Scaling Instruction-Finetuned Language Models (Flan-PaLM / Flan-T5)
Overview
Large language models exhibit strong few-shot capabilities, but their ability to follow instructions and generalize to unseen tasks remains limited without targeted post-training. Chung et al. (2022) present the most comprehensive study of instruction finetuning to date, scaling it along three axes simultaneously: number of tasks (1,836 tasks across 473 datasets), model size (from T5-Small 80M to PaLM 540B), and the inclusion of chain-of-thought (CoT) reasoning data. The resulting models -- Flan-PaLM and Flan-T5 -- achieve substantial improvements over their base counterparts at a fraction of the pre-training compute cost (roughly 0.2% for PaLM 540B).
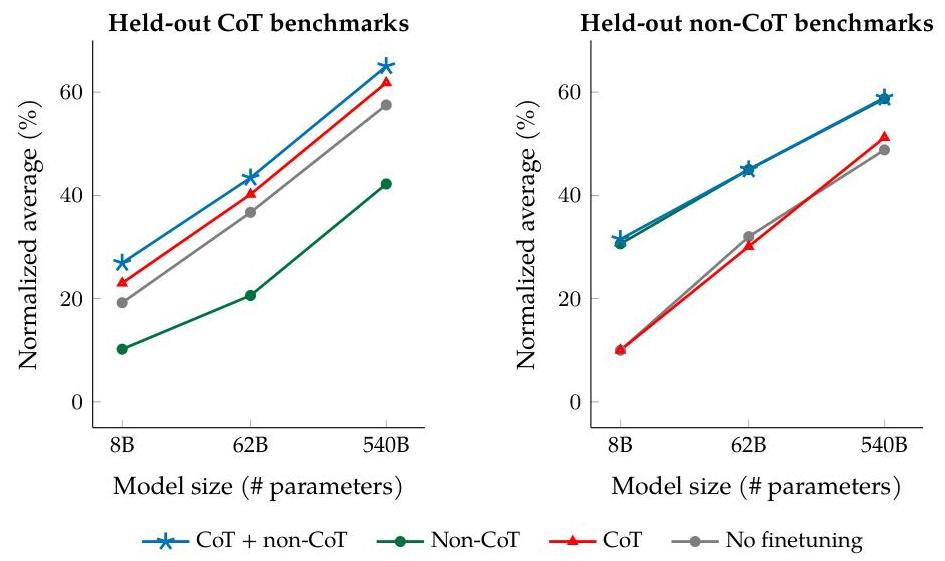
The core insight is that instruction finetuning and chain-of-thought finetuning are complementary rather than conflicting. Previous work had found that standard instruction finetuning could degrade chain-of-thought reasoning. This paper shows that including just nine CoT datasets within the broader 1,836-task mixture resolves this tension entirely: the resulting models excel at both direct-answer tasks and multi-step reasoning tasks, and even acquire zero-shot CoT ability (responding to "let's think step-by-step" without any exemplars) that base models lack. Flan-PaLM 540B achieves 75.2% on MMLU (5-shot, with CoT + self-consistency), substantial gains on BIG-Bench Hard, +14.9% on TyDiQA multilingual QA, and +8.1% on MGSM multilingual math -- while also reducing output toxicity and being preferred by human raters 79% of the time over base PaLM.
The paper also demonstrates that instruction finetuning is architecture-agnostic (working across encoder-decoder T5 and decoder-only PaLM), that performance scales positively with both model size and task count, and that the relative benefit actually increases at larger scales (18.4% error reduction for 540B vs. 16.6% for 8B). Flan-T5-XL (3B) became one of the most widely used open-weight instruction-tuned models and established instruction finetuning as the standard post-training recipe that preceded RLHF-based alignment.
Key Contributions
- Massive multi-task instruction finetuning at scale: Scaled from ~60 tasks (original FLAN) to 1,836 tasks across 473 datasets organized into 146 task categories, demonstrating continued (though diminishing) returns from task diversity
- Joint CoT + non-CoT finetuning: Showed that mixing nine chain-of-thought datasets into the instruction mixture enables both direct-answer and step-by-step reasoning without degradation on either -- resolving a key tension in the field
- Zero-shot CoT emergence: Flan-PaLM can perform chain-of-thought reasoning when prompted with "let's think step-by-step" without any exemplars, a capability entirely absent in the base model
- Architecture-agnostic results: Validated instruction finetuning across T5 (80M--11B, encoder-decoder) and PaLM (8B--540B, decoder-only), plus U-PaLM (540B with UL2 objective)
- Compute efficiency: Instruction finetuning costs roughly 0.2% of pre-training compute for PaLM 540B, making it one of the highest-leverage post-training interventions available
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Flan Instruction Finetuning │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ 1,836 Tasks (473 Datasets) │ │
│ │ ┌──────────┐ ┌────────┐ ┌───────┐ ┌──────────┐ │ │
│ │ │ Muffin │ │ T0-SF │ │ NIV2 │ │ CoT Mix │ │ │
│ │ │ (FLAN+) │ │ │ │ │ │ (9 sets) │ │ │
│ │ └────┬─────┘ └───┬────┘ └──┬────┘ └────┬─────┘ │ │
│ │ └────────────┴─────────┴───────────┘ │ │
│ └──────────────────────┬───────────────────────────┘ │
│ │ 10 templates/task │
│ │ (zero-shot + few-shot) │
│ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Pretrained Language Model │ │
│ │ │ │
│ │ ┌─────────────────┐ ┌──────────────────────┐ │ │
│ │ │ T5 (80M - 11B) │ or │ PaLM (8B - 540B) │ │ │
│ │ │ (enc-dec) │ │ (decoder-only) │ │ │
│ │ └─────────────────┘ └──────────────────────┘ │ │
│ │ │ │
│ │ Fine-tune with next-token prediction / span loss │ │
│ │ (~0.2% of pre-training compute for PaLM 540B) │ │
│ └──────────────────────┬───────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Flan-PaLM / Flan-T5 │ │
│ │ ├── Direct answer tasks ✓ │ │
│ │ ├── Chain-of-thought ✓ (zero-shot CoT) │ │
│ │ └── Held-out tasks ✓ (+9.4% avg) │ │
│ └──────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
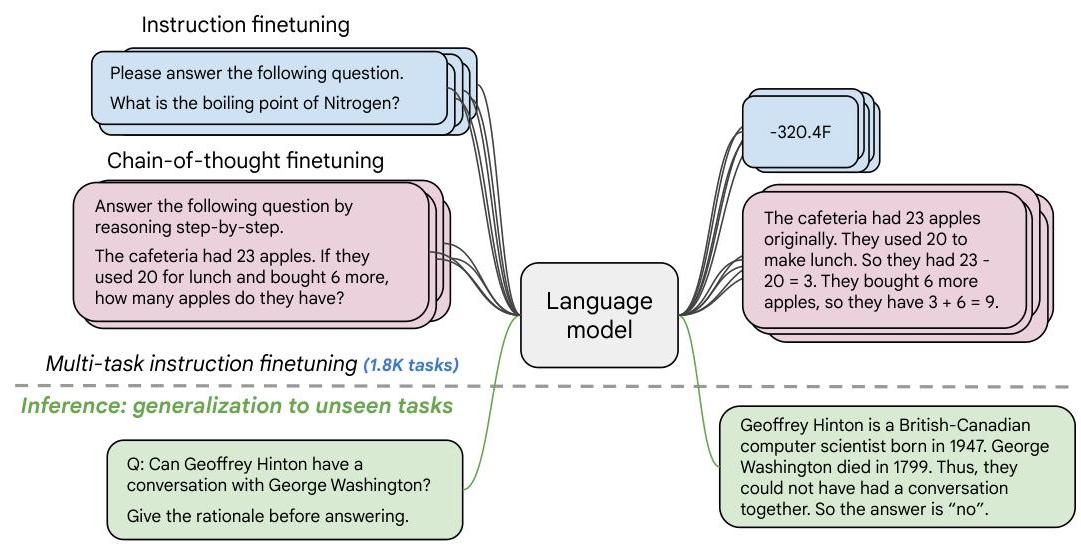
Instruction finetuning takes a pretrained language model and fine-tunes it on a large mixture of tasks phrased as natural language instructions. The method does not modify the model architecture -- it is purely a training-data and objective intervention applied to existing pretrained models.
The Flan Mixture
The finetuning data combines four sources:
- Muffin -- tasks from the original FLAN dataset plus new additions covering NLI, code generation, dialog, and program synthesis
- T0-SF -- tasks from the T0 dataset, deduplicated against other components
- NIV2 -- crowd-sourced tasks covering commonsense reasoning, NER, and question answering
- CoT mixture -- nine datasets with human-annotated step-by-step reasoning chains (including GSM8K, StrategyQA, and others)
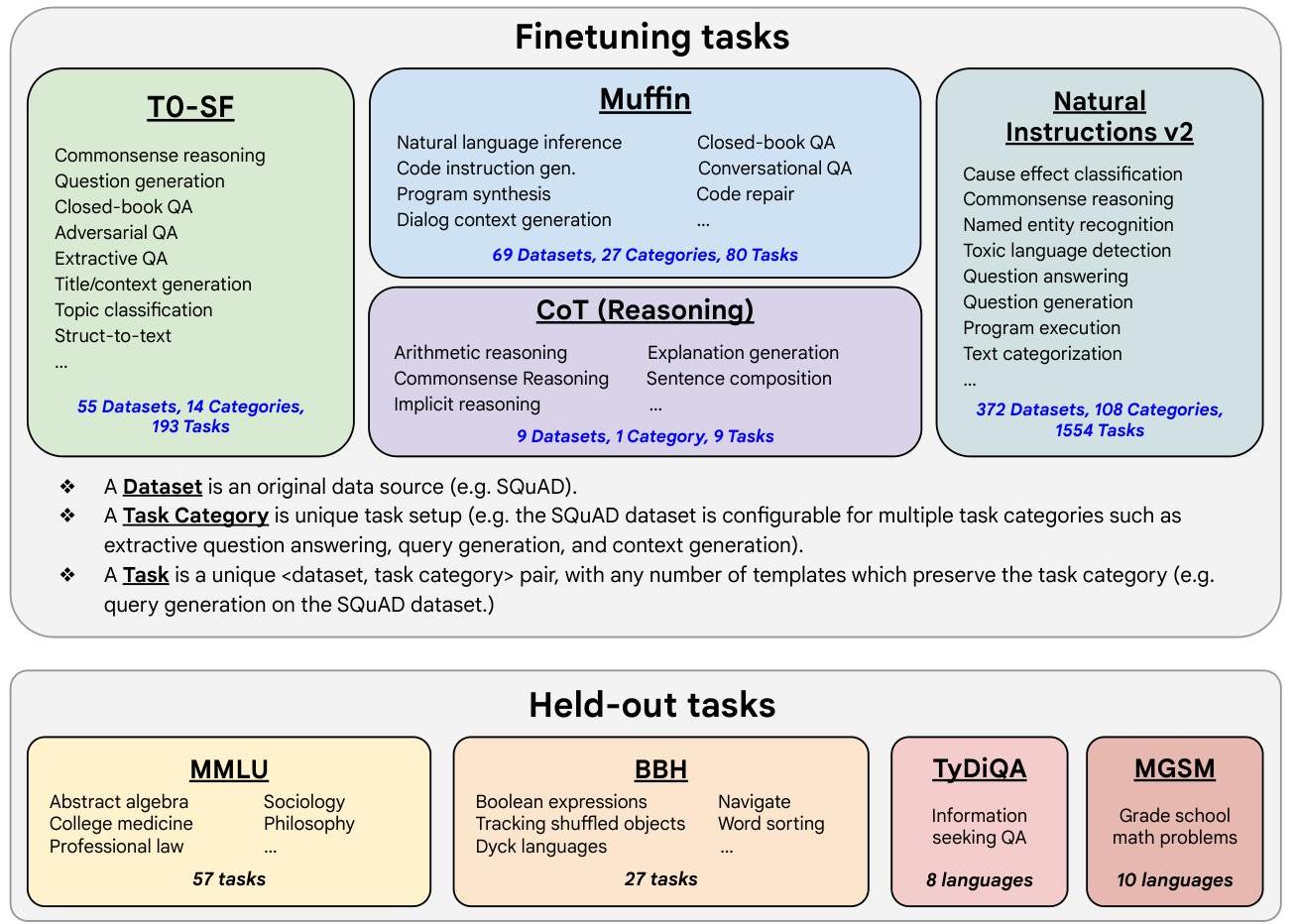
Each task is formatted with up to 10 instruction templates (mixing zero-shot and few-shot formats). The CoT data uses both "with CoT" and "without CoT" versions to teach the model when to reason step-by-step vs. answer directly.
Scaling Dimensions
The paper systematically varies three axes:
| Axis | Range | Key finding |
|---|---|---|
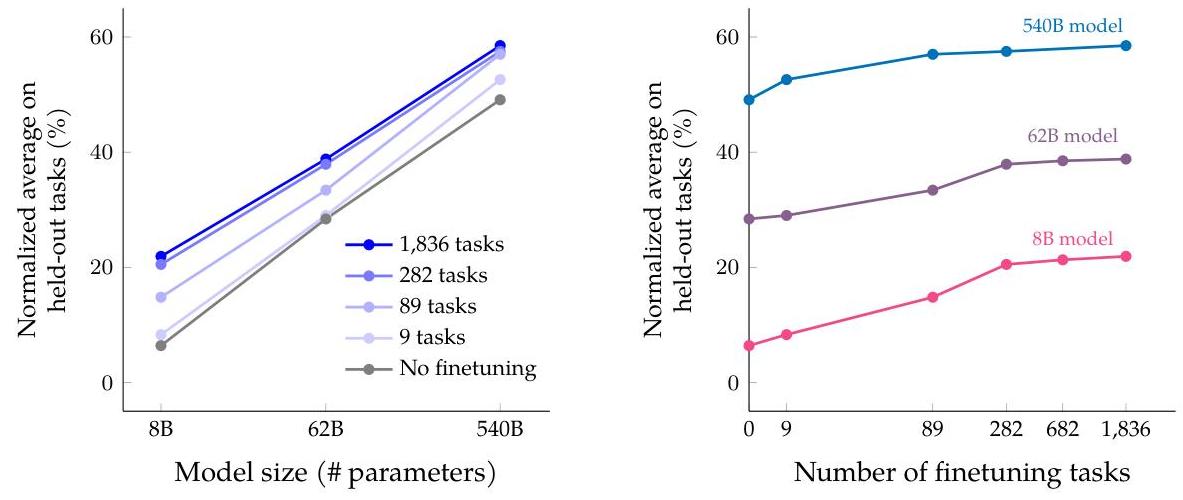
| Model size | 80M (T5-Small) to 540B (PaLM) | Larger models benefit more from instruction finetuning (18.4% error reduction at 540B vs. 16.6% at 8B) |
| Number of tasks | 1 to 1,836 | Majority of gains emerge by ~282 tasks, but scaling to 1,836 still provides incremental benefit |
| CoT data inclusion | With/without 9 CoT datasets | Including CoT data resolves reasoning degradation and enables zero-shot CoT |
Training Details
Training uses a standard language modeling objective (next-token prediction for decoder-only, span corruption for encoder-decoder) on the instruction-formatted mixture. For PaLM 540B, finetuning uses Adafactor with a constant learning rate schedule, packing multiple examples per sequence, for ~21K steps -- roughly 0.2% of pre-training compute.
Results
Benchmark Performance
| Benchmark | Base PaLM 540B | Flan-PaLM 540B | Improvement |
|---|---|---|---|
| MMLU (5-shot) | 69.3% | 75.2% (w/ CoT+SC) | +5.9% |
| TyDiQA (1-shot) | -- | +14.9% | multilingual QA |
| MGSM (CoT) | -- | +8.1% | multilingual math |
| BBH (zero-shot CoT) | fails | succeeds | new capability |
| Held-out tasks (avg) | -- | +9.4% | generalization |
Human Evaluation
Human raters preferred Flan-PaLM over base PaLM 79% of the time for open-ended generation, noting less repetitive text, more appropriate stopping behavior, and more coherent, useful answers.
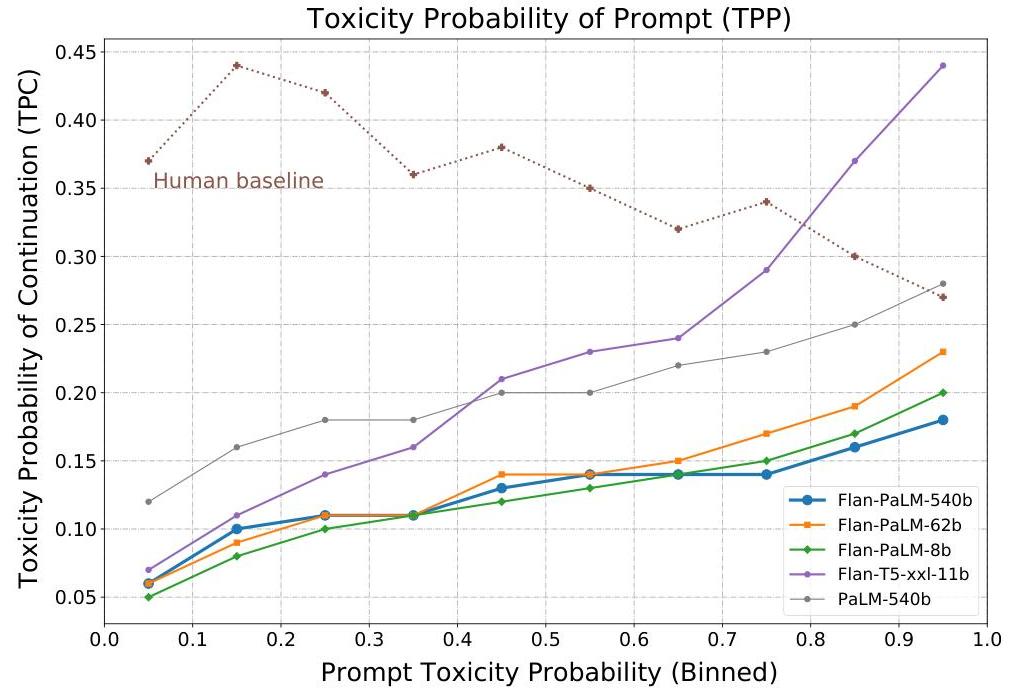
Responsible AI
- Instruction finetuning significantly reduces the probability of generating toxic content across all model scales
- Improvements on gender/occupation association bias benchmarks, though biases are not fully eliminated
- Mixed results on some representational harms (e.g., translation misgendering)
Limitations & Open Questions
- Diminishing returns from task count: Most gains appear by ~282 tasks; it is unclear how to continue scaling task diversity productively beyond 1,836
- No RLHF comparison: The paper predates widespread RLHF adoption and does not compare instruction finetuning against preference-based alignment methods (InstructGPT was concurrent work)
- Finetuning data quality vs. quantity: The paper focuses on scaling task count but does not deeply analyze data quality, curation, or the effect of noisy/low-quality tasks
- Bias mitigation is incomplete: While toxicity improves, representational harms show mixed results, suggesting instruction finetuning alone is insufficient for full alignment
- Cost of task template creation: Each task requires manual instruction templates; scaling beyond 1,836 tasks requires better automation of template generation
Connections
Related papers in the wiki:
- Palm Scaling Language Modeling With Pathways -- Flan-PaLM is the instruction-finetuned version of PaLM; this paper directly builds on PaLM's 540B base model and scaling infrastructure
- Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- Flan-PaLM integrates CoT data into finetuning, making CoT reasoning a zero-shot capability rather than requiring few-shot exemplars
- Training Language Models To Follow Instructions With Human Feedback -- InstructGPT (concurrent work) takes the RLHF approach to instruction following; Flan-PaLM demonstrates that supervised multi-task finetuning alone achieves strong instruction-following without RL
- Language Models Are Few Shot Learners -- GPT-3 established few-shot learning as the dominant LLM evaluation paradigm; Flan-PaLM shows instruction finetuning improves both zero-shot and few-shot performance
- Scaling Laws For Neural Language Models -- Flan-PaLM extends scaling law analysis to the instruction finetuning regime, showing the relative benefit increases with model size
- Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- T5 (encoder-decoder) is a Flan target architecture; BERT established the pretrain-then-finetune paradigm that instruction finetuning scales
- Foundation Models -- Flan-PaLM demonstrates that post-training on instruction data is a compute-efficient way to unlock foundation model capabilities