Overview
Aligning large language models (LLMs) with human preferences has traditionally required reinforcement learning from human feedback (RLHF), a complex multi-stage pipeline: first, fine-tune a supervised model on demonstrations; second, train a separate reward model on human preference data; third, optimize the language model policy against the reward model using PPO while constraining divergence from the reference policy via a KL penalty. This pipeline is computationally expensive, brittle to hyperparameter choices, and difficult to scale. Direct Preference Optimization (DPO) eliminates the explicit reward modeling and RL stages entirely, replacing them with a simple classification-style loss applied directly to the language model.
The core insight is mathematical: the optimal solution to the KL-constrained reward maximization objective used in RLHF has a closed-form relationship between the reward function and the optimal policy. By inverting this relationship, the authors show that the reward can be expressed as a function of the log-ratio between the policy and the reference model, plus a normalization constant. Substituting this reparameterized reward into the Bradley-Terry preference model yields a loss function where the partition function cancels, producing a binary cross-entropy objective that directly optimizes policy parameters using only preference pairs -- no reward model, no sampling, no RL.
DPO matches or exceeds PPO-based RLHF across sentiment generation, summarization, and dialogue tasks. On summarization, DPO achieves a 61% win rate against human-written summaries (GPT-4 evaluation) and 58% against PPO samples in human evaluation, surpassing PPO's 57% baseline. On dialogue, DPO matches the expensive "Best of 128" sampling strategy while requiring only a single forward pass at inference. The simplicity and effectiveness of DPO made it one of the most influential alignment methods of 2023, adopted widely across the LLM ecosystem (Llama 2, Zephyr, and many others) and spawning a family of follow-up methods (IPO, KTO, ORPO, SimPO).
Key Contributions
- Closed-form reward-policy mapping: Showed that the optimal policy under KL-constrained reward maximization implies a direct, invertible relationship between the reward function and the policy/reference log-ratio, eliminating the need for an explicit reward model.
- DPO loss function: Derived a simple binary cross-entropy loss over preference pairs that optimizes the policy directly, with the implicit reward increasing the relative log-probability of preferred completions and decreasing that of dispreferred ones.
- Theoretical equivalence: Proved that DPO optimizes the same objective as RLHF (under the Bradley-Terry preference model) but in a single supervised learning stage, without any RL sampling or reward model training.
- Empirical validation across tasks: Demonstrated competitive or superior performance to PPO on sentiment control (IMDb), summarization (TL;DR with GPT-J 6B), and single-turn dialogue (Anthropic HH with Pythia 2.8B).
- Frontier-efficient alignment: Achieved the most efficient reward-KL tradeoff frontier on sentiment generation, strictly dominating PPO across all KL budgets.
Architecture / Method
Standard RLHF Pipeline (3 stages):
┌──────────┐ ┌──────────────┐ ┌────────────────────────┐
│ Stage 1 │ │ Stage 2 │ │ Stage 3 │
│ SFT │───►│ Train Reward │───►│ RL (PPO) against │
│ π_ref │ │ Model r(x,y) │ │ reward + KL penalty │
└──────────┘ └──────────────┘ └────────────────────────┘
Demos Pref. pairs Sampling + RL optimization
(y_w, y_l) (complex, unstable)
DPO Pipeline (2 stages):
┌──────────┐ ┌─────────────────────────────────────────┐
│ Stage 1 │ │ Stage 2: DPO │
│ SFT │───►│ │
│ π_ref │ │ Preference pairs: (x, y_w, y_l) │
└──────────┘ │ │ │
│ ▼ │
│ L = -log σ( β · [log π_θ(y_w|x) │
│ ───────────── │
│ π_ref(y_w|x) │
│ │
│ - log π_θ(y_l|x) ] ) │
│ ───────────── │
│ π_ref(y_l|x) │
│ │
│ ► No reward model │
│ ► No RL sampling │
│ ► Simple cross-entropy loss │
└─────────────────────────────────────────┘

The RLHF Objective
Standard RLHF optimizes:
max_π E_{x~D, y~π(y|x)} [ r(x, y) ] - β · D_KL[ π(y|x) || π_ref(y|x) ]
where r(x, y) is a learned reward model, π_ref is the supervised fine-tuned reference policy, and β controls the KL penalty strength.
The DPO Reparameterization
The optimal solution to this constrained problem has the closed form:
π*(y|x) = (1/Z(x)) · π_ref(y|x) · exp( r(x, y) / β )
Inverting this yields the implicit reward:
r(x, y) = β · log( π(y|x) / π_ref(y|x) ) + β · log Z(x)
The DPO Loss
Substituting the implicit reward into the Bradley-Terry model p(y_w ≻ y_l | x) = σ(r(x, y_w) - r(x, y_l)), the partition function Z(x) cancels, giving:
L_DPO(π_θ; π_ref) = -E_{(x, y_w, y_l) ~ D} [ log σ( β · ( log(π_θ(y_w|x)/π_ref(y_w|x)) - log(π_θ(y_l|x)/π_ref(y_l|x)) ) ) ]
This is a binary cross-entropy loss. The gradient increases the likelihood of preferred completions y_w and decreases that of dispreferred completions y_l, weighted by how much the implicit reward model disagrees with the current policy -- examples the reward model gets wrong receive higher gradient weight.
Training Procedure
- Stage 1 (SFT): Fine-tune a pretrained LM on demonstration data to produce the reference policy
π_ref. - Stage 2 (DPO): Initialize
π_θ = π_ref. OptimizeL_DPOon a dataset of preference pairs(x, y_w, y_l)using standard gradient descent. No sampling from the policy is required during training.
The only hyperparameter beyond standard training settings is β, which controls how far the policy can deviate from the reference. Higher β means more conservative updates (staying closer to the reference).
Results
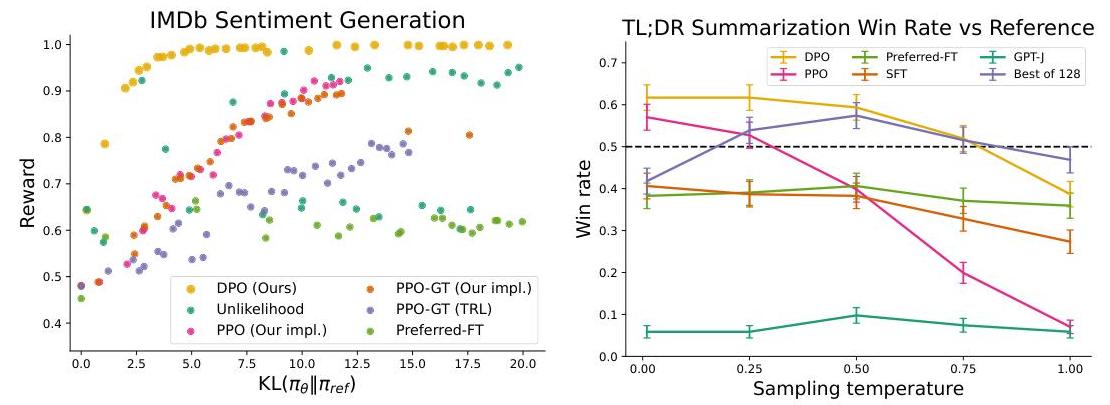
Sentiment Generation (IMDb, GPT-2-large)
DPO achieves the most efficient reward-KL frontier, strictly dominating PPO at every KL budget. It reaches higher reward for the same amount of KL divergence from the reference.
Summarization (TL;DR, GPT-J)
On the Reddit TL;DR summarization task (fine-tuning GPT-J from an SFT checkpoint), DPO achieves a GPT-4-judged win rate of approximately 61% versus reference summaries at temperature 0.0, exceeding PPO's best result of ~57% (also at its optimal temperature). DPO is also more robust to sampling temperature than PPO, which degrades quickly as temperature rises.
Dialogue (Anthropic HH, Pythia 2.8B)
On the Anthropic Helpful-Harmless single-turn dialogue task, DPO is reported as "the only computationally efficient method that improves over the preferred completions in the dataset," providing similar or better performance to the computationally demanding Best-of-128 sampling baseline while requiring only a single forward pass per response. PPO and Preferred-FT fail to match this on the same task.
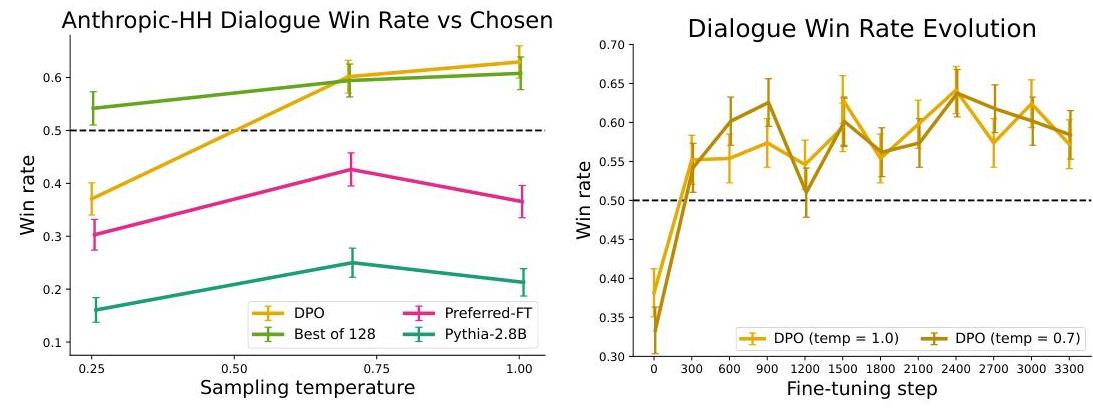
Key Ablation Insights
- β sensitivity: DPO performance is sensitive to the choice of β. Too low causes the policy to deviate too far from the reference (degenerate outputs); too high prevents meaningful alignment. The optimal β varies by task.
- Reference policy quality: DPO inherits the quality of the SFT reference policy. A weak SFT stage limits DPO's ceiling.
- Data quality matters: DPO requires high-quality preference pairs. Noisy or inconsistent preferences degrade performance more than they affect PPO-based RLHF (since PPO can partially recover through online exploration).
Limitations & Open Questions
- No online exploration: DPO is purely offline -- it only learns from the fixed preference dataset and never generates its own samples during training. This may limit its ability to improve beyond the quality of the preference data.
- Bradley-Terry assumption: The derivation assumes preferences follow the Bradley-Terry model, which may not capture intransitive or context-dependent human preferences.
- β sensitivity: Performance depends on careful tuning of β, and the optimal value is task-specific.
- Reference policy dependence: The quality of the SFT reference policy is a bottleneck. DPO cannot easily recover from a poor reference.
- Scaling to iterative/online DPO: Later work (online DPO, iterative DPO, RLHF-V) explored generating new preference data on-policy, partially addressing the offline limitation.
- Multi-turn and safety: The original experiments are single-turn; extending DPO to multi-turn dialogue and safety-critical alignment (where reward hacking is a concern) requires additional care.
Connections
Related papers in the wiki: - Language Models Are Few Shot Learners — GPT-3, the foundation model whose alignment DPO addresses - Scaling Laws For Neural Language Models — scaling laws that motivate larger models requiring alignment - Chain Of Thought Prompting Elicits Reasoning In Large Language Models — complementary approach to improving LLM outputs through prompting rather than preference optimization - Attention Is All You Need — the transformer architecture underlying all models DPO aligns - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding — pretraining paradigm that DPO builds upon (pretrain then align) - Training Compute Optimal Large Language Models — Chinchilla scaling laws; DPO enables efficient alignment of these large models - Foundation Models — broader context of alignment as a key challenge for foundation models - Machine Learning — DPO as a milestone in the alignment thread of ML