Toolformer: Language Models Can Teach Themselves to Use Tools
Overview
Large language models exhibit remarkable in-context learning abilities but paradoxically struggle with tasks that are trivial for simple external tools -- arithmetic, factual lookup, calendar queries, and translation. Toolformer addresses this fundamental limitation by teaching a language model to autonomously decide when and how to call external tools via API calls, without sacrificing its general language modeling ability. The key insight is that tool use can be learned in a self-supervised manner: the model itself generates candidate API calls, and only those that demonstrably reduce perplexity on future tokens are retained as training data.
The approach works by augmenting a pre-existing text dataset (a subset of CCNet) with API call annotations. Starting from a GPT-J 6.7B base model, Toolformer uses few-shot prompting to sample candidate API calls at each position in the text, executes those calls to obtain results, and then filters by a simple criterion: an API call is kept only if the loss on subsequent tokens decreases when the call and its result are included versus when they are not. The model is then fine-tuned on this filtered, API-annotated dataset. At inference time, the model generates special tokens (<API>, </API>) that trigger tool execution mid-generation, with results inserted back into the sequence.
Toolformer incorporates a range of tools including a calculator, a Q&A system, two different search engines, a machine translator, and a calendar. It demonstrated that a 6.7B parameter model could match or exceed GPT-3 (175B) on multiple downstream tasks requiring factual knowledge (LAMA), mathematical reasoning (ASDiv, SVAMP, MAWPS), question answering (Web Questions, Natural Questions, TriviaQA), and temporal reasoning -- while retaining strong general language modeling performance. The paper is a landmark in the tool-augmented LLM paradigm, showing that tool use need not be hard-coded or require human-annotated training data. It directly influenced subsequent work on agents, function calling, and retrieval-augmented generation.
Key Contributions
- Self-supervised tool-use learning: A method where LMs generate, execute, and filter their own API call training data, requiring no human annotations of tool use -- just a few demonstrations per tool
- Loss-based filtering criterion: API calls are retained only if including the call and its response reduces the model's loss on subsequent tokens, ensuring learned tool use is genuinely helpful
- Multi-tool integration: Demonstrated unified learning of six diverse tools (calculator, QA system, two different search engines, machine translator, calendar) within a single model
- Small model beats large model: A 6.7B model with tool access outperforms GPT-3 (175B) on several benchmarks, showing that tool augmentation is a more efficient path than pure scaling for certain capabilities
- Preserved generality: The fine-tuning procedure maintains the base model's language modeling perplexity, avoiding the common pitfall of capability degradation during specialization
Architecture / Method
Toolformer: Self-Supervised Tool-Use Learning
┌─────────────────────────────────────────────────────┐
│ Training Pipeline │
│ │
│ Text Corpus (CCNet subset) │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ 1. Sample API │ Few-shot prompt GPT-J 6.7B │
│ │ candidates │ to generate <API>...</API> │
│ └────────┬─────────┘ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ 2. Execute calls │ Calculator, QA, WikiSearch, │
│ │ against tools │ MT, Calendar ──► results │
│ └────────┬─────────┘ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ 3. Filter: keep │ Keep iff L⁻ - L⁺ >= τ │
│ │ only if loss ↓ │ (tool result reduces ppl) │
│ └────────┬─────────┘ │
│ ▼ │
│ Fine-tune GPT-J on augmented + original data │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Inference │
│ │
│ "The population of Paris is <API> WikiSearch(Paris │
│ population) ──► 2.1 million </API> 2.1 million." │
│ │
│ Model generates ──► <API> triggers tool call ──► │
│ result inserted ──► generation resumes after </API>│
└─────────────────────────────────────────────────────┘
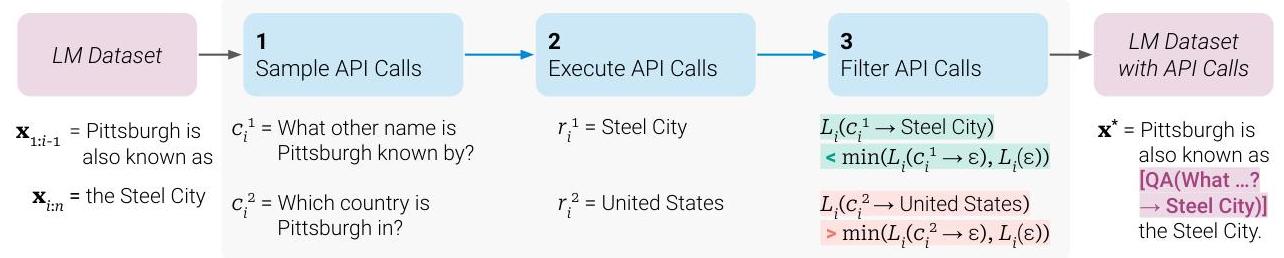
Data Annotation Pipeline
The Toolformer training pipeline has three stages:
-
Candidate sampling: For each position in the training text, the model is prompted (via few-shot examples) to generate candidate API calls. Each API call is represented as a special token sequence:
<API> tool_name(arguments) → result </API>. The model generates up to 5 candidates per position using nucleus sampling. -
Execution: All candidate API calls are actually executed against the corresponding tools to obtain real results. For example, a
Calculator(135/4)call returns33.75, and aWikiSearch(metallurgy)call returns a Wikipedia snippet. -
Filtering: For each candidate, two losses are computed: - L_i^+: the loss on tokens following the API call position, with the call and result included - L_i^-: the minimum of (a) loss without any API call, and (b) loss with the call but an empty result
A call is retained only if L_i^- - L_i^+ >= tau_f (a filtering threshold), meaning the tool result must provide a substantial perplexity reduction.
Tool Definitions
| Tool | API Format | Purpose |
|---|---|---|
| Calculator | <API> Calculator(math_expr) </API> |
Arithmetic operations |
| Q&A System | <API> QA(question) </API> |
Factual question answering (Atlas-based) |
| Wikipedia Search | <API> WikiSearch(query) </API> |
Factual knowledge retrieval (search engine 1) |
| Search Engine | <API> Search(query) </API> |
Web search for factual retrieval (search engine 2) |
| Machine Translator | <API> MT(text, target_lang) </API> |
Translation via NLLB 600M |
| Calendar | <API> Calendar() </API> |
Current date lookup |
Training
The filtered API-augmented dataset is merged with the original unannotated data. The model (GPT-J 6.7B) is fine-tuned on this combined corpus using standard language modeling loss. At inference, when the model generates an <API> token, decoding is paused, the tool is called, the result is inserted, and decoding resumes after </API>.
Key Design Decisions
- No task-specific training: The model learns tool use purely from language modeling on augmented text, not from downstream task supervision
- Interleaved tool calls: API calls occur mid-sequence, allowing the model to use tool outputs as context for subsequent generation
- Minimal human supervision: Only 3-5 few-shot examples per tool are required to bootstrap the annotation process
- Sampling threshold: A separate threshold tau_s (applied before execution) pre-filters obvious bad candidates to reduce computational cost
Results
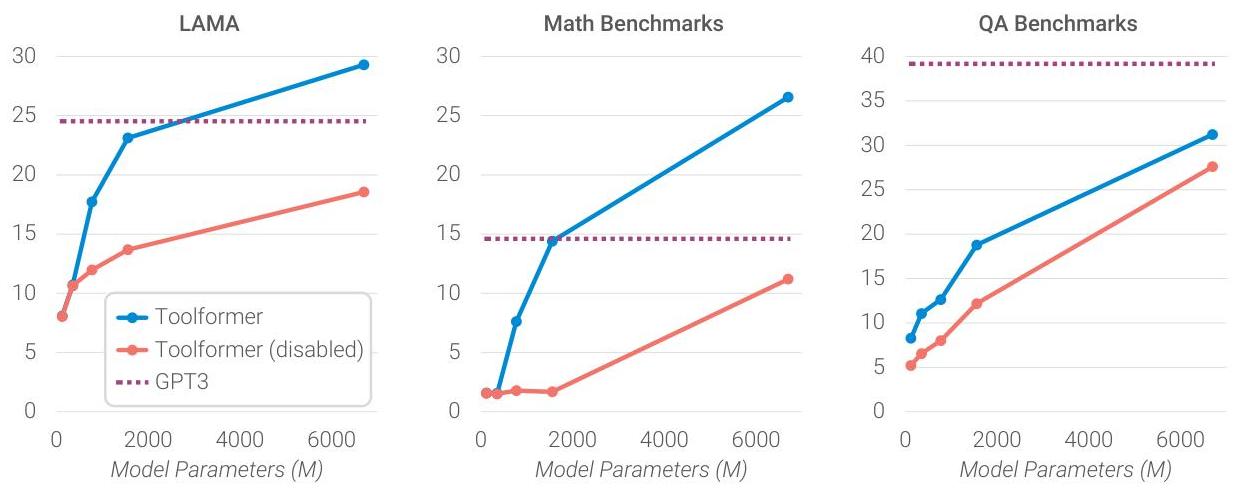
Toolformer was evaluated zero-shot across multiple benchmarks:
| Task | Benchmark | GPT-J (6.7B) | Toolformer (6.7B) | GPT-3 (175B) |
|---|---|---|---|---|
| Math | ASDiv | 7.5 | 40.4 | 14.0 |
| Math | SVAMP | 5.2 | 29.4 | 10.0 |
| Math | MAWPS | 9.9 | 44.0 | 19.8 |
| QA | Web Questions | 18.5 | 26.3 | 29.0 |
| QA | Natural Questions | 12.8 | 17.7 | 22.6 |
| QA | TriviaQA | 43.9 | 48.8 | 65.9 |
| Factual | LAMA (T-REx) | 31.9 | 53.5 | 39.8 |
| Factual | LAMA (Google-RE) | 4.9 | 11.5 | 7.0 |
| Temporal | TempLAMA | 13.7 | 16.3 | 15.5 |
| Translation | MLQA (en→es) | 15.2 | 20.6 | -- |
| LM Perplexity | WikiText (ppl) | 9.9 | 10.3 | -- |
Key findings: - Toolformer outperforms GPT-3 on math tasks despite being 26x smaller - Factual retrieval via WikiSearch closes much of the gap with larger models - Language modeling perplexity is preserved or slightly improved after fine-tuning - The model learns appropriate tool selection -- it does not blindly insert API calls but uses them only when beneficial
Ablation Highlights
- Filtering is critical: Without the loss-based filtering, performance drops significantly -- the model learns to insert API calls that are noisy or unhelpful
- More tools help: Adding more tools does not degrade performance on other tools; the model can learn to route to the appropriate tool
- Data size matters moderately: Using 10% of the augmented data still captures most of the benefit, suggesting the filtering produces high-quality examples
Limitations & Open Questions
- Fixed tool set: Tools must be defined before training; the model cannot discover or adapt to new tools at inference time without retraining
- Sequential tool calls only: The model cannot compose tool calls (e.g., using the output of one tool as input to another) in a single reasoning chain
- Limited to text-in/text-out tools: Cannot integrate tools with non-textual inputs or outputs (images, structured data)
- Evaluation only zero-shot: The paper does not explore whether tool use improves with in-context examples or instruction tuning
- Scaling behavior unknown: Only tested on GPT-J 6.7B; unclear how the approach interacts with model scale (larger models may need tools less, or may use them more effectively)
- Real-time tool latency: Tool execution introduces variable latency during generation, which is not analyzed
Connections
Related papers in the wiki: - Language Models Are Few Shot Learners -- GPT-3 serves as the primary baseline; Toolformer shows that augmenting a much smaller model with tools can match or exceed GPT-3's capabilities - Attention Is All You Need -- The transformer architecture underlying both GPT-J and the tool-use paradigm - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- Chain-of-thought is a complementary approach to improving LLM reasoning; Toolformer externalizes computation to tools rather than eliciting internal reasoning steps - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT-based models are used within Toolformer's QA tool (Atlas) - Palm E An Embodied Multimodal Language Model -- PaLM-E extends multimodal LLMs to embodied settings; Toolformer's approach to tool integration influenced how later multimodal models interact with external systems - Foundation Models -- Toolformer exemplifies how foundation models can be augmented rather than scaled to gain new capabilities