Emerging Properties in Self-Supervised Vision Transformers (DINO)
Overview
DINO (self-DIstillation with NO labels) demonstrates that self-supervised learning with Vision Transformers produces features with remarkable emergent properties that do not appear with supervised training or with convolutional architectures. The paper introduces a simple self-supervised framework based on self-distillation -- a student-teacher setup where both networks share the same architecture and the teacher is updated as an exponential moving average (EMA) of the student. When applied to ViTs, this framework produces self-attention maps that explicitly contain scene segmentation information, performing semantic segmentation without any pixel-level supervision.
The core insight is that the combination of self-supervised learning and the Vision Transformer architecture unlocks properties that neither ingredient produces alone. Supervised ViTs do not exhibit clear segmentation in their attention maps, and self-supervised CNNs (e.g., trained with BYOL or SwAV) do not either. Only the ViT + self-supervision combination produces these emergent features. This suggests that ViTs learn qualitatively different representations under self-supervision than under label-based training, likely because the self-supervised objective forces the model to develop richer, more spatially aware internal representations rather than collapsing to class-discriminative shortcuts.
DINO achieves 77.4% top-1 accuracy on ImageNet using only k-NN classification (no fine-tuning, no linear probe) with ViT-B/8, and 80.1% top-1 with linear evaluation -- results that exceeded all prior self-supervised methods by substantial margins at the time. The features transfer strongly to downstream tasks including copy detection, video segmentation, and image retrieval, making DINO one of the most influential papers in self-supervised visual representation learning. It directly inspired DINOv2 (2023), which scaled the approach to produce general-purpose visual features now widely adopted in autonomous driving, robotics, and multimodal systems.
Key Contributions
- Self-distillation framework for ViTs: A simple student-teacher architecture using identical networks with momentum-based teacher updates, multi-crop augmentation, and cross-entropy loss between sharpened probability distributions -- no contrastive pairs, no negative samples, no clustering
- Emergent segmentation in self-attention: Demonstrated that ViT self-attention maps trained with DINO automatically segment objects and scene regions without any pixel-level supervision, a property absent in supervised ViTs and self-supervised CNNs
- State-of-the-art k-NN classification: Achieved 77.4% top-1 on ImageNet with simple k-NN on frozen features (ViT-B/8), showing the features form well-separated clusters in embedding space without any task-specific adaptation
- Collapse prevention via centering and sharpening: Introduced a simple and effective combination of output centering (EMA of the mean teacher output) and temperature sharpening to prevent mode collapse, avoiding the need for large batches, batch normalization, or explicit contrastive negatives
- Multi-crop training strategy: Used a combination of global views (224x224) processed by the teacher and local views (96x96) processed by the student, encouraging local-to-global correspondences that improve representation quality
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ DINO Self-Distillation │
│ │
│ ┌───────────┐ │
│ │ Image │ │
│ └─────┬─────┘ │
│ │ │
│ ┌──────────┴──────────┐ │
│ │ Multi-Crop Augment │ │
│ │ 2 global (224x224) │ │
│ │ N local (96x96) │ │
│ └──┬──────────────┬──┘ │
│ │ │ │
│ global views all views │
│ │ │ │
│ ▼ ▼ │
│ ┌───────────────────┐ ┌───────────────────┐ │
│ │ Teacher (EMA) │ │ Student (SGD) │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ ViT Backbone │ │ │ │ ViT Backbone │ │ │
│ │ └──────┬──────┘ │ │ └──────┬──────┘ │ │
│ │ ▼ │ │ ▼ │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ Proj. Head │ │ │ │ Proj. Head │ │ │
│ │ │ (3-layer MLP│ │ │ │ (3-layer MLP│ │ │
│ │ │ ──► K=65536)│ │ │ │ ──► K=65536)│ │ │
│ │ └──────┬──────┘ │ │ └──────┬──────┘ │ │
│ │ ▼ │ │ ▼ │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ Centering + │ │ │ │ Softmax │ │ │
│ │ │ Sharpening │ │ │ │ (tau_s=0.1)│ │ │
│ │ │ (tau_t=0.04)│ │ │ └──────┬──────┘ │ │
│ │ └──────┬──────┘ │ │ │ │ │
│ └─────────┼─────────┘ └─────────┼─────────┘ │
│ │ P_t │ P_s │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Cross-Entropy Loss │ │
│ │ L = -P_t log(P_s) │ │
│ └─────────────────────┘ │
│ │
│ Teacher update: theta_t = lambda * theta_t + (1-lambda)*theta_s│
│ (lambda: 0.996 ──► 1.0 cosine schedule) │
└─────────────────────────────────────────────────────────────────┘
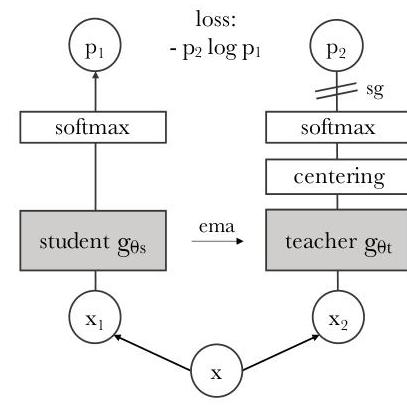
DINO uses a self-distillation framework where a student network and a teacher network share the same architecture (ViT or ResNet) but differ in how they are updated. The student is trained via gradient descent; the teacher is an exponential moving average of the student parameters.
Multi-crop augmentation: Each input image is augmented into multiple views -- two global views at 224x224 resolution covering more than 50% of the image, and several local views at 96x96 resolution covering less than 50%. All views are passed through the student, but only the global views are passed through the teacher. The training objective requires the student to match the teacher's output for every pair of (student view, teacher global view), which encourages the student to learn local-to-global correspondences.
Network architecture: Both student and teacher use the same backbone (typically ViT-S/16 or ViT-B/8) followed by a projection head. The projection head consists of a 3-layer MLP with hidden dimension 2048, followed by L2 normalization, and a final linear layer projecting to K=65536 dimensions. The output is converted to a probability distribution using softmax with temperature scaling.
Loss function: The training objective is cross-entropy between the sharpened teacher probability distribution and the student distribution:
L = - sum_x sum_{x' != x} P_t(x') * log P_s(x)
where P_s and P_t are the student and teacher softmax outputs with temperatures tau_s = 0.1 and tau_t = 0.04-0.07 (linearly warmed up during early training). The asymmetric temperature (teacher sharper than student) is critical for producing peaked, informative targets.
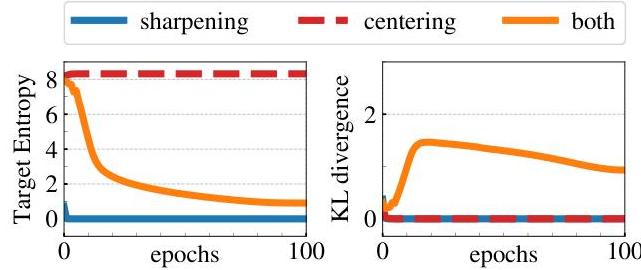
Collapse prevention: Two complementary mechanisms prevent all outputs from collapsing to a uniform or single-mode distribution: 1. Centering: A bias term c is subtracted from the teacher output before softmax, computed as an EMA of the batch-mean teacher output: c = m * c + (1-m) * mean(g_theta(x)). This prevents any single dimension from dominating. 2. Sharpening: The low teacher temperature (tau_t = 0.04) produces peaked distributions, preventing uniform collapse. The paper shows that centering alone encourages uniform collapse while sharpening alone encourages single-mode collapse -- only their combination is stable.
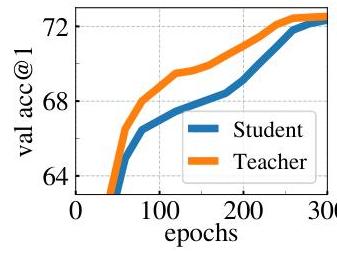
Teacher update: The teacher parameters theta_t are updated as: theta_t = lambda * theta_t + (1 - lambda) * theta_s, where lambda follows a cosine schedule from 0.996 to 1.0 during training. The teacher consistently outperforms the student throughout training.

Results
| Method | Architecture | k-NN Top-1 | Linear Top-1 |
|---|---|---|---|
| DINO | ViT-B/8 | 77.4% | 80.1% |
| DINO | ViT-S/16 | 74.5% | 77.0% |
| DINO | ViT-B/16 | 76.1% | 78.2% |
| DINO | ResNet-50 | 67.5% | 75.3% |
| MoCo v2 | ResNet-50 | 61.9% | 71.1% |
| SwAV | ResNet-50 | 65.6% | 75.3% |
| BYOL | ResNet-50 | 66.5% | 74.3% |
| Supervised | ViT-B/16 | — | 79.9% |
- DINO ViT-S/16 achieves +3.5% over the best competing SSL methods (BYOL, MoCo v2, SwAV) on ViT-S/16 in linear evaluation and +7.9% in k-NN evaluation, showing that self-supervision with DINO produces substantially better features than other SSL approaches for ViTs at small scale
- Smaller patch sizes dramatically improve performance: ViT-B/8 gains +4.0% k-NN and +1.9% linear over ViT-B/16, at the cost of higher compute
- The self-attention heads in the last layer of DINO ViTs contain explicit object segmentation information, with different heads attending to different semantic regions of the image
- DINO features excel at copy detection (strong performance on the Oxford and Paris retrieval benchmarks) and video object segmentation (DAVIS benchmark), outperforming supervised features without any adaptation
- The teacher network consistently outperforms the student throughout training, motivating the use of teacher features at inference time
Key ablations:
- Momentum encoder is essential: replacing EMA teacher with a copy of the student (no momentum) collapses performance
- Both centering and sharpening are needed: centering alone leads to uniform collapse, sharpening alone leads to single-mode collapse
- Multi-crop is important: removing local crops degrades k-NN accuracy by ~2%
- Projection head depth matters: 3-layer MLP outperforms 1-layer or 2-layer heads
Limitations & Open Questions
- Computational cost is high, especially for small patch sizes: ViT-B/8 requires ~3.5x the compute of ViT-B/16 due to the 4x longer sequence length
- The emergent segmentation property is qualitatively striking but not rigorously benchmarked against dedicated unsupervised segmentation methods in the original paper
- The relationship between the self-supervised objective and the emergence of segmentation is not fully understood -- why does self-distillation produce segmentation while contrastive methods (MoCo, SimCLR) produce weaker spatial structure?
- Scaling beyond ViT-B was not explored in the original paper (addressed later by DINOv2)
- The method's performance on dense prediction tasks (detection, segmentation) when used as a backbone was not extensively studied (also addressed by DINOv2)
Connections
Related papers in the wiki: - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT, the backbone architecture that DINO trains in a self-supervised manner; DINO shows ViTs learn qualitatively different features under self-supervision vs. supervision - Attention Is All You Need -- the original transformer architecture underlying ViT - Learning Transferable Visual Models From Natural Language Supervision -- CLIP, a contemporary (2021) approach to learning visual representations without ImageNet labels, using language supervision instead of self-distillation - Deep Residual Learning For Image Recognition -- ResNet, used as a baseline architecture in DINO experiments; DINO shows emergent segmentation appears only with ViTs, not ResNets - Imagenet Classification With Deep Convolutional Neural Networks -- AlexNet, the foundational CNN that established ImageNet classification; DINO represents the shift from supervised CNNs to self-supervised transformers - Foundation Models -- DINO features became a key building block for foundation models in vision, robotics, and driving