Scaling Laws for Neural Language Models
Overview
This is the canonical early scaling-law paper for language models, authored by Kaplan et al. at OpenAI. It demonstrated that neural language model cross-entropy loss follows smooth power-law relationships with model size (N), dataset size (D), and compute budget (C) over seven orders of magnitude. These remarkably clean empirical laws enabled principled resource allocation for training and fundamentally changed how the field reasoned about the interplay of parameters, data, and compute.
The paper's most consequential finding was that architecture details (depth vs. width, number of attention heads) matter far less than total non-embedding parameter count for predicting performance. This redirected massive research investment away from architecture search toward simply making models bigger. The controversial recommendation to "train large, stop early" -- allocating most compute to model size rather than data -- directly influenced GPT-3 training decisions.
This paper, together with the later Chinchilla correction (Hoffmann et al., 2022), forms the intellectual foundation for modern LLM scaling practice. The power-law framework provided a quantitative vocabulary for discussing scaling that the entire field adopted, and the ability to predict large-model performance from small-model experiments revolutionized experimental design in deep learning.
Key Contributions
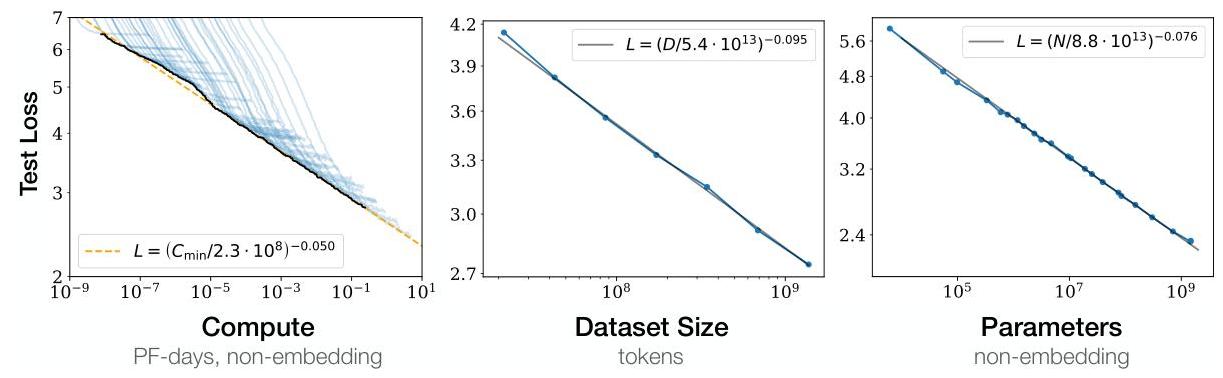
- Three independent power laws: L(N) = (N/8.8x10^13)^{-0.076}, L(D) = (D/5.4x10^13)^{-0.095}, L(C_min) = (C_min/3.1x10^8)^{-0.050}, each holding over many orders of magnitude on WebText2 with Transformer LMs ranging from 768 to 1.5B parameters
- Compute-optimal allocation: For a fixed compute budget C ~ 6ND, the paper derives that optimal training allocates most budget to model size N rather than dataset size D, yielding the "train large, stop early" prescription. Optimal compute allocation follows N_optimal ~ 1.3x10^9 * C^{0.73}
- Architecture invariance: Within the Transformer family, specific choices of depth, width, and attention heads have minimal effect on the scaling exponent; total non-embedding parameter count is the dominant predictor. Performance depends "strongly on scale" but "weakly on model shape"
- Smooth extrapolation: Power-law fits on small models accurately predict loss of 10x larger models, enabling cheap experimental design
- Overfitting characterized by N/D ratio: The generalization gap depends on the ratio N^{0.74}/D, meaning larger models are more sample-efficient, extracting more information from the same amount of data. Doubling model size requires only ~67% additional data
- Transfer learning correlation: Strong correlations exist between training distribution performance and other text distributions, validating broad corpus training approaches
- Transformers vs LSTMs: Transformers asymptotically outperform LSTMs, particularly when utilizing longer context windows
Architecture / Method
┌────────────────────────────────────────────────────────────┐
│ Scaling Laws: Three Power Laws │
├────────────────────────────────────────────────────────────┤
│ │
│ Loss (L) follows power laws over 7 orders of magnitude: │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ L(N) ~ N^α │ │ L(D) ~ D^β │ │ L(C) ~ C^γ │ │
│ │ Model Size │ │ Dataset Size │ │ Compute │ │
│ │ α = -0.076 │ │ β = -0.095 │ │ γ = -0.050 │ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │ │
│ └─────────────────┼──────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ Joint Law: L(N, D) = │ │
│ │ [(Nc/N)^αN/αD + (Dc/D)]^αD │ │
│ └────────────────┬────────────────┘ │
│ │ │
│ ▼ │
│ Key Prescription: C ~ 6ND │
│ ┌───────────────────────────────────────────────┐ │
│ │ "Train large, stop early" │ │
│ │ Allocate most compute to model size N │ │
│ │ N_optimal ~ 1.3e9 * C^0.73 │ │
│ │ │ │
│ │ (Later revised by Chinchilla: scale N and D │ │
│ │ equally for compute-optimal training) │ │
│ └───────────────────────────────────────────────┘ │
└────────────────────────────────────────────────────────────┘
The study trains Transformer language models (decoder-only, GPT-style) on WebText2 across a massive grid of configurations. Model sizes range from 768 parameters to 1.5 billion parameters, varying depth (2-64 layers), width (64-12288 hidden dimensions), and number of attention heads (2-96). Each configuration is trained on varying amounts of data (up to 23B tokens) with varying compute budgets.
The key methodological insight is fitting log-log linear regressions of loss against N, D, and C independently. The smoothness of these fits (R^2 > 0.99) demonstrates that performance is predictable from scale alone. The paper also develops a joint scaling law L(N, D) = [(N_c/N)^{alpha_N/alpha_D} + (D_c/D)]^{alpha_D} that unifies the independent power laws and predicts the loss-optimal allocation of compute between N and D.
Training uses standard autoregressive language modeling with cross-entropy loss, Adam optimizer, and cosine learning rate schedule. The dataset is WebText2 (an expanded version of the original GPT-2 dataset). Careful controls ensure that observed scaling relationships are not artifacts of learning rate tuning, batch size selection, or other training details.
Results
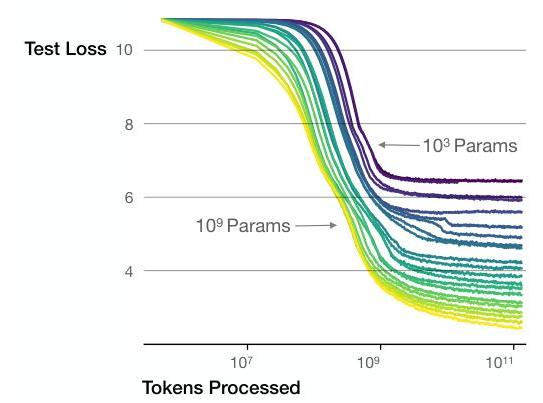
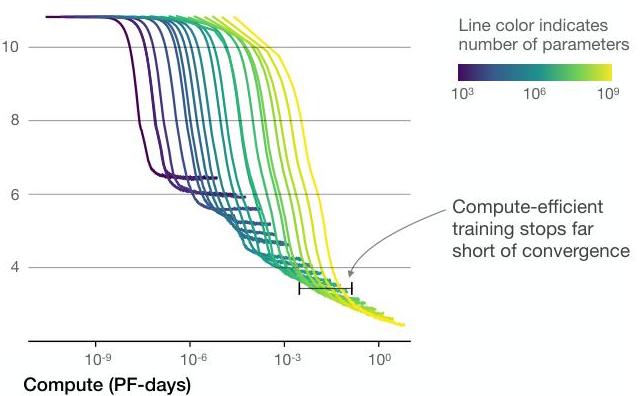
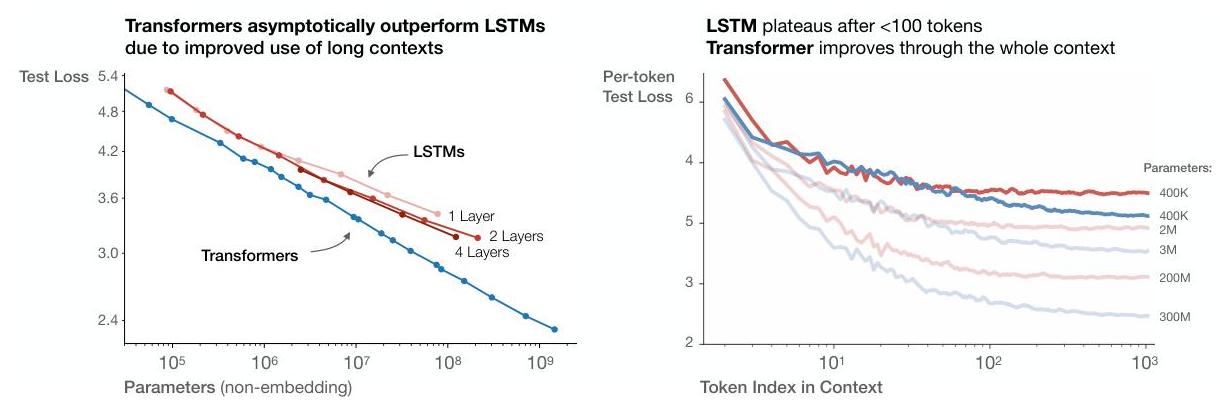
- Power laws hold across 7 orders of magnitude: Empirical fits on models from 768 to 1.5B parameters show R^2 > 0.99 for the log-log regression of loss vs. N, D, and C individually
- Larger models are more sample-efficient: A 10x larger model reaches the same loss with ~10x fewer data tokens, meaning scale substitutes for data up to a point
- Architecture details are second-order: Varying depth from 2 to 64 layers at matched parameter count changes loss by less than the noise of the power-law fit
- Convergence is inefficient: Fully converging a small model uses more compute to reach a given loss than partially training a larger model, supporting early stopping at scale
- Predictable extrapolation: The loss of a 1.5B parameter model can be predicted to within 1% accuracy from fits on models up to 100M parameters
- Batch size scaling: The optimal batch size also follows a power law with respect to loss, growing as training progresses and loss decreases
Limitations & Open Questions
- The "train large, stop early" prescription was later shown to be suboptimal by Hoffmann et al. (Chinchilla, 2022), who found data and parameters should scale roughly equally for compute-optimal training -- the original paper significantly underweighted the importance of data
- Experiments use only autoregressive Transformer LMs on English web text; generalization of exponents to other architectures (encoder-decoder, state-space models), modalities (vision, audio), or languages is not established
- The paper does not address downstream task performance; scaling laws for loss may not translate directly to scaling laws for accuracy on specific benchmarks or emergent capabilities