Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Citation
Amodei et al., ICML, 2016.
Overview
Deep Speech 2 is an end-to-end speech recognition system where a single RNN trained with CTC loss on spectrograms replaces the entire traditional ASR pipeline (acoustic model, pronunciation lexicon, language model) and approaches human-level word error rates on both English and Mandarin at production scale.
The system demonstrated that brute-force scaling of a simple deep learning architecture could match or beat highly engineered traditional speech systems. By training bidirectional RNNs with batch normalization on 11,940 hours of English and 9,400 hours of Mandarin audio, Deep Speech 2 achieved 5.33% WER compared to a 5.83% human baseline on LibriSpeech test-clean. The paper also pioneered HPC techniques for speech model training, achieving 7x speedup via synchronous multi-GPU training with all-reduce.
Deep Speech 2's significance extends beyond speech recognition. It established the template for scaling deep learning to production workloads and provided an early demonstration that end-to-end learning with sufficient data and compute could replace complex, modular, hand-engineered pipelines -- a lesson that would later apply to autonomous driving, protein folding, and many other domains.
Key Contributions
- End-to-end architecture: Spectrogram input directly to stacked bidirectional RNN layers with CTC output, eliminating hand-engineered features like MFCCs and complex decoding graphs (WFSTs)
- CTC loss for variable-length alignment: Connectionist Temporal Classification marginalizes over all possible audio-text alignments, removing the need for frame-level labels
- Batch normalization in RNNs: Applied batch norm to the non-recurrent connections of RNN layers, which was novel at the time and improved both convergence speed and final accuracy
- Cross-lingual generalization: The same architecture works for English (alphabetic, 29 tokens) and Mandarin (logographic, ~6000 characters) with minimal modification
- HPC training pipeline: Multi-GPU data-parallel training with synchronous SGD, all-reduce gradient aggregation, and SortaGrad curriculum (training on shorter utterances first) cut training from weeks to days
Architecture / Method
┌───────────────────────────────────┐
│ Audio Waveform │
└──────────────┬────────────────────┘
▼
┌───────────────────────────────────┐
│ Log-Spectrogram / Log-Mel │
│ Filterbank Features │
└──────────────┬────────────────────┘
▼
┌───────────────────────────────────┐
│ 1-3 Convolutional Layers │
│ (time-frequency kernels) │
│ + Batch Normalization │
└──────────────┬────────────────────┘
▼
┌───────────────────────────────────┐
│ 5-7 Bidirectional RNN Layers │
│ (GRU or Simple RNN) │
│ + Batch Norm on non-recurrent │
│ connections │
│ │
│ ┌─────► ──► ──► ──► ──►─────┐ │
│ │ Forward pass │ │
│ │ │ │
│ │ ◄── ◄── ◄── ◄── ◄── │ │
│ │ Backward pass │ │
│ └────────────────────────────┘ │
└──────────────┬────────────────────┘
▼
┌───────────────────────────────────┐
│ Fully Connected Layer │
│ + Softmax over characters │
│ (29 English / ~6000 Mandarin) │
└──────────────┬────────────────────┘
▼
┌───────────────────────────────────┐
│ CTC Loss (training) │
│ Beam Search + LM (inference) │
└───────────────────────────────────┘
Training: SortaGrad (short utterances first, epoch 1)
──► Random order (remaining epochs)
Multi-GPU all-reduce (8-16 GPUs, ~7x speedup)
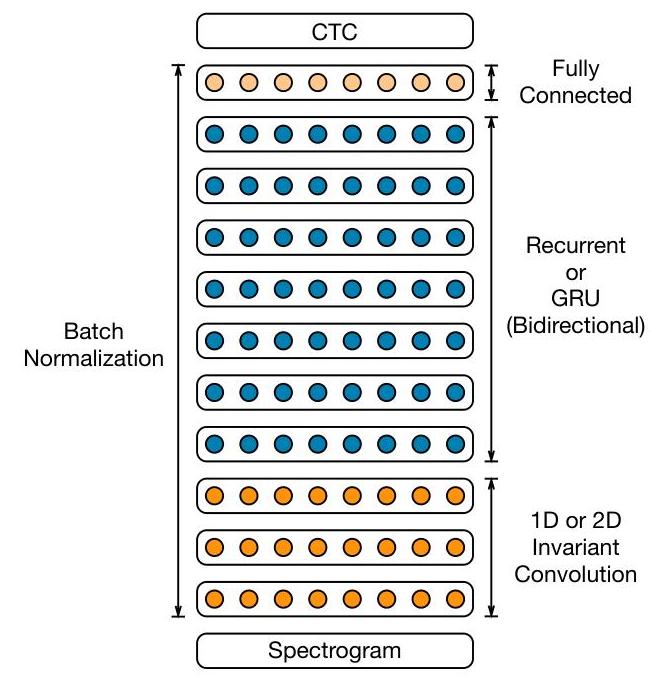
The Deep Speech 2 architecture processes log-spectrograms (or log-mel filterbank features) through a stack of convolutional layers (1-3 layers with large time-frequency kernels for initial feature extraction), followed by multiple bidirectional recurrent layers (5-7 GRU or simple RNN layers), and a final fully-connected softmax output layer over the character vocabulary.
Batch normalization is applied to the input of each non-recurrent layer and to the input of the recurrent computation at each timestep (but not across the recurrent hidden-to-hidden connections, to preserve temporal information). The network is trained end-to-end with CTC loss, which sums over all possible alignments between the input audio frames and the output character sequence using dynamic programming.
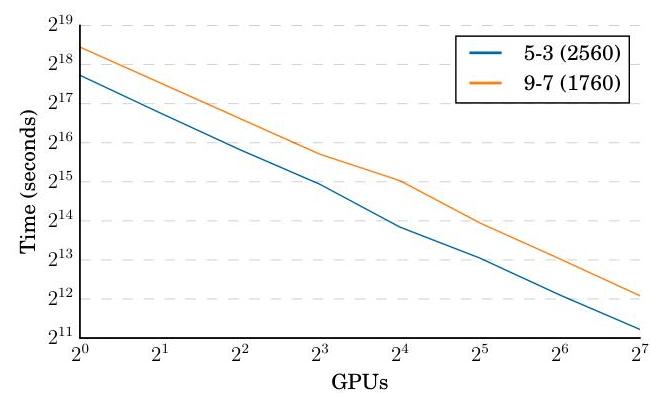
The SortaGrad curriculum begins training on shorter utterances (sorted by length) for the first epoch to stabilize early training, then switches to random ordering. At inference time, a beam search decoder combines the CTC output probabilities with an external n-gram language model to improve word-level accuracy. The multi-GPU training pipeline uses data parallelism with synchronous SGD and all-reduce for gradient synchronization across 8 or 16 GPUs, achieving near-linear speedup.
Results
- Near-human WER on English: 5.33% WER on LibriSpeech test-clean vs. 5.83% human transcription error rate on the same set
- Scaling data improves log-linearly: Doubling training data from 3k to 12k hours consistently reduces WER, with no sign of saturation, suggesting the approach is data-hungry but data-efficient per parameter
- Simple architecture beats complex pipelines: The end-to-end system outperforms traditional DNN-HMM systems that use separate acoustic models, language models, and pronunciation lexicons
- Cross-lingual transfer: The same architecture achieves strong results on Mandarin (7.93% CER on Baidu internal test for the best 9-layer model) with minimal changes, validating the language-agnostic design
Limitations & Open Questions
- Performance degrades significantly on noisy or far-field audio; the system was primarily evaluated on clean read speech
- CTC's conditional independence assumption between output tokens limits modeling of linguistic structure; later work moved to attention-based encoder-decoder and transducer models
- The 7x HPC speedup required careful engineering specific to Baidu's infrastructure; reproducibility outside that environment was limited