Overview
Mixtral 8x7B, developed by Mistral AI, introduces a Sparse Mixture-of-Experts (SMoE) language model that achieves the quality of much larger dense models at a fraction of the inference cost. The core idea is simple but powerful: replace each feedforward block in a standard transformer with a set of 8 expert feedforward networks, and use a learned router to select the top-2 experts per token. This means that while the model has 46.7B total parameters, only ~13B are active for any given token, yielding inference costs comparable to a 13B dense model but with the representational capacity of a much larger one.
The paper addresses a fundamental tension in LLM scaling: larger models perform better, but inference cost scales linearly with active parameters. Sparse MoE architectures break this coupling by allowing the model to grow in total capacity without proportionally increasing per-token compute. Mixtral demonstrates this concretely -- it matches or exceeds Llama 2 70B across standard benchmarks while using ~6x fewer active parameters per forward pass.
Mixtral achieves 70.6% on MMLU (vs. Llama 2 70B's 69.8%), 51.8% on mathematics benchmarks (vs. 45.2%), and 50.6% on code generation (vs. 39.8%). The instruction-tuned variant, Mixtral 8x7B-Instruct, surpasses GPT-3.5 Turbo, Claude-2.1, and Gemini Pro on human evaluation benchmarks. The model supports a 32k token context window and demonstrates strong multilingual capabilities across English, French, Italian, German, and Spanish.
Key Contributions
- Sparse Mixture-of-Experts at scale for language: Demonstrates that SMoE applied to every feedforward layer of a decoder-only transformer produces a model that matches 70B dense performance with only 13B active parameters per token
- Top-2 routing with load balancing: Uses a simple learned router that selects 2 of 8 experts per token per layer, with a load-balancing auxiliary loss to prevent expert collapse
- 32k context window: Extends the Mistral 7B architecture to 32k context length using Sliding Window Attention combined with a rolling buffer cache
- Expert specialization analysis: Provides analysis showing that experts specialize by syntax and structure rather than by domain, with specialization increasing in deeper layers and consecutive tokens tending to route to the same experts
- Instruction tuning with DPO: The Instruct variant uses supervised fine-tuning followed by Direct Preference Optimization, achieving top performance among open-weight models at release
Architecture / Method
┌──────────────────────────────────────────────────────────┐
│ Mixtral 8x7B - Sparse MoE Layer │
│ │
│ Token x ──► GQA Attention (32Q / 8KV) ──► + residual │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Router G(x) │ │
│ │ x · W_g │ │
│ │ TopK(k=2) │ │
│ └──┬──┬──────────┘ │
│ ┌─────────────┘ └────────┐ │
│ ▼ ▼ │
│ ┌──────────────────┐ ┌──────────────┐ │
│ │ Expert E_i │ │ Expert E_j │ │
│ │ (SwiGLU FFN) │ │ (SwiGLU FFN)│ │
│ │ dim=14336 │ │ dim=14336 │ │
│ └────────┬─────────┘ └──────┬───────┘ │
│ │ weighted sum │ │
│ └──────── ⊕ ──────────────┘ │
│ G_i·E_i(x) + G_j·E_j(x) │
│ │ │
│ + residual │
│ │ │
│ Total: 46.7B params Active: ~13B per token │
│ 8 experts per layer 2 selected per token │
│ 32 transformer layers + load-balancing aux loss │
└──────────────────────────────────────────────────────────┘

Mixtral builds on the Mistral 7B decoder-only transformer architecture, replacing every dense feedforward block with a Sparse Mixture-of-Experts layer. The architecture uses:
- 32 transformer layers with grouped-query attention (GQA) using 32 heads and 8 KV heads
- Hidden dimension: 4096
- Expert feedforward dimension: 14336 per expert
- 8 experts per MoE layer, with top-2 gating per token
- Vocabulary size: 32000 (SentencePiece BPE tokenizer)
- Sliding Window Attention (SWA): Attention window of 4096 tokens per layer, with a rolling buffer KV cache. Mixtral was trained with a 32k token context size; the effective receptive field across the 32-layer stack can theoretically reach up to 32 × 4096 = ~131k tokens via cascading attention, though the model is trained for 32k
The MoE routing mechanism works as follows. For each token representation x at a given layer, the router computes:
G(x) = Softmax(TopK(x · W_g, k=2))
y = Σ_{i∈TopK} G_i(x) · E_i(x)
where W_g is the learned gating matrix, TopK selects the 2 experts with highest gating scores (setting others to zero), and E_i is the i-th expert feedforward network (SwiGLU). The output is the weighted sum of the selected experts' outputs, where weights are the softmax-normalized gating scores of only the selected experts.
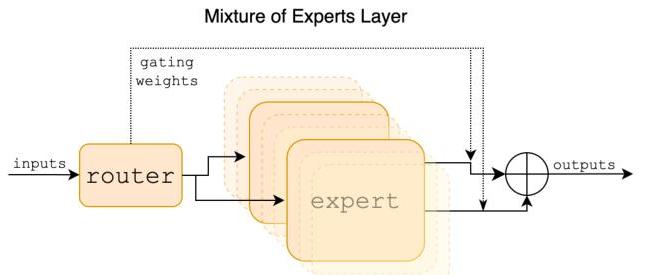
A load-balancing auxiliary loss encourages uniform expert utilization across the batch, preventing degenerate solutions where only a few experts are used. This is critical for training stability and for ensuring all parameters contribute to model quality.
Results
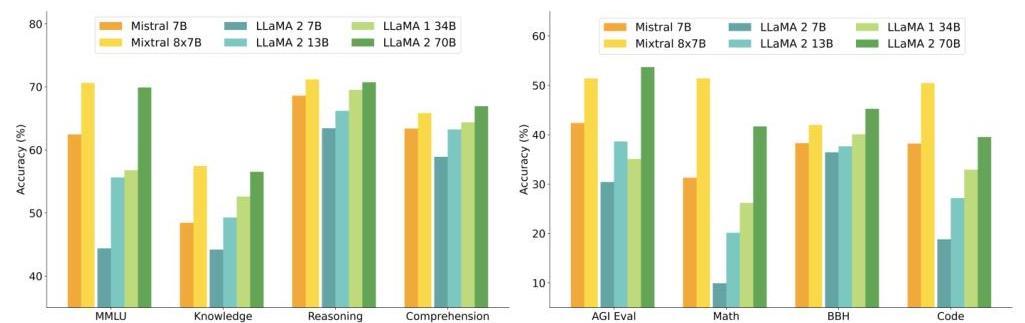
Key benchmark comparisons:
| Model | Active Params | MMLU | GSM8K (math) | HumanEval (code) | ARC-C | HellaSwag |
|---|---|---|---|---|---|---|
| Mixtral 8x7B | 13B | 70.6 | 74.4 | 40.2 | 66.2 | 86.7 |
| Llama 2 70B | 70B | 69.8 | 56.8 | 29.9 | 67.3 | 87.3 |
| GPT-3.5 Turbo | unknown | 70.0 | 57.1 | 48.1 | — | — |
| Llama 2 13B | 13B | 55.8 | 29.6 | 18.9 | 49.4 | 80.7 |
Mixtral matches or exceeds Llama 2 70B on most benchmarks while using only 13B active parameters. The gap is especially large on mathematics (GSM8K: 74.4 vs 56.8) and code (HumanEval: 40.2 vs 29.9), suggesting that expert specialization particularly benefits tasks requiring distinct reasoning modes.
The instruction-tuned Mixtral 8x7B-Instruct variant was evaluated on MT-Bench and human preference evaluations, where it outperformed GPT-3.5 Turbo, Claude-2.1, and Gemini Pro, making it the strongest open-weight instruction model at the time of release.
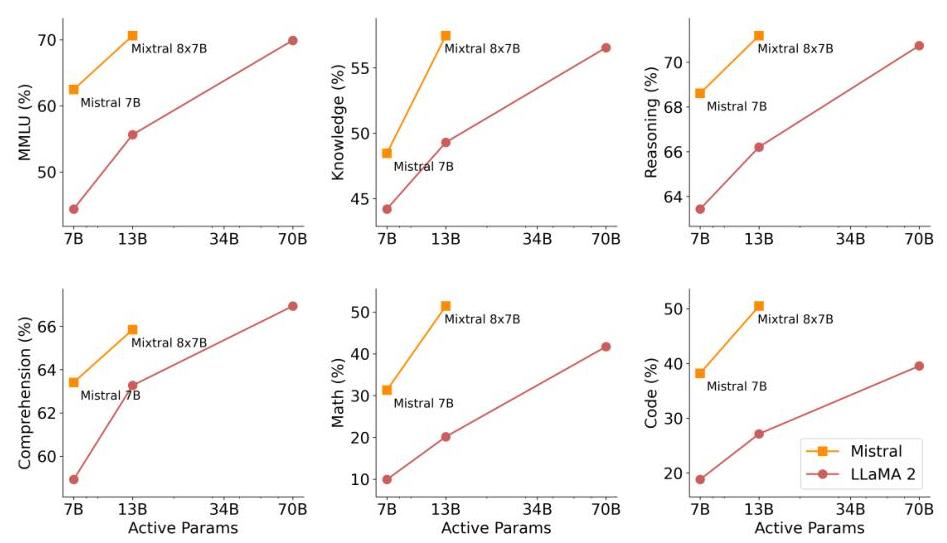
Limitations & Open Questions
- Memory footprint: Although only 13B parameters are active per token, all 46.7B parameters must reside in memory (or be efficiently swapped), making deployment on consumer hardware challenging without quantization
- Expert collapse risk: Without careful load balancing, some experts may become underutilized during training. The paper uses an auxiliary loss but does not extensively ablate its coefficient
- Routing analysis depth: The analysis shows syntactic rather than domain specialization, but the mechanistic understanding of what each expert learns remains shallow
- Scaling beyond 8 experts: The paper does not explore how performance scales with the number of experts or the top-k selection, leaving open whether 16x or 64x configurations would yield further gains
- Comparison fairness: Comparisons to dense models at equal total params (rather than equal active params or equal FLOPs) would provide clearer efficiency characterization
- MoE for driving/embodied AI: Whether the SMoE pattern transfers to multimodal settings (vision-language-action models) is an emerging question -- DriveMoE begins to answer this for autonomous driving
Connections
Related papers in the wiki: - Attention Is All You Need — The transformer architecture that Mixtral builds on - Language Models Are Few Shot Learners — GPT-3 dense scaling; Mixtral achieves comparable quality with sparse efficiency - Training Compute Optimal Large Language Models — Chinchilla scaling laws; Mixtral offers an orthogonal axis of efficiency (sparse activation) beyond compute-optimal dense training - Scaling Laws For Neural Language Models — Kaplan scaling laws that Mixtral's MoE approach complements by decoupling total capacity from active compute - Drivemoe Mixture Of Experts For Vision Language Action In Autonomous Driving — Applies the MoE paradigm to driving VLAs with dual-level expert specialization, directly extending Mixtral's insight to embodied AI - Gpipe Easy Scaling With Micro Batch Pipeline Parallelism — Pipeline parallelism for scaling; MoE provides an alternative scaling axis via expert parallelism - Foundation Models — Mixtral advances the foundation model paradigm by demonstrating sparse scaling as an efficiency frontier