Training Language Models to Follow Instructions with Human Feedback
Overview
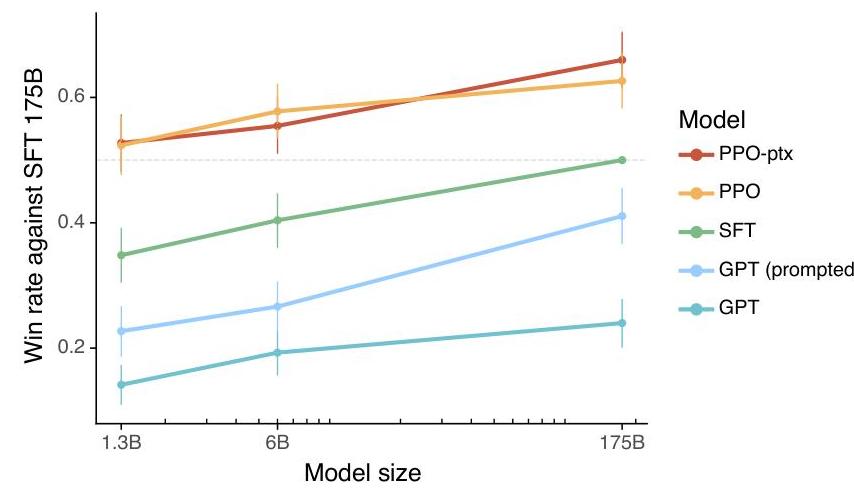
Large language models like GPT-3 are trained on vast internet corpora to predict the next token, but this objective is fundamentally misaligned with the goal of following user instructions helpfully and safely. Ouyang et al. (2022) introduced InstructGPT, a family of models trained using Reinforcement Learning from Human Feedback (RLHF) to align language model outputs with human intent. The core insight is that a relatively small amount of human preference data, combined with a reward model and PPO-based reinforcement learning, can dramatically improve a model's ability to follow instructions -- even making a 1.3B parameter InstructGPT model preferred by human labelers over the 175B parameter GPT-3, while the 175B InstructGPT is preferred over the 175B GPT-3 85% of the time and preferred over few-shot GPT-3 71% of the time.
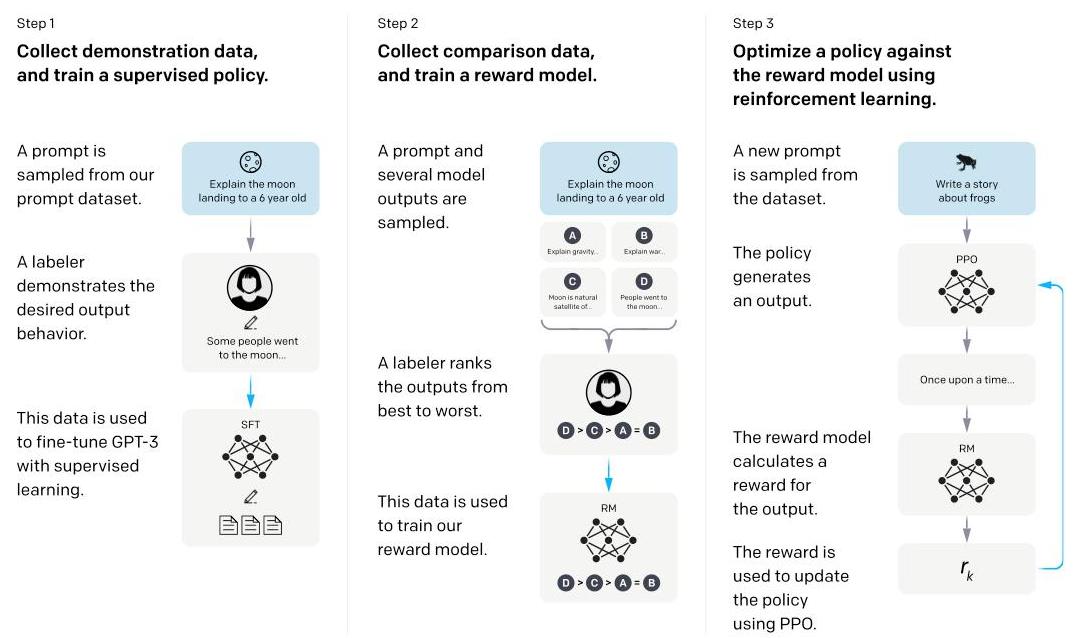
The paper establishes a three-stage alignment pipeline that became the standard recipe for the field: (1) collect human demonstrations of desired behavior and fine-tune a pretrained model via supervised learning (SFT), (2) collect human rankings of model outputs and train a reward model (RM) to predict these preferences, and (3) optimize the SFT model against the reward model using Proximal Policy Optimization (PPO), with a KL penalty to prevent excessive drift from the original model. This pipeline proved that alignment is not just about making models safer -- aligned models are also more useful, more truthful, and less toxic, demonstrating that helpfulness and safety can be complementary rather than competing objectives.
InstructGPT is one of the most influential papers of the LLM era. It operationalized the concept of AI alignment for language models, established RLHF as the dominant paradigm for post-training, and directly led to ChatGPT and the broader wave of instruction-tuned models. The three-stage pipeline (SFT -> RM -> PPO) has been adopted, adapted, or iterated upon by virtually every major LLM developer. Beyond language, the RLHF framework has influenced alignment approaches in robotics VLAs (e.g., AlphaDrive's GRPO) and embodied AI (e.g., pi0.6's RECAP offline RL), making this paper foundational for the broader autonomy-relevant ML stack.
Key Contributions
- RLHF pipeline for language models: Formalized the three-stage process (SFT -> reward modeling -> PPO optimization) that became the industry standard for aligning LLMs with human preferences
- Alignment tax is small or negative: Showed that RLHF alignment improves helpfulness, truthfulness, and reduced toxicity simultaneously, with minimal degradation on standard NLP benchmarks when using PPO-ptx (mixing pretraining gradients)
- Small aligned > large unaligned: Demonstrated that a 1.3B InstructGPT model is preferred over the 175B GPT-3 by human evaluators, establishing that alignment quality matters more than raw scale for user-facing applications
- Reward model as proxy for human judgment: Trained a 6B parameter reward model on ~33K human comparison pairs that serves as a scalable proxy for human preferences during RL optimization
- Public NLP benchmark regression analysis: Introduced PPO-ptx, which mixes PPO gradients with pretraining gradients to prevent catastrophic forgetting of general language capabilities during alignment
Architecture / Method
InstructGPT: Three-Stage RLHF Alignment Pipeline
┌─────────────────────────────────────────────────────────┐
│ Stage 1: Supervised Fine-Tuning (SFT) │
│ │
│ Pretrained ~13K human-written │
│ GPT-3 ──► demonstrations ──► SFT Model │
│ (prompt, ideal response) │
└──────────────────────────┬──────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────┐
│ Stage 2: Reward Model (RM) Training │
│ │
│ SFT Model generates K outputs per prompt │
│ │ │
│ ▼ │
│ Humans rank outputs: y_1 > y_2 > ... > y_K │
│ │ │
│ ▼ ~33K comparison pairs │
│ Train 6B Reward Model: r_θ(prompt, response) ──► scalar│
│ Loss: Bradley-Terry pairwise ranking │
└──────────────────────────┬──────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────┐
│ Stage 3: RL Fine-Tuning via PPO │
│ │
│ SFT Model ──► Generate response y │
│ │ │
│ ▼ │
│ Reward = r_θ(x, y) - β * KL(π_φ || π_SFT) │
│ │ │
│ ▼ PPO-ptx: + γ * pretrain loss (prevent forget) │
│ Optimized InstructGPT Model │
└─────────────────────────────────────────────────────────┘
Stage 1: Supervised Fine-Tuning (SFT)
A pretrained GPT-3 model is fine-tuned on a dataset of ~13K human-written demonstrations. Labelers were given prompts (user instructions) and asked to write ideal responses. The model is trained with standard cross-entropy loss on these demonstrations for 16 epochs (with overfitting on validation loss observed after 1 epoch, but continued training improving RM scores).
Stage 2: Reward Model (RM) Training
Human labelers rank 4-9 model outputs for the same prompt from best to worst. A 6B parameter model (initialized from the SFT model with the unembedding layer removed) is trained to predict these rankings. The loss function is the pairwise ranking loss (Bradley-Terry model):
$$\mathcal{L}(\theta) = -\frac{1}{\binom{K}{2}} E_{(x, y_w, y_l) \sim D} [\log(\sigma(r_\theta(x, y_w) - r_\theta(x, y_l)))]$$
where $r_\theta(x, y)$ is the scalar reward for prompt $x$ and completion $y$, and $y_w$ is ranked higher than $y_l$. All $\binom{K}{2}$ comparisons from a single labeler ranking are used as a single batch element to prevent overfitting. The dataset contains ~33K comparison pairs.
Stage 3: RL Fine-Tuning via PPO
The SFT model is further optimized to maximize the reward model's score using PPO. The objective includes a KL divergence penalty to prevent the policy from diverging too far from the SFT model:
$$\text{objective}(\phi) = E_{(x, y) \sim D_{\pi_\phi}} [r_\theta(x, y) - \beta \log(\pi_\phi(y|x) / \pi_{\text{SFT}}(y|x))]$$
PPO-ptx variant: To mitigate performance regression on public NLP benchmarks, the authors mix PPO gradients with pretraining gradients (next-token prediction on the pretraining distribution):
$$\text{objective}(\phi) = E_{(x, y) \sim D_{\pi_\phi}} [r_\theta(x, y) - \beta \text{KL}] + \gamma E_{x \sim D_{\text{pretrain}}} [\log \pi_\phi(x)]$$
where $\gamma$ controls the pretraining gradient weight.
Model Sizes
Three InstructGPT model sizes were trained: 1.3B, 6B, and 175B parameters. All start from corresponding GPT-3 checkpoints. The reward model is always 6B parameters (the 175B RM was found to be unstable during training).
Results
Human Preference Evaluations
| Model | Win rate vs. 175B GPT-3 (non-prompted) | Win rate vs. 175B few-shot GPT-3 |
|---|---|---|
| GPT-3 (175B, non-prompted) | 50% (baseline) | -- |
| GPT-3 (175B, few-shot prompted) | -- | 50% (baseline) |
| InstructGPT (1.3B, PPO-ptx) | preferred (see Figure 1) | -- |
| InstructGPT (175B, PPO-ptx) | 85±3% | 71±4% |
Truthfulness and Toxicity
- TruthfulQA: InstructGPT (175B) generates truthful and informative outputs 29% more often than GPT-3 (from ~22% to ~51%), though hallucination remains present
- RealToxicityPrompts: InstructGPT produces 25% fewer toxic outputs than GPT-3 when prompted; toxicity can be further reduced via explicit instruction
- Bias: Minimal change in gender, race, and religion bias benchmarks (BBQ, Winogender) -- RLHF alone does not substantially reduce pretraining biases
NLP Benchmark Performance
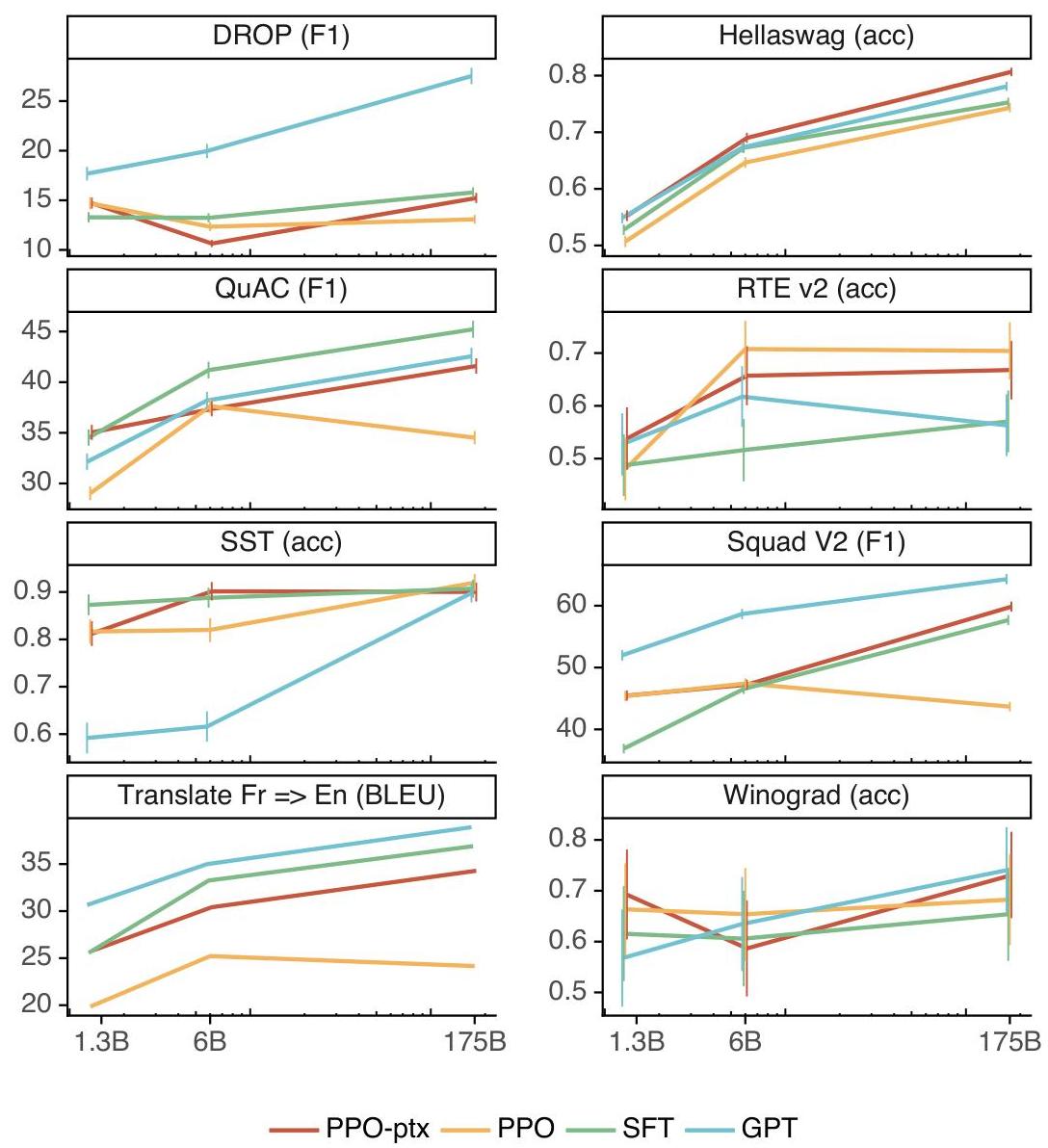
PPO-ptx maintains near-baseline performance on standard benchmarks (HellaSwag, LAMBADA, etc.), while PPO without pretraining gradients shows moderate regression, validating the mixing approach.
Key Ablation: Reward Model Size
The 6B reward model produces more stable training than the 175B reward model. Larger reward models showed instability during RL optimization, suggesting that reward model scaling requires careful tuning independent of policy model scaling.
Limitations & Open Questions
- Alignment is partial: RLHF reduces but does not eliminate harmful outputs; the model can still be prompted to generate toxic or biased content, especially with adversarial inputs
- Labeler disagreement: Human preferences are not uniform -- significant labeler disagreement exists, and the trained model reflects the preferences of its specific labeler pool (~40 contractors), raising questions about whose values are being optimized
- Reward hacking: As PPO training continues, the model can learn to exploit reward model weaknesses rather than genuinely improve, producing outputs that score highly but are not actually better by human judgment
- Cost of human feedback: The reliance on human labelers is expensive and slow; subsequent work on AI feedback (Constitutional AI) and preference optimization without explicit reward models (DPO) addresses this
- Evaluation challenges: Automated metrics correlate poorly with human judgments of alignment; human evaluation remains necessary but is difficult to scale
- "Alignment tax" on capabilities: While PPO-ptx mitigates benchmark regression, the fundamental tension between alignment and raw capability remains a concern for the field
Connections
Related papers in the wiki: - Language Models Are Few Shot Learners -- GPT-3 is the base model that InstructGPT aligns; InstructGPT directly addresses GPT-3's tendency to produce unhelpful or untruthful outputs - Scaling Laws For Neural Language Models -- InstructGPT demonstrates that alignment quality can matter more than raw scale, complicating pure scaling-law reasoning - Attention Is All You Need -- Transformer architecture underlying all models in the InstructGPT family - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- Contemporary NeurIPS 2022 paper; CoT and RLHF represent complementary approaches to improving LLM capabilities (reasoning vs. alignment) - Training Compute Optimal Large Language Models -- Chinchilla (2022) optimizes pre-training efficiency; InstructGPT optimizes post-training alignment -- together they define the modern LLM training recipe - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT established pretrain-then-finetune; InstructGPT extends this to pretrain-then-align via RLHF - Foundation Models -- InstructGPT is foundational to the alignment stage of the foundation model pipeline - Machine Learning -- RLHF represents a fundamental shift in how ML models are trained for deployment