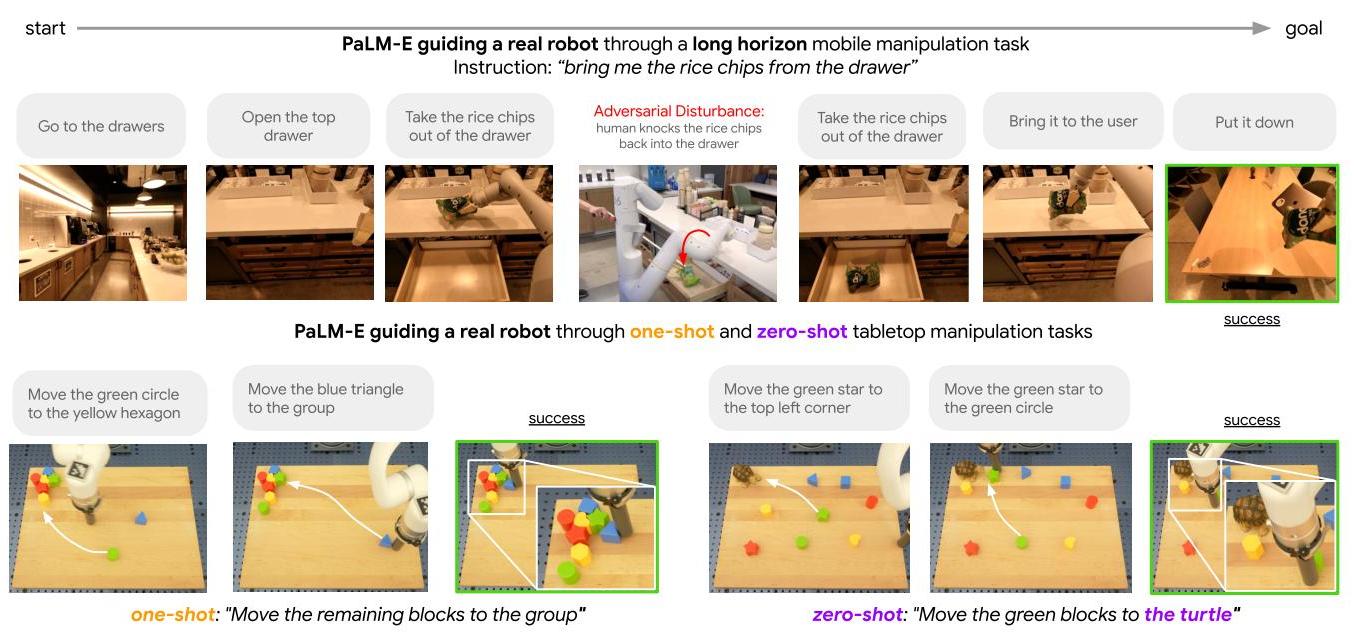
- On tabletop manipulation, PaLM-E achieves 94.9% success rate with the full data mixture, demonstrating efficient data utilization through vision-language transfer and positive transfer across embodiments
- On the TAMP (Task and Motion Planning) robot benchmark, PaLM-E achieves 91.5% planning success rate with a single model across multiple task families
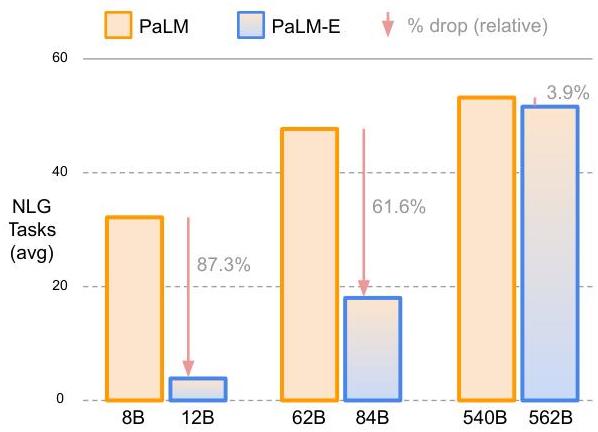
- Positive transfer is observed only at the 562B scale; at 8B and 62B, adding robot data slightly hurts VQA performance, suggesting a scale threshold for beneficial multi-task transfer
- On SayCan kitchen tasks, PaLM-E generates feasible long-horizon plans (4-8 steps) from a single image observation, outperforming SayCan's original language-only planning by grounding decisions in visual state
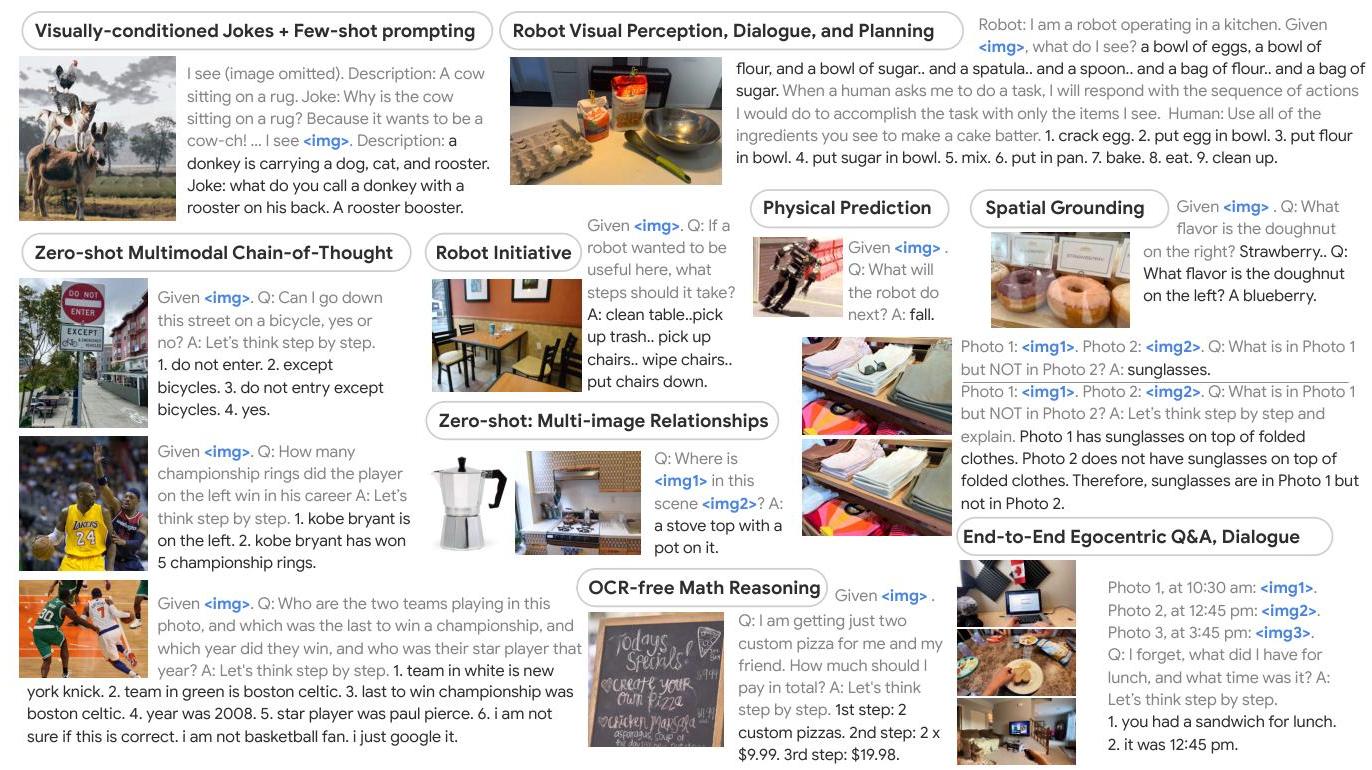
- Emergent capabilities: Multimodal chain-of-thought reasoning, few-shot task adaptation, multi-image relationship analysis, OCR-free mathematical reasoning, spatial relationship understanding, and complex multi-step reasoning with robust embodied planning including disturbance recovery -- none explicitly trained for
Limitations & Open Questions
- The 562B parameter model is impractical for real-time robotics deployment; the positive transfer results at scale raise the question of whether smaller, distilled models can retain these capabilities (partially answered by RT-2 and OpenVLA)
- The model generates plans as text, which are then executed by separate low-level policies; it does not directly output continuous actions, creating a gap between reasoning and execution that later VLAs aim to close
- Evaluation is primarily on tabletop manipulation and structured kitchen tasks; generalization to unstructured, outdoor, or contact-rich environments is not demonstrated
Connections
- Robotics -- primary application domain
- Foundation Models -- demonstrates foundation model paradigm for embodied AI
- Vision Language Action -- PaLM-E is a precursor to the VLA paradigm
- Openvla An Open Source Vision Language Action Model -- open-source VLA inspired by PaLM-E's approach
- Attention Is All You Need -- transformer backbone underpinning PaLM