Overview
DeepSeek-R1 demonstrates that sophisticated reasoning capabilities -- including self-verification, reflection, and extended chain-of-thought -- can emerge in large language models through pure outcome-based reinforcement learning, without any human-annotated reasoning trajectories. This challenges the prevailing assumption that high-quality reasoning requires supervised training on curated step-by-step demonstrations, as used in OpenAI's o1 and similar systems.
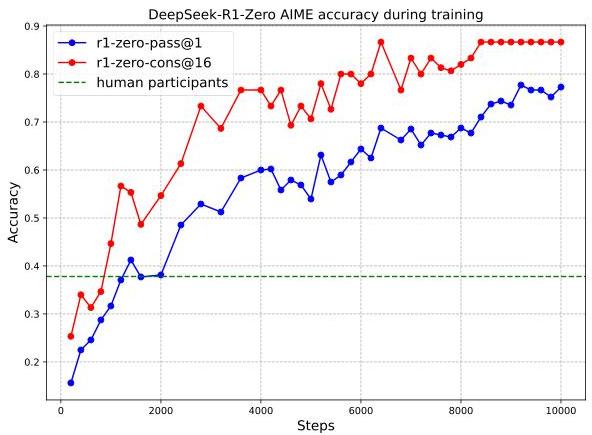
Built on DeepSeek-V3-Base (a 671B-parameter Mixture-of-Experts model), the work introduces two model variants. DeepSeek-R1-Zero is trained with RL alone (no SFT warmup), using Group Relative Policy Optimization (GRPO) with rule-based rewards for correctness and format compliance. DeepSeek-R1-Zero achieves 77.9% pass@1 on AIME 2024 (up from 15.6% at baseline), with emergent behaviors including self-reflection ("Wait, let me reconsider..."), verification of intermediate steps, and adaptive compute allocation (spending more tokens on harder problems). The full DeepSeek-R1 model uses a multi-stage pipeline -- cold-start SFT on a small set of long-CoT examples, followed by reasoning-focused RL, then rejection sampling to generate SFT data for all capabilities, and finally a second RL stage for alignment -- reaching 79.8% on AIME 2024, 97.3% on MATH-500, and performance competitive with OpenAI-o1-1217 across math, coding, and science benchmarks.
A particularly significant contribution is the demonstration that reasoning capabilities can be distilled into much smaller models. Using rejection sampling from DeepSeek-R1 to generate training data, the authors fine-tune Qwen and Llama models from 1.5B to 70B parameters. The distilled 14B model outperforms QwQ-32B-Preview on several benchmarks, and even the 1.5B distilled model surpasses GPT-4o and Claude-3.5-Sonnet on math reasoning tasks, suggesting that once reasoning is unlocked via RL in a large model, it can be compressed effectively.
Key Contributions
- Emergent reasoning from pure RL: DeepSeek-R1-Zero shows that reinforcement learning with simple rule-based rewards (no process reward models, no human demonstrations) can produce sophisticated reasoning behaviors including self-verification and reflection
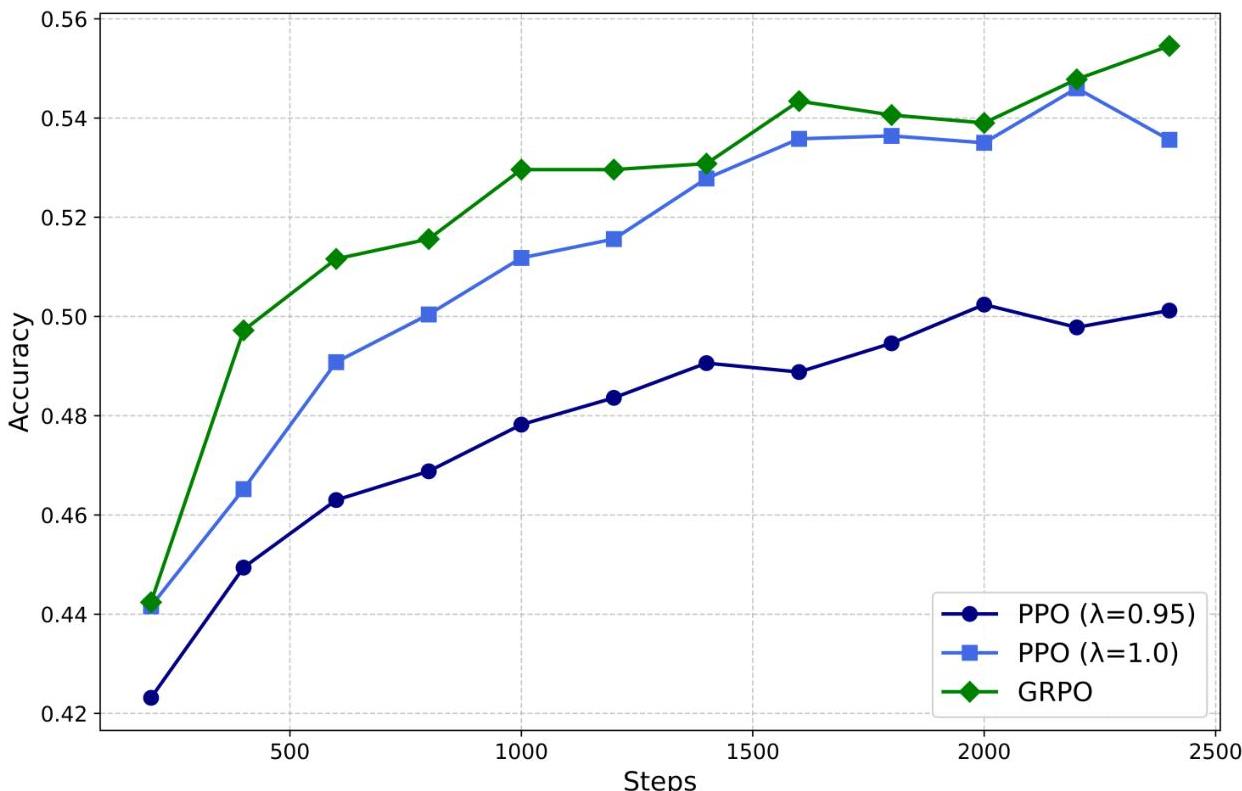
- Group Relative Policy Optimization (GRPO): A variant of PPO that eliminates the critic model by estimating baselines from group scores within each prompt's sampled outputs, reducing training compute by roughly half
- Multi-stage training pipeline: A four-stage recipe (cold-start SFT → reasoning RL → rejection sampling SFT → alignment RL) that combines the strengths of RL-discovered reasoning with supervised polishing for readability and general capability
- Effective distillation to small models: Demonstrates that RL-derived reasoning can be transferred to 1.5B-70B models via supervised fine-tuning on R1-generated data, with the distilled models significantly outperforming their base counterparts and even some much larger models
- Open-weight release: All distilled models (1.5B to 70B) released as open weights, enabling the broader research community to build on reasoning-capable small models
Architecture / Method
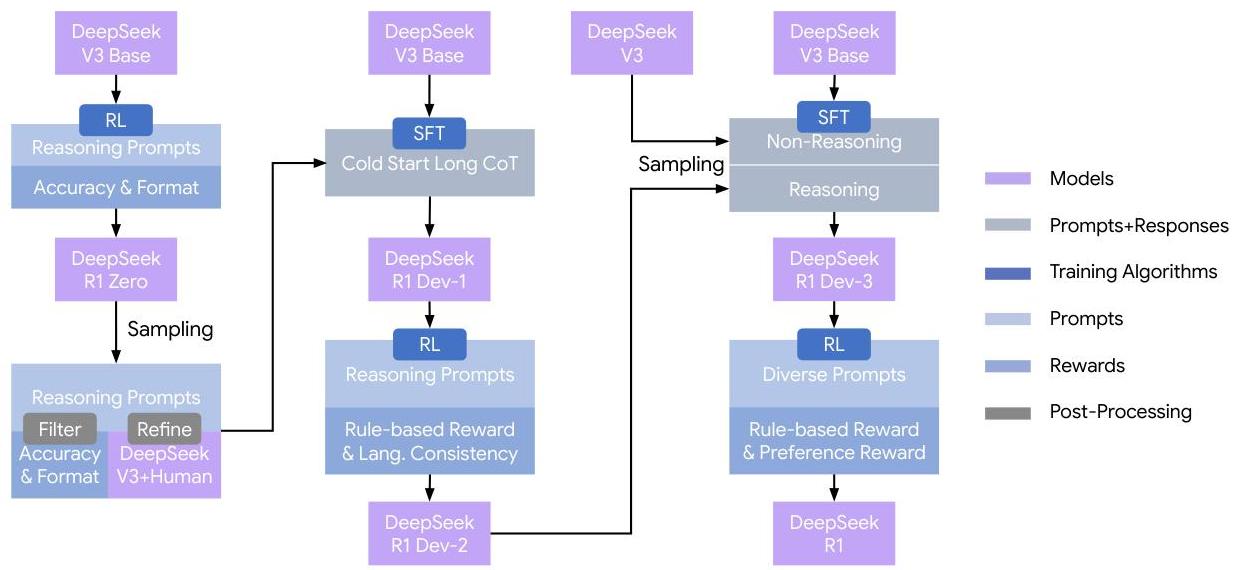
DeepSeek-R1 Multi-Stage Training Pipeline:
Stage 1 Stage 2 Stage 3 Stage 4
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Cold-Start │ │ Reasoning │ │ Rejection │ │ Alignment │
│ SFT │──►│ RL (GRPO) │──►│ Sampling + │──►│ RL │
│ │ │ │ │ SFT │ │ │
│ Small set of │ │ Math, Code, │ │ ~800K mixed │ │ Rule-based + │
│ long-CoT │ │ Science,Logic│ │ samples from │ │ Neural RM │
│ examples │ │ Rule-based │ │ RL ckpt + │ │ (helpfulness/│
│ │ │ rewards only │ │ general data │ │ harmlessness)│
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
GRPO (Group Relative Policy Optimization):
┌──────────┐ Sample G outputs ┌─────────────────────────┐
│ Prompt q │────────────────────────────►│ {o₁, o₂, ..., o_G} │
└──────────┘ from old policy │ ↓ score each │
│ {r₁, r₂, ..., r_G} │
└───────────┬─────────────┘
▼
┌─────────────────────────┐
│ Aᵢ = (rᵢ - mean) / std │
│ (group-relative adv.) │
└───────────┬─────────────┘
▼
┌─────────────────────────┐
│ Clipped surrogate loss │
│ + KL penalty vs ref │
│ (No critic network!) │
└─────────────────────────┘
DeepSeek-R1-Zero (pure RL, no SFT):
┌───────────────┐ GRPO ┌──────────────────────────────────┐
│ DeepSeek-V3 │──────────►│ Emergent behaviors: │
│ Base (671B │ Rule- │ - Self-verification │
│ MoE) │ based │ - Reflection ("Wait...") │
└───────────────┘ rewards │ - Adaptive compute allocation │
only └──────────────────────────────────┘
GRPO: Group Relative Policy Optimization
DeepSeek-R1 replaces the standard PPO critic with a group-based baseline estimation. For each prompt q, the model samples a group of G outputs {o_1, ..., o_G} from the old policy. Each output receives a reward r_i. The advantage for output o_i is computed as:
A_i = (r_i - mean(r_1, ..., r_G)) / std(r_1, ..., r_G)
The policy is then optimized with a clipped surrogate objective (as in PPO) plus a KL penalty against a reference policy, but without needing a separate value network. This roughly halves the training memory and compute compared to standard PPO.
Reward Design
The reward system is deliberately simple -- no neural reward models are used for reasoning RL:
- Accuracy rewards: For math problems, the final answer is checked against the ground truth (deterministic verification). For coding tasks, outputs are evaluated against test cases via a compiler.
- Format rewards: A small reward ensures the model places its reasoning within <think>...</think> tags and its final answer within designated tags.
- No process reward models or outcome reward models based on neural networks are employed for the core reasoning RL stage. This simplicity is itself a key finding: complex reward engineering is unnecessary for reasoning emergence.
Multi-Stage Pipeline (DeepSeek-R1)
- Cold-start SFT: Fine-tune DeepSeek-V3-Base on a small curated dataset of long chain-of-thought examples (thousands, not millions) to establish the format and basic reasoning pattern. This avoids the readability issues observed in R1-Zero's outputs.
- Reasoning-focused RL: Apply GRPO on math, code, science, and logic tasks with rule-based rewards. This is where the core reasoning capability develops.
- Rejection sampling + SFT: Sample many outputs from the RL-trained checkpoint, filter for correctness, and combine with general-capability SFT data (writing, QA, translation, etc.) to create a comprehensive fine-tuning dataset (~800K samples). Fine-tune from the base model on this combined dataset.
- Alignment RL: A final RL stage using both rule-based rewards (for reasoning tasks) and a neural reward model (for general helpfulness/harmlessness), similar to standard RLHF, to polish the model for deployment.
Emergent Behaviors in R1-Zero
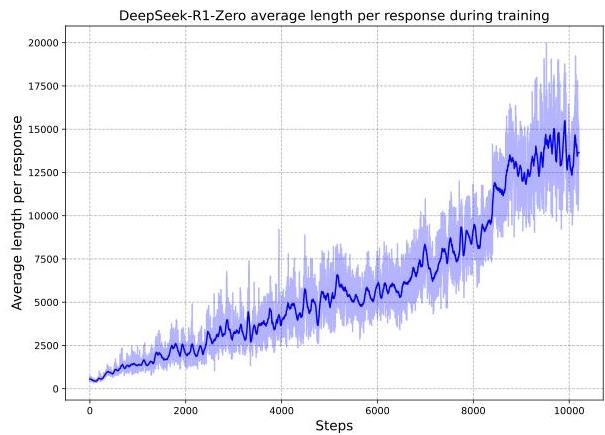
During RL training, several behaviors emerge without explicit supervision: - Self-verification: The model re-checks its own intermediate steps - Reflection/backtracking: When the model detects an error, it revisits earlier reasoning ("Wait, that doesn't seem right...") - Adaptive compute: The model generates longer reasoning chains for harder problems, effectively performing test-time compute scaling - "Aha moment": A documented phase transition where the model's average response length suddenly increases as it discovers that longer reasoning leads to higher rewards
Results
Main Results (DeepSeek-R1 vs. frontier models)
| Model | AIME 2024 (pass@1) | MATH-500 | MMLU | LiveCodeBench | Codeforces | GPQA Diamond |
|---|---|---|---|---|---|---|
| DeepSeek-R1 | 79.8% | 97.3% | 90.8% | 65.9% | 2029 Elo | 71.5% |
| OpenAI-o1-1217 | 79.2% | 96.4% | 91.8% | 63.4% | 2061 Elo | 75.7% |
| DeepSeek-R1-Zero | 77.9% | 95.9% | -- | -- | -- | -- |
| DeepSeek-V3 | 39.2% | 90.2% | 88.5% | -- | -- | 59.1% |
| Claude-3.5-Sonnet | 16.0% | 78.3% | 88.3% | -- | -- | 65.0% |
| GPT-4o | 9.3% | 74.6% | 87.2% | -- | -- | 53.6% |
Distillation Results
| Model | AIME 2024 | MATH-500 | LiveCodeBench | GPQA Diamond |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | 72.6% | 94.3% | 57.2% | 62.1% |
| DeepSeek-R1-Distill-Qwen-14B | 69.7% | 93.9% | 53.1% | 59.1% |
| DeepSeek-R1-Distill-Qwen-7B | 55.5% | 92.8% | 37.6% | 49.1% |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9% | 83.9% | 16.9% | 33.8% |
| QwQ-32B-Preview | 50.0% | 90.6% | 41.9% | 54.5% |
| GPT-4o-0513 | 9.3% | 74.6% | -- | 53.6% |
The distilled 14B model outperforms QwQ-32B-Preview across all benchmarks despite being less than half the size. The 1.5B distilled model surpasses GPT-4o on AIME and MATH.
Limitations & Open Questions
- Language mixing: R1-Zero and early R1 checkpoints sometimes mix languages within reasoning chains (e.g., switching between Chinese and English), which the multi-stage pipeline mitigates but does not fully eliminate
- Long-context performance: The model's reasoning chains can become very long (thousands of tokens), which may cause issues with context window limits and inference cost
- Reward hacking: With longer RL training, the model can develop reward-hacking behaviors (e.g., producing outputs that satisfy format checks without genuine reasoning). The multi-stage pipeline is partly designed to mitigate this
- General capability trade-offs: Pure RL training (R1-Zero) degrades general capabilities (writing, QA) even as reasoning improves; the multi-stage pipeline is needed to preserve breadth
- Distillation ceiling: While distilled models are impressive, they do not match the full R1 model, and it remains unclear how much reasoning capability can be compressed
- Reasoning verification: The model's self-verification is not always reliable -- it can confidently "verify" incorrect answers
- Software engineering tasks: Performance on complex, multi-file engineering tasks (SWE-bench) lags behind frontier models, suggesting reasoning alone is insufficient for tool-heavy tasks
Connections
Related papers in the wiki: - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- DeepSeek-R1 shows that chain-of-thought reasoning can emerge from RL without being explicitly prompted or demonstrated, extending the CoT paradigm from prompting to training - Training Language Models To Follow Instructions With Human Feedback -- InstructGPT established the SFT→RM→PPO pipeline that DeepSeek-R1's alignment stage builds upon; R1 shows that for reasoning tasks, rule-based rewards can replace learned reward models - Direct Preference Optimization Your Language Model Is Secretly A Reward Model -- DPO simplified RLHF by eliminating the reward model; DeepSeek-R1 takes a different path by simplifying the reward (rule-based) while keeping RL, showing both approaches can reduce alignment complexity - Language Models Are Few Shot Learners -- GPT-3 demonstrated emergent capabilities from scale; R1 demonstrates emergent reasoning capabilities from RL, suggesting that training objective (not just scale) is a key axis for capability emergence - Scaling Laws For Neural Language Models -- R1's test-time compute scaling (longer reasoning = better answers) complements traditional scaling laws by adding inference-time compute as a new scaling dimension - Alpamayo R1 Bridging Reasoning And Action Prediction For Autonomous Driving -- Applies R1-style reasoning to autonomous driving, demonstrating that RL-enhanced reasoning transfers to embodied domains - Foundation Models -- DeepSeek-R1 represents a paradigm shift in foundation model training: from "pretrain + align" to "pretrain + RL for reasoning + align" - Machine Learning -- Extends the reasoning and chain-of-thought section with RL-based reasoning emergence