Attention Is All You Need
Citation
Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin, NeurIPS, 2017.
Canonical link
Overview
The Transformer is a pure attention-based encoder-decoder architecture that replaces recurrence and convolution entirely, enabling parallel training and superior performance on sequence-to-sequence tasks. This paper is the origin point of the transformer architecture, foundational for nearly every later LLM, VLM, and VLA system.
By eliminating recurrence, the Transformer enables massive parallelism during training, reducing wall-clock time by 8x over prior baselines. The multi-head self-attention mechanism allows the model to jointly attend to information from different representation subspaces at different positions, capturing both local and long-range dependencies in a single layer. The architecture consists of stacked encoder and decoder layers, each built from self-attention, cross-attention, and feedforward sublayers with residual connections and layer normalization.
The Transformer's impact is unparalleled in modern AI. Nearly every major model since -- BERT, GPT, PaLM, LLaMA, ViT, CLIP, DALL-E -- is a direct descendant. The architecture proved so general that it became the default backbone not just for NLP but for vision, audio, robotics, and multimodal systems, establishing the foundation for the current era of foundation models.
Key Contributions
- Multi-head self-attention: Scaled dot-product attention computed as Attention(Q,K,V) = softmax(QK^T / sqrt(d_k))V, with h parallel heads enabling the model to attend to different relationship types simultaneously
- Positional encoding via sinusoidal functions: Injects absolute position information without learned parameters, using sin/cos at different frequencies so the model can learn to attend by relative position
- Encoder-decoder stack: 6 encoder layers and 6 decoder layers, each with self-attention, cross-attention (decoder), and position-wise feedforward sublayers, all with residual connections and layer normalization
- Parallelizable training: Unlike RNNs which process tokens sequentially, all positions are processed simultaneously, enabling efficient GPU utilization
- Learning rate warmup schedule: Custom schedule with linear warmup followed by inverse-square-root decay, critical for stable transformer training
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ Transformer Architecture │
├──────────────────────────────────────────────────────────────────┤
│ │
│ ENCODER (x6) DECODER (x6) │
│ ┌───────────────────┐ ┌───────────────────┐ │
│ │ │ │ │ │
│ │ Input Embeddings │ │ Output Embeddings │ │
│ │ + Positional Enc │ │ + Positional Enc │ │
│ │ │ │ │ │ │ │
│ │ ▼ │ │ ▼ │ │
│ │ ┌───────────────┐ │ │ ┌───────────────┐ │ │
│ │ │ Multi-Head │ │ │ │ Masked Multi- │ │ │
│ │ │ Self-Attention │ │ │ │ Head Self-Attn │ │ │
│ │ │ + Add & Norm │ │ │ │ + Add & Norm │ │ │
│ │ └───────┬───────┘ │ │ └───────┬───────┘ │ │
│ │ ▼ │ │ ▼ │ │
│ │ ┌───────────────┐ │ K,V │ ┌───────────────┐ │ │
│ │ │ Feed-Forward │ │───────────►│ Cross-Attention│ │ │
│ │ │ + Add & Norm │ │ │ │ + Add & Norm │ │ │
│ │ └───────────────┘ │ │ └───────┬───────┘ │ │
│ │ │ │ ▼ │ │
│ └───────────────────┘ │ ┌───────────────┐ │ │
│ │ │ Feed-Forward │ │ │
│ │ │ + Add & Norm │ │ │
│ │ └───────┬───────┘ │ │
│ └─────────┼─────────┘ │
│ ▼ │
│ ┌────────────┐ │
│ Attention(Q,K,V) = │ Linear │ │
│ softmax(QK^T / sqrt(d_k)) V │ + Softmax │ │
│ └──────┬─────┘ │
│ d_model=512, h=8 heads, ▼ │
│ d_k=d_v=64, d_ff=2048 Output Probabilities │
└──────────────────────────────────────────────────────────────────┘
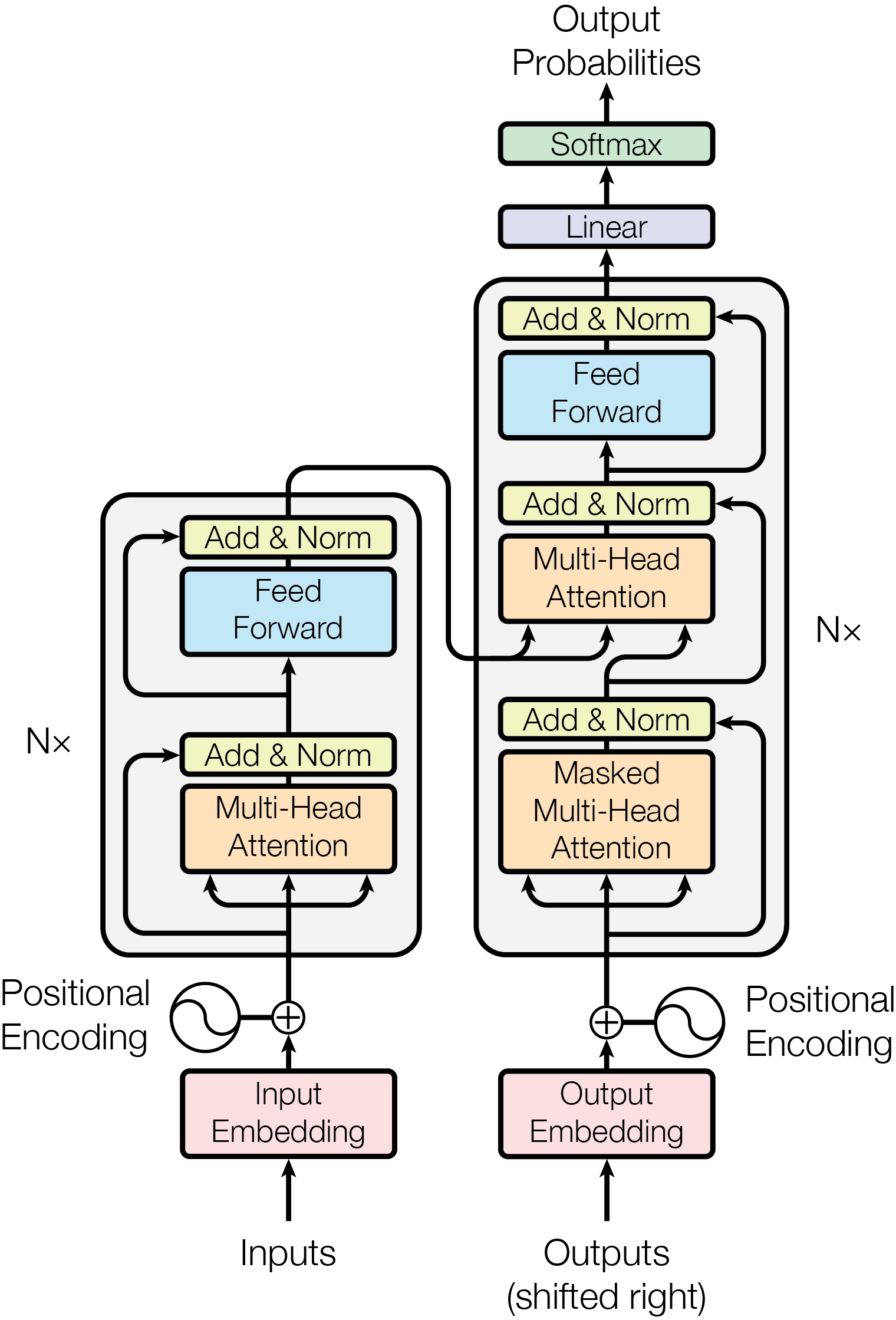
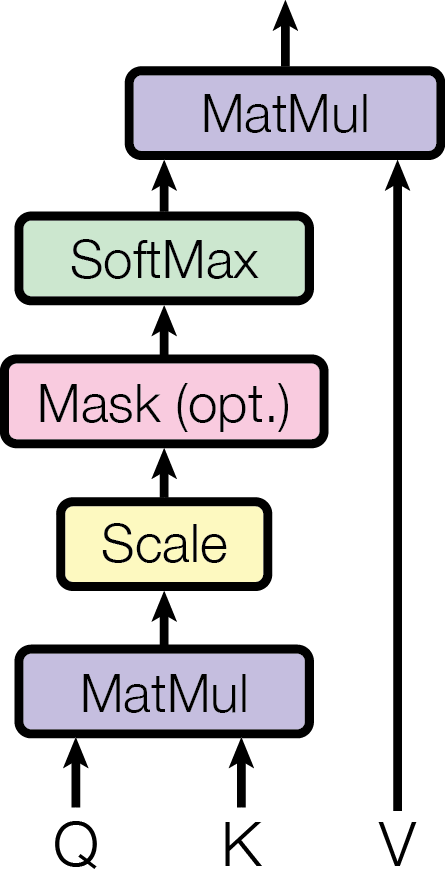
The Transformer consists of an encoder stack (N=6 identical layers) and a decoder stack (N=6 identical layers). Each encoder layer has two sublayers: (1) multi-head self-attention and (2) a position-wise feedforward network (two linear transformations with ReLU activation, d_ff=2048). Each decoder layer has three sublayers: (1) masked multi-head self-attention (preventing attention to future positions), (2) multi-head cross-attention over encoder outputs, and (3) position-wise FFN. All sublayers use residual connections and layer normalization (Post-LN in the original paper).
Multi-head attention projects Q, K, V through h=8 separate learned linear projections to dimension d_k=d_v=64, computes scaled dot-product attention in parallel for each head, concatenates, and projects back to d_model=512. The scaling factor 1/sqrt(d_k) prevents the dot products from growing large in magnitude, which would push softmax into regions with extremely small gradients.
Positional information is injected via sinusoidal functions: PE(pos, 2i) = sin(pos / 10000^{2i/d_model}) and PE(pos, 2i+1) = cos(pos / 10000^{2i/d_model}). This allows the model to extrapolate to sequence lengths not seen during training and encodes relative positions through linear transformations of the embeddings.
The base model has d_model=512, d_ff=2048, h=8, and 65M parameters. The big model has d_model=1024, d_ff=4096, h=16, and 213M parameters. Training uses Adam with beta_1=0.9, beta_2=0.98, and a custom learning rate schedule with 4000 warmup steps. Regularization includes dropout (P_drop=0.1) on sublayer outputs and attention weights, and label smoothing (epsilon=0.1).
Results
| Model | EN-DE BLEU | EN-FR BLEU | Training Cost |
|---|---|---|---|
| Transformer (big) | 28.4 | 41.8 | 3.5 days, 8 P100s |
| Transformer (base) | 27.3 | 38.1 | 12 hours, 8 P100s |
| Previous SOTA (ensemble) | 26.4 | 40.4 | - |
- SOTA on machine translation: 28.4 BLEU on WMT 2014 English-German (+2.0 over previous best) and 41.8 BLEU on English-French, establishing new state of the art on both benchmarks, surpassing even ensemble models combining multiple systems
- Training efficiency: The base model trained in just 12 hours on 8 NVIDIA P100 GPUs; the big model trained in 3.5 days -- an order of magnitude less compute than competing approaches
- Training data: WMT 2014 English-German (4.5M sentence pairs) and English-French (36M sentence pairs)
- Generalizes beyond translation: Strong results on English constituency parsing with minimal task-specific modifications demonstrate the architecture is a general-purpose sequence modeling framework
- Ablation insights: Multi-head attention significantly outperforms single-head variants, with h=8 heads providing optimal performance; the dimension of attention keys is important for model quality; dropout is essential for preventing overfitting
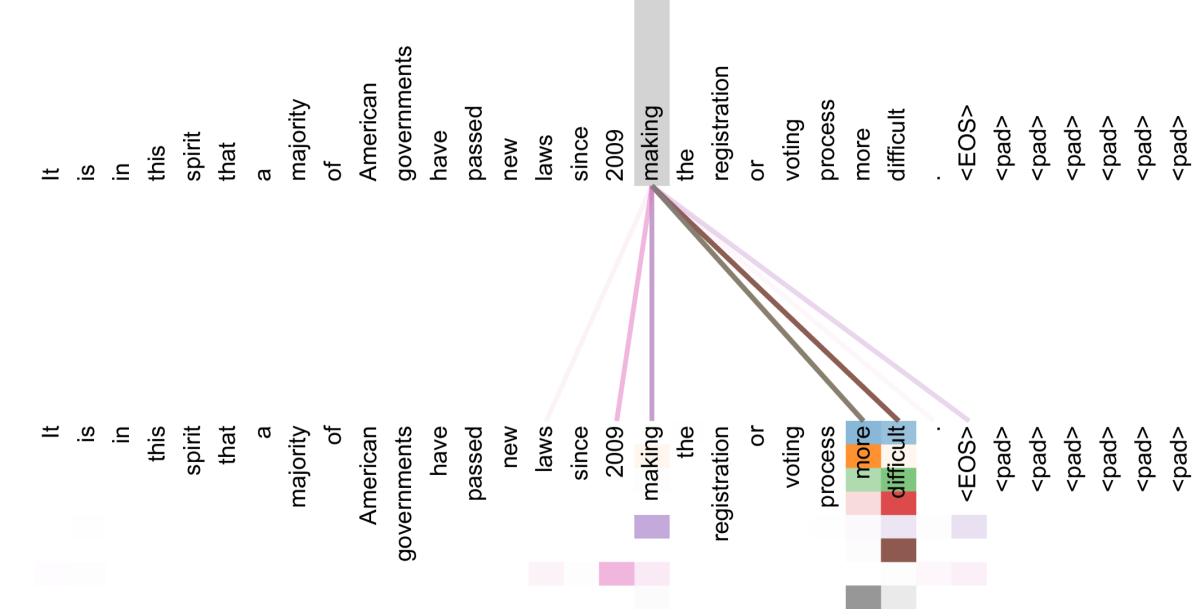
- Attention visualization: Different attention heads learn distinct linguistic functions -- some capture local syntactic dependencies, others learn longer-range semantic connections, and some implicitly perform anaphora resolution, syntactic parsing, and semantic role labeling without explicit supervision
Limitations & Open Questions
- Fixed-length positional encoding limits generalization to sequences longer than those seen during training (later addressed by RoPE, ALiBi)
- Quadratic memory and compute cost in sequence length due to full attention matrix (O(n^2)), motivating later work on sparse and linear attention
- The paper focuses on encoder-decoder for translation; the decoder-only and encoder-only variants that dominate today (GPT, BERT) were discovered subsequently