BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Citation
Devlin, Chang, Lee, Toutanova (Google AI Language), NAACL, 2019.
Canonical link
Overview
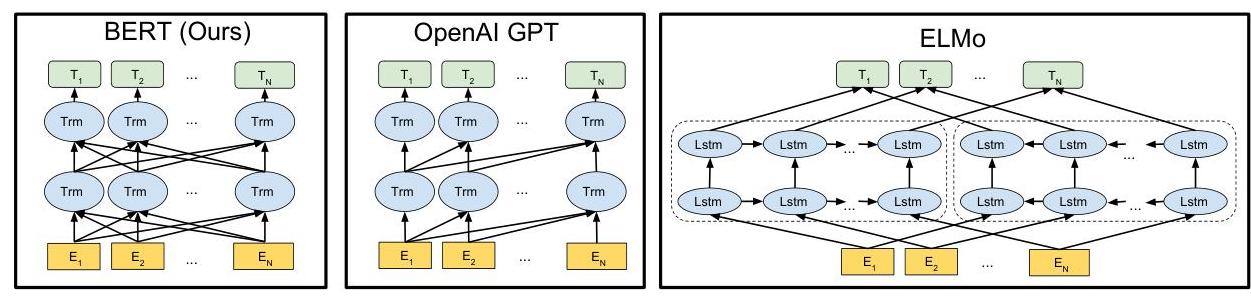
BERT (Bidirectional Encoder Representations from Transformers) introduced the now-standard paradigm of pre-training a deep bidirectional transformer on unlabeled text and then fine-tuning on downstream tasks. Unlike GPT (which uses left-to-right, autoregressive pre-training) and ELMo (which concatenates separately trained left-to-right and right-to-left representations), BERT jointly conditions on both left and right context in all layers through a masked language modeling (MLM) objective. This allows every token's representation to fuse information from the entire sequence.
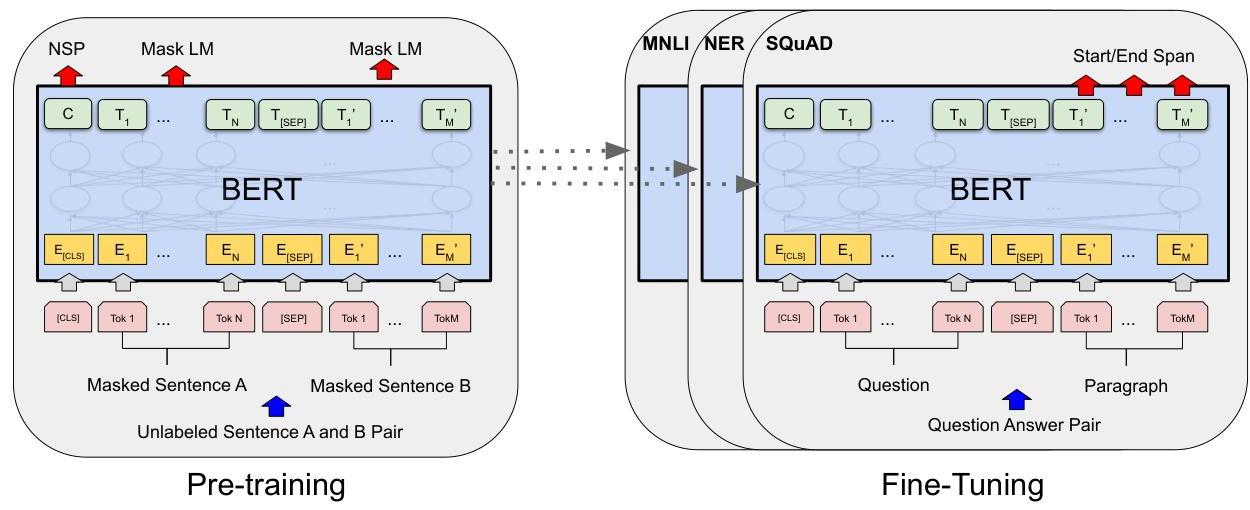
The pre-training procedure uses two objectives: (1) Masked Language Modeling, where 15% of input tokens are masked and the model predicts the original token, and (2) Next Sentence Prediction (NSP), where the model predicts whether two segments are consecutive in the original text. After pre-training on BooksCorpus (800M words) and English Wikipedia (2,500M words), BERT is fine-tuned by adding a single task-specific output layer and training all parameters end-to-end on the target task.
BERT's impact was enormous. It achieved state-of-the-art results on 11 NLP benchmarks simultaneously upon release, including pushing the official GLUE leaderboard score to 80.5 with BERT-LARGE and MultiNLI accuracy to 86.7. It demonstrated that pre-trained representations could dramatically reduce the need for task-specific architectures -- the same pre-trained model could be fine-tuned for question answering, sentiment analysis, named entity recognition, and textual entailment. BERT established encoder-only transformers as the dominant paradigm for NLU and remains the foundation for representation learning in multimodal systems.
Key Contributions
- Masked Language Modeling (MLM): Randomly masks 15% of input tokens and trains the model to predict them, enabling genuinely bidirectional pre-training unlike autoregressive (left-to-right) models. The masking strategy uses 80% [MASK] token, 10% random token, 10% unchanged to mitigate the pre-training/fine-tuning mismatch
- Pre-train then fine-tune paradigm at scale: Demonstrated that a single pre-trained model with minimal task-specific modifications (one output layer) could achieve SOTA on diverse NLP tasks, replacing the prior practice of designing task-specific architectures
- Next Sentence Prediction (NSP): A binary classification objective predicting whether sentence B follows sentence A in the original corpus, designed to capture inter-sentence relationships useful for QA and NLI (later work showed NSP was less critical than MLM)
- WordPiece tokenization with special tokens: Uses WordPiece vocabulary of 30,000 tokens with [CLS] (classification) and [SEP] (separator) tokens, establishing conventions still used in modern transformers
- Two model sizes as community baselines: BERT-BASE (12 layers, 768 hidden, 110M params) and BERT-LARGE (24 layers, 1024 hidden, 340M params) became standard reference points for the field
Architecture / Method
┌───────────────────────────────────────────────────────────────┐
│ BERT Input Representation │
│ │
│ [CLS] tok1 tok2 ... [SEP] tokA tokB ... [SEP] │
│ │ │ │ │ │ │ │ │
│ ▼ ▼ ▼ ▼ ▼ ▼ ▼ │
│ Token Embedding + Position Embedding + Segment Embedding │
│ │ │
├─────────────────────────┼─────────────────────────────────────┤
│ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ Transformer Encoder x12/x24 │ │
│ │ ┌─────────────────────────────────────┐ │ │
│ │ │ Multi-Head Self-Attention │ │ │
│ │ │ (bidirectional: attends to ALL │ │ │
│ │ │ positions in both directions) │ │ │
│ │ └──────────────┬──────────────────────┘ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────────────┐ │ │
│ │ │ Feed-Forward Network │ │ │
│ │ └─────────────────────────────────────┘ │ │
│ └─────────────────────────────────────────────┘ │
│ │ │
├─────────────────────────┼─────────────────────────────────────┤
│ PRE-TRAINING ▼ FINE-TUNING │
│ ┌──────────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ MLM: predict │ │ [CLS] │ │ + Task Head │ │
│ │ masked 15% │ │ repr. │ │ (linear layer) │ │
│ │ of tokens │ │ │ │ │ │ │
│ ├──────────────┤ │ ▼ │ │ Classification, │ │
│ │ NSP: predict │ │ NSP head │ │ QA, NER, etc. │ │
│ │ next sentence│ └──────────┘ └──────────────────┘ │
│ └──────────────┘ │
│ │
│ BERT-BASE: 12 layers, 768 hidden, 12 heads, 110M params │
│ BERT-LARGE: 24 layers, 1024 hidden, 16 heads, 340M params │
└───────────────────────────────────────────────────────────────┘
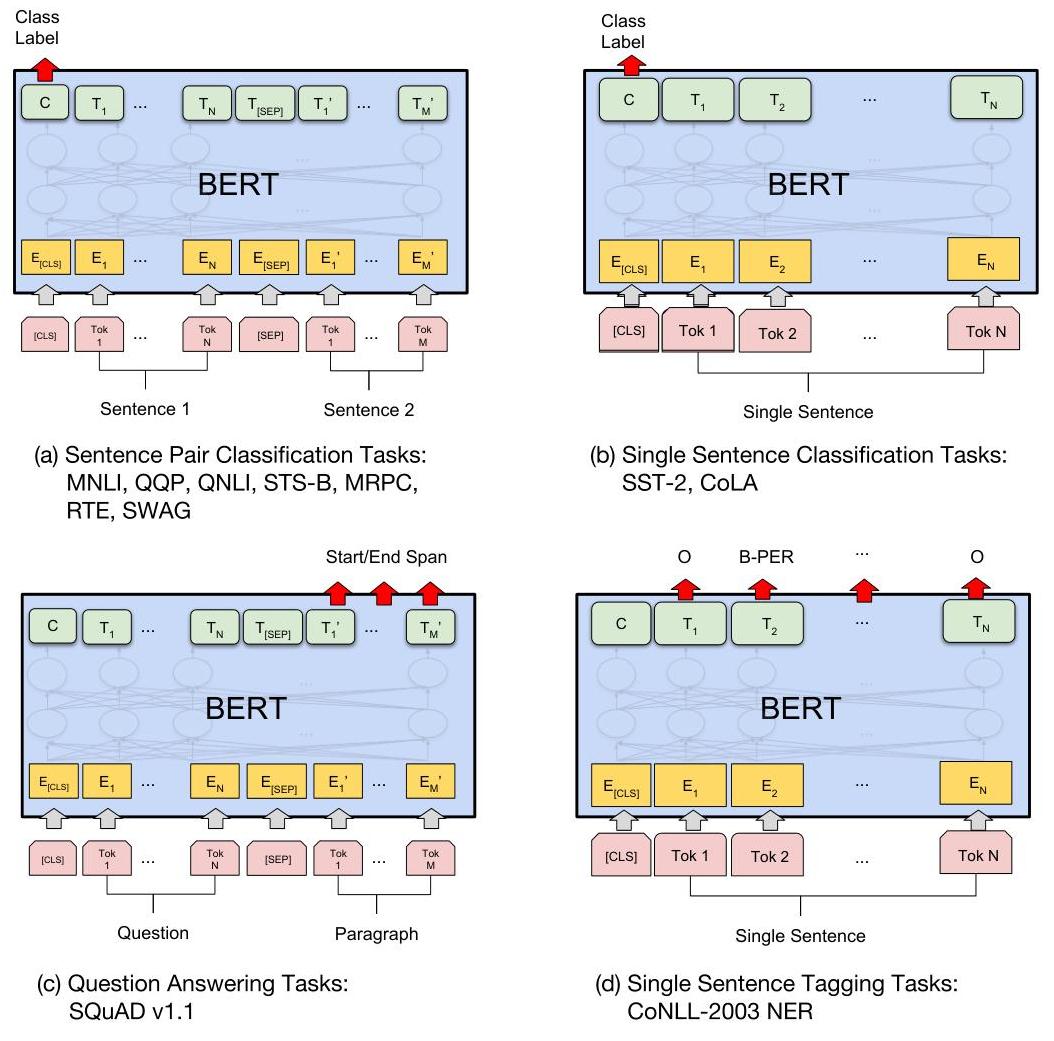
BERT uses the encoder portion of the original Transformer architecture. BERT-BASE has 12 transformer layers, 12 attention heads, hidden dimension 768, and 110M parameters. BERT-LARGE has 24 layers, 16 heads, hidden dimension 1024, and 340M parameters. Input sequences can be up to 512 tokens, constructed as [CLS] + tokens_A + [SEP] + tokens_B + [SEP] for sentence-pair tasks, or [CLS] + tokens + [SEP] for single-sentence tasks.
Each input token's representation is the sum of three embeddings: the WordPiece token embedding, a learned positional embedding, and a segment embedding (indicating whether the token belongs to sentence A or B). Pre-training runs for 1M steps on 256 sequences of length 512, using Adam with learning rate 1e-4 and warmup. BERTBASE was trained on 4 Cloud TPUs (16 TPU chips total) and BERTLARGE on 16 Cloud TPUs (64 TPU chips total), with each pretraining run taking about 4 days.
For fine-tuning, a task-specific head (typically a linear layer) is added on top of the [CLS] token representation (for classification) or on top of each token representation (for token-level tasks like NER). All parameters -- including the pre-trained transformer layers -- are fine-tuned end-to-end with a small learning rate (2e-5 to 5e-5) for 2-4 epochs. This makes fine-tuning extremely fast (typically under an hour on a single GPU).
Results
| Benchmark | BERT-LARGE | Previous SOTA | Improvement |
|---|---|---|---|
| GLUE | 80.5 | 72.8 | +7.7 pts |
| SQuAD v1.1 (F1) | 93.2 | 91.7 | +1.5 pts |
| SQuAD v2.0 (F1) | 83.1 | 78.0 | +5.1 pts |
| MultiNLI | 86.7% | 82.1% | +4.6% |
- GLUE benchmark: BERT-LARGE achieves 80.5 on the official GLUE leaderboard, surpassing OpenAI GPT's 72.8 by 7.7 points absolute
- SQuAD 1.1 (reading comprehension): F1 of 93.2 (ensemble + TriviaQA augmentation), surpassing human performance (91.2 F1); single model result is 91.8 F1
- SQuAD 2.0 (with unanswerable questions): F1 of 83.1, surpassing the previous best by 5.1 points
- SWAG (commonsense inference): 86.3% accuracy, surpassing human expert performance (85.0%) and the previous SOTA by 27.1% absolute
- Ablation studies show MLM is crucial: Replacing bidirectional MLM with left-to-right training drops MRPC accuracy from 86.7 to 77.8 and SQuAD F1 from 91.3 to 81.0, quantifying the value of bidirectionality
- Model size matters: BERT-LARGE consistently outperforms BERT-BASE across all tasks, even on small datasets (contrary to the concern that large models would overfit)
Limitations & Open Questions
- BERT's MLM pre-training creates a discrepancy with fine-tuning (the [MASK] token never appears at fine-tuning time), which later models like XLNet and ELECTRA addressed
- The maximum sequence length of 512 tokens limits applicability to long documents; BERT cannot process book-length or document-level inputs without chunking
- NSP was later shown to be unnecessary or even harmful by RoBERTa and ALBERT, suggesting the pre-training recipe has room for improvement