Overview
Qwen3, developed by the Qwen team at Alibaba, represents a major step forward in open-weight language models by offering a comprehensive family spanning both dense and Mixture-of-Experts (MoE) architectures, ranging from 0.6B to 235B total parameters. The flagship models are Qwen3-235B-A22B (a sparse MoE with 235B total parameters but only 22B activated per token) and Qwen3-32B (the largest dense variant). Most models support 128K token context lengths (the 0.6B and 1.7B models support 32K) and cover 119 languages and dialects, a substantial expansion from Qwen2.5's 29 languages.
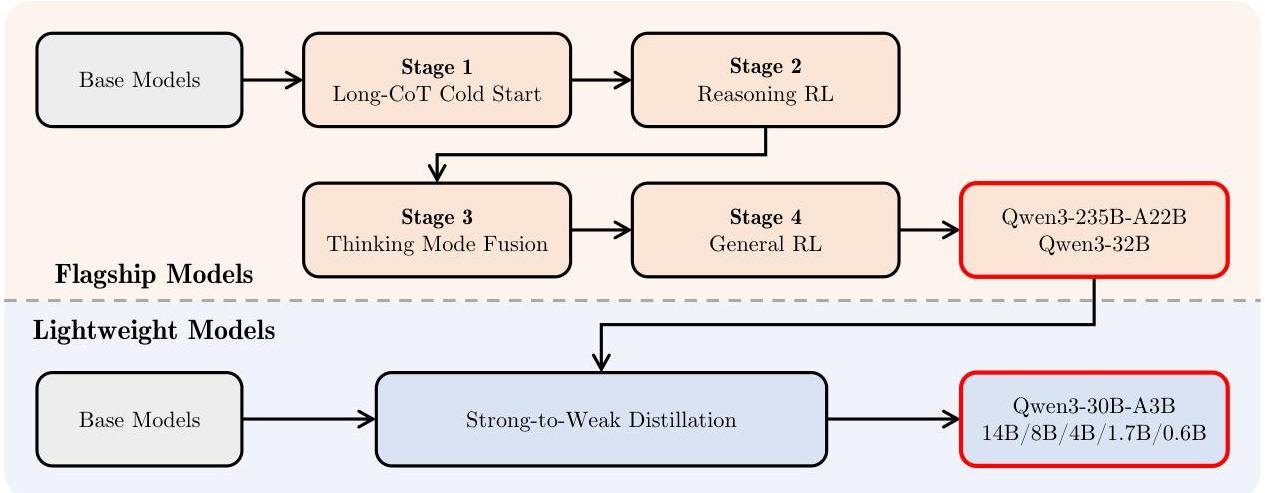
The core innovation is a unified "thinking mode" that enables dynamic allocation of inference-time compute. Rather than forcing a choice between fast generation and deep reasoning, Qwen3 models can seamlessly switch between a "thinking" mode (producing extended chain-of-thought reasoning) and a "non-thinking" mode (direct response) within a single model. This is achieved through a four-stage post-training pipeline that fuses both capabilities: Long-CoT Cold Start, Reasoning RL, Thinking Mode Fusion, and General RL. Users can control the reasoning budget at inference time, allocating more compute to harder problems.
Qwen3-235B-A22B achieves highly competitive results: 85.7 on AIME'24, 81.5 on AIME'25, 70.7 on LiveCodeBench v5, and 2,056 on CodeForces. These results place it in the same tier as much larger proprietary models, while the MoE architecture keeps inference costs comparable to a ~22B dense model. The smaller dense models (0.6B--32B) also demonstrate strong performance through a strong-to-weak distillation pipeline that transfers reasoning capabilities from the larger models.
Key Contributions
- Dense + MoE model family: A complete lineup of 8 models (6 dense: 0.6B, 1.7B, 4B, 8B, 14B, 32B; 2 MoE: 30B-A3B, 235B-A22B) all sharing the same architectural components and training recipe
- Unified thinking mode: A single model that can dynamically switch between extended chain-of-thought reasoning and direct response, controlled by the user at inference time via budget/thinking toggles
- Massive multilingual pretraining: 36 trillion tokens across 119 languages and dialects, with a three-stage pre-training pipeline (general knowledge, reasoning enhancement, long-context adaptation)
- Four-stage post-training alignment: Long-CoT Cold Start → Reasoning RL → Thinking Mode Fusion → General RL, producing models that reason deeply when needed and respond efficiently when not
- Strong-to-weak distillation: Systematic knowledge transfer from larger to smaller models, enabling even the 0.6B model to exhibit reasoning capabilities
- Open release under Apache 2.0: All models released as open weights, lowering barriers for research and deployment
Architecture / Method
┌─────────────────────────────────────────────────────┐
│ Qwen3 Training Pipeline │
│ │
│ PRE-TRAINING (36T tokens, 119 languages) │
│ ┌───────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Stage 1 │─►│ Stage 2 │─►│ Stage 3 │ │
│ │ General │ │ Reasoning │ │ Long-Context │ │
│ │ Knowledge │ │ Enhancement │ │ (128K RoPE) │ │
│ └───────────┘ └──────────────┘ └──────────────┘ │
│ │
│ POST-TRAINING (4-stage alignment) │
│ ┌────────────┐ ┌────────────┐ ┌──────────────┐ │
│ │ Long-CoT │─►│ Reasoning │─►│ Thinking │ │
│ │ Cold Start │ │ RL (GRPO) │ │ Mode Fusion │──┤
│ │ (SFT) │ │ │ │ │ │
│ └────────────┘ └────────────┘ └──────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ General RL │ │
│ │ (helpfulness │ │
│ │ + safety) │ │
│ └──────────────┘ │
│ │
│ ARCHITECTURE: Decoder-only Transformer │
│ GQA + SwiGLU + RoPE + RMSNorm + QK-Norm │
│ Dense: 0.6B─32B │ MoE: 30B-A3B, 235B-A22B │
└─────────────────────────────────────────────────────┘
Inference: Unified thinking mode
┌──────────────┐ ┌──────────────┐
│ "Thinking" │ ◄──►│"Non-thinking"│
│ (Long CoT) │ │ (Direct) │
└──────────────┘ └──────────────┘
User controls reasoning budget dynamically
Qwen3 uses a decoder-only transformer architecture with the following core components:
- Grouped Query Attention (GQA): Reduces KV cache memory while maintaining attention quality, enabling efficient long-context inference
- SwiGLU activation functions: In feedforward layers, providing better training dynamics than standard ReLU or GELU
- Rotary Positional Embeddings (RoPE): For position encoding, supporting extrapolation to 128K context
- RMSNorm with pre-normalization: For stable training at scale
- QK-Norm: Normalizes query and key vectors to prevent attention entropy collapse in deep models
Model Variants
| Model | Type | Total Params | Active Params | Layers | Hidden Dim | Attention Heads | KV Heads |
|---|---|---|---|---|---|---|---|
| Qwen3-0.6B | Dense | 0.6B | 0.6B | -- | -- | -- | -- |
| Qwen3-1.7B | Dense | 1.7B | 1.7B | -- | -- | -- | -- |
| Qwen3-4B | Dense | 4B | 4B | -- | -- | -- | -- |
| Qwen3-8B | Dense | 8B | 8B | -- | -- | -- | -- |
| Qwen3-14B | Dense | 14B | 14B | -- | -- | -- | -- |
| Qwen3-32B | Dense | 32B | 32B | -- | -- | -- | -- |
| Qwen3-30B-A3B | MoE | 30B | 3B | -- | -- | -- | -- |
| Qwen3-235B-A22B | MoE | 235B | 22B | -- | -- | -- | -- |
The MoE variants use a learned router to select a subset of experts per token at each feedforward layer (analogous to Mixtral Of Experts), keeping per-token compute bounded while dramatically expanding model capacity. Load-balancing losses prevent expert collapse.
Three-Stage Pre-training
- Stage 1 -- General knowledge: Broad pre-training on a diverse multilingual corpus to build world knowledge and linguistic competence
- Stage 2 -- Reasoning enhancement: Increased proportion of STEM, code, and reasoning-heavy data to strengthen analytical capabilities
- Stage 3 -- Long-context adaptation: Pre-training on long-context corpora at 32K sequence lengths with adjusted RoPE base frequency (ABF); inference-time context is further extended to 128K via YARN and Dual Chunk Attention (DCA)
The total pre-training corpus spans 36 trillion tokens across 119 languages, a significant scale-up from Qwen2.5.
Four-Stage Post-training
- Long-CoT Cold Start: Supervised fine-tuning on long chain-of-thought demonstrations to teach the model extended reasoning patterns
- Reasoning RL: Reinforcement learning (likely GRPO-style) to improve reasoning quality beyond what supervised demonstrations provide, using outcome-based rewards
- Thinking Mode Fusion: Merging the reasoning-trained model with direct-response capabilities so a single model handles both modes seamlessly
- General RL: Broad reinforcement learning for instruction following, helpfulness, harmlessness, and general quality across all tasks
Results
| Benchmark | Qwen3-235B-A22B | Domain |
|---|---|---|
| AIME'24 | 85.7 | Mathematics |
| AIME'25 | 81.5 | Mathematics |
| LiveCodeBench v5 | 70.7 | Code |
| CodeForces | 2,056 | Competitive programming |
| BFCL v3 | 70.8 | Function calling |
Qwen3's flagship MoE model competes with frontier proprietary models on reasoning-heavy benchmarks while using only 22B active parameters per token. The strong-to-weak distillation pipeline means that even the smaller dense variants (e.g., Qwen3-4B, Qwen3-8B) substantially outperform their Qwen2.5 predecessors on reasoning tasks, making capable reasoning models accessible at consumer hardware scales.
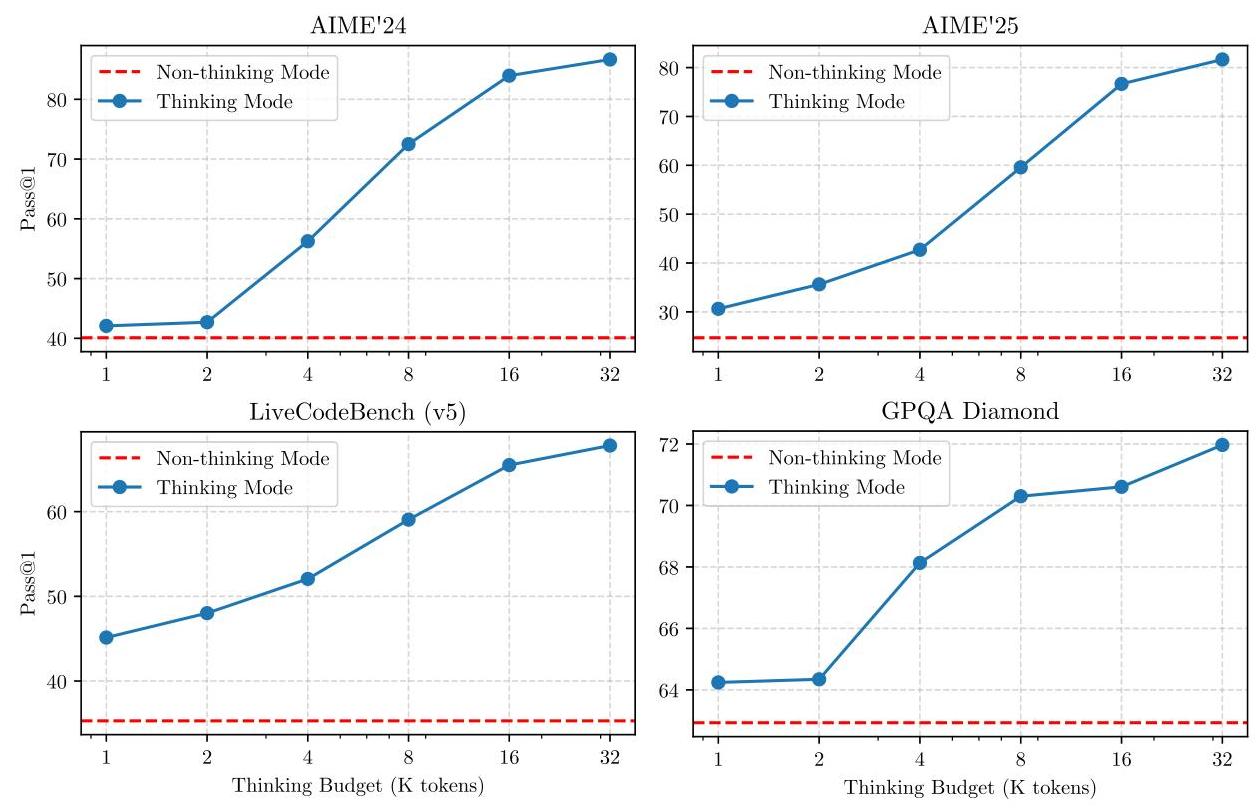
Key performance highlights: - Mathematics: Near-top-tier on AIME, demonstrating deep multi-step reasoning - Code: Strong competitive programming results, suggesting the reasoning RL stage significantly boosts algorithmic problem-solving - Multilingual: Expanded from 29 to 119 languages, broadening accessibility and downstream applicability - Inference flexibility: The thinking mode allows users to trade off latency for quality, adapting to different use cases without model switching
Limitations & Open Questions
- Inference cost of thinking mode: Extended chain-of-thought reasoning can generate very long outputs, increasing latency and cost. The optimal strategy for deciding when to "think" vs. respond directly is not fully resolved.
- MoE routing at extreme scale: Whether the routing patterns generalize well to all domains and languages at 235B scale, or whether certain expert combinations are underutilized, is not deeply analyzed.
- Reasoning verification: The RL-trained reasoning is optimized against outcome-based rewards, but whether the intermediate reasoning steps are always faithful (vs. post-hoc rationalization) is an open question.
- Distillation ceiling: Strong-to-weak distillation transfers significant capability to smaller models, but the gap between the smallest (0.6B) and largest (235B) models on complex reasoning tasks likely remains large.
- Multimodal gap: Qwen3 is text-only; the Qwen ecosystem has separate multimodal models (Qwen2.5-VL), and unifying text reasoning with multimodal perception into a single model is flagged as future work.
Connections
Related papers in the wiki: - Mixtral Of Experts -- Qwen3's MoE architecture builds on the sparse MoE paradigm demonstrated by Mixtral, with top-K expert routing and load-balancing losses - Attention Is All You Need -- foundational transformer architecture that all Qwen models are based on - Scaling Laws For Neural Language Models -- scaling-law reasoning that motivates the model family spanning 0.6B to 235B parameters - Training Compute Optimal Large Language Models -- compute-optimal training principles that inform the 36T token pre-training corpus - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- the chain-of-thought reasoning paradigm that Qwen3's thinking mode operationalizes via RL - Training Language Models To Follow Instructions With Human Feedback -- RLHF alignment pipeline that Qwen3's post-training stages extend with reasoning-specific RL - Language Models Are Few Shot Learners -- GPT-3 established the pretrain-at-scale paradigm that Qwen3 continues - Lora Low Rank Adaptation Of Large Language Models -- LoRA is the standard method for adapting Qwen3 models to downstream tasks - Foundation Models -- Qwen3 as a frontier open-weight foundation model - Machine Learning -- scaling, MoE, and RL alignment as core ML paradigms