Learning Transferable Visual Models From Natural Language Supervision
Overview
CLIP (Contrastive Language-Image Pre-training) learns visual representations from natural language supervision by training an image encoder and a text encoder jointly on 400 million image-text pairs collected from the internet. The two encoders are trained with a contrastive objective: matching image-text pairs should have high cosine similarity in the shared embedding space, while non-matching pairs should have low similarity. This simple approach produces visual representations that transfer remarkably well to downstream tasks without any task-specific fine-tuning.
The key insight is that natural language provides a much richer and more scalable supervisory signal than fixed label sets. Traditional vision models are trained to classify images into a predetermined set of categories (e.g., 1000 ImageNet classes), which limits their representation to those specific concepts. CLIP instead learns from free-form text descriptions, which can express an open vocabulary of visual concepts, attributes, relationships, and contexts. This enables zero-shot transfer: at inference time, CLIP can classify images into any set of categories simply by encoding the category names as text and finding the best match.
CLIP is one of the most influential papers in the multimodal foundation model space, fundamentally changing how the field thinks about visual representation learning. It demonstrated that web-scale image-text pairs constitute a viable alternative to curated labeled datasets, that contrastive pre-training can match or exceed supervised pre-training on many benchmarks, and that zero-shot transfer from language supervision is competitive with few-shot fine-tuned models. CLIP's visual encoder became the backbone for numerous downstream systems including DALL-E, Stable Diffusion, and many vision-language models used in autonomous driving and robotics.
Key Contributions
- Contrastive language-image pre-training: Joint training of image and text encoders using a symmetric contrastive loss on 400M image-text pairs, learning a shared embedding space where visual and linguistic concepts are aligned
- Zero-shot visual classification: At inference time, classify images into any set of categories by encoding category names as text prompts and selecting the highest-similarity match -- no task-specific training required
- Web-scale training data: Curated a dataset of 400M image-text pairs from the internet (WebImageText / WIT), demonstrating that naturally occurring image-text co-occurrences provide sufficient supervision for strong visual representations
- Prompt engineering for vision: Introduced the concept of prompt templates ("a photo of a {class}") for zero-shot classification, showing that the text encoding of class names significantly affects performance
- Robust transfer across distributions: CLIP representations show significantly better robustness to distribution shift compared to ImageNet-trained models, maintaining performance on out-of-distribution test sets where supervised models degrade
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ CLIP Contrastive Training │
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ Image_1 │ │ Text_1 │ │
│ │ Image_2 │ │ Text_2 │ │
│ │ ... │ │ ... │ │
│ │ Image_N │ │ Text_N │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │Image Encoder │ │Text Encoder │ │
│ │(ViT-L/14 or │ │(12-layer GPT │ │
│ │ ResNet) │ │ transformer) │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │Linear Proj + │ │Linear Proj + │ │
│ │L2 Normalize │ │L2 Normalize │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ ▼ ▼ │
│ I_1, I_2, ..., I_N T_1, T_2, ..., T_N │
│ │
│ ┌──── Cosine Similarity Matrix (NxN) ────┐ │
│ │ T_1 T_2 ... T_N │ │
│ I_1 │ ✓ ✗ ✗ │ │
│ I_2 │ ✗ ✓ ✗ N = 32,768 │ │
│ ... │ ... │ │
│ I_N │ ✗ ✗ ✓ │ │
│ └────────────────────────────────────────┘ │
│ Symmetric contrastive loss (InfoNCE) with │
│ learnable temperature τ │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ Zero-Shot Classification │
│ │
│ ┌───────┐ Image ┌──────────────────────────┐ │
│ │ Image │──Encoder──►│ Image Embedding │ │
│ └───────┘ └────────────┬─────────────┘ │
│ │ cosine sim │
│ "a photo of a dog" ──► T_1 ────┤ │
│ "a photo of a cat" ──► T_2 ────┤ ──► argmax │
│ "a photo of a bird" ──► T_3 ────┘ = prediction │
└─────────────────────────────────────────────────────────┘
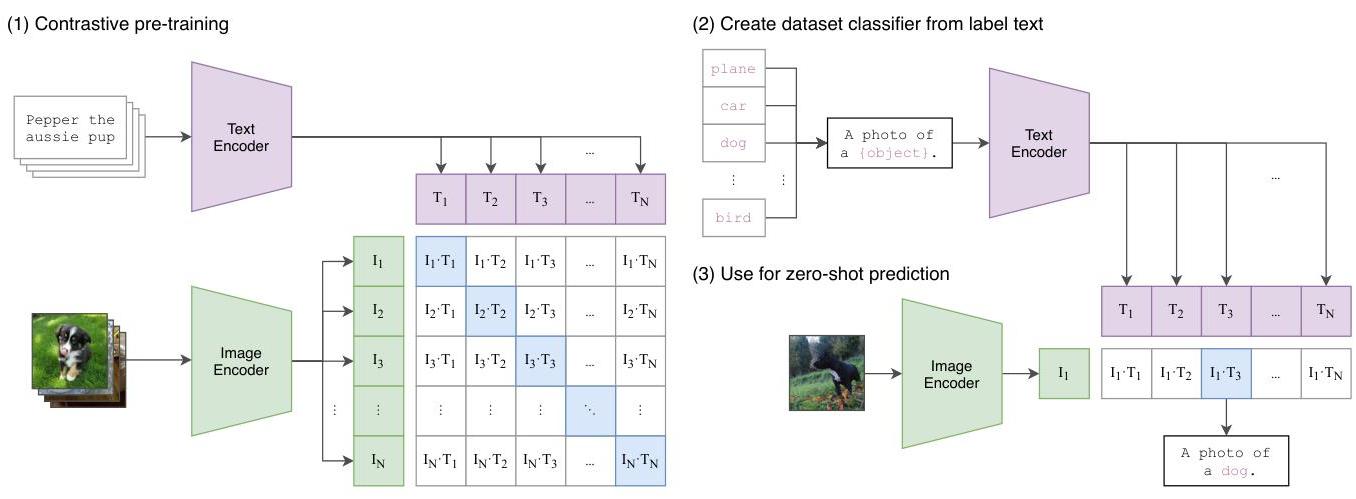
CLIP's architecture consists of two parallel encoders: an image encoder and a text encoder, both producing fixed-dimensional embedding vectors that are projected into a shared space.
The image encoder can be either a ResNet (modified with attention pooling) or a Vision Transformer (ViT). The paper evaluates multiple scales: ResNet variants (RN50, RN101, RN50x4, RN50x16, RN50x64) and Vision Transformer variants (ViT-B/32, ViT-B/16, ViT-L/14), with ViT-L/14@336px (ViT-L/14 additionally fine-tuned at 336px resolution for one epoch) being the best-performing model; all results reported as "CLIP" in the paper use this variant. The image encoder takes a 224x224 image and produces a single embedding vector. A notable finding is that while the paper explores different image encoder architectures, the text encoder remains constant, suggesting text representation is not the bottleneck for performance.
The text encoder is a 12-layer transformer with masked self-attention (GPT-2 style), taking tokenized text (up to 76 tokens, byte pair encoding with 49,152-token vocabulary) and producing a single embedding vector from the [EOS] token position. Both encoders' outputs are linearly projected to the shared embedding dimension (512 or 768 depending on the model variant) and L2-normalized.
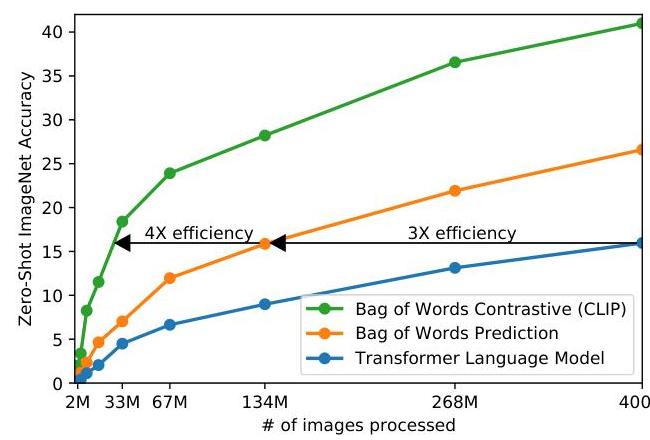
Training uses a symmetric contrastive loss. Given a batch of N=32,768 image-text pairs, the model computes an N x N matrix of cosine similarities between all image and text embeddings. The contrastive objective is: L = -(1/N) * sum_i [log(exp(sim(I_i, T_i)/tau) / sum_j exp(sim(I_i, T_j)/tau)) + log(exp(sim(I_i, T_i)/tau) / sum_j exp(sim(I_j, T_i)/tau))], where tau is a learnable temperature parameter. The contrastive approach proved substantially more efficient than alternatives -- CLIP achieves the same zero-shot performance as a bag-of-words prediction model while processing 4x fewer images, and is 3x more efficient than a transformer language model approach. Training uses Adam with decoupled weight decay, cosine learning rate schedule with linear warmup, mixed precision, and gradient checkpointing.
The training dataset (WIT) contains 400M image-text pairs collected by searching for images associated with a large set of text queries derived from Wikipedia and WordNet concepts. Images are randomly cropped and resized to 224x224 pixels. The dataset is not publicly released but the collection methodology emphasizes breadth of visual concepts.
For zero-shot classification, the class names are embedded in prompt templates (e.g., "a photo of a {class}, a type of pet") to provide context. Multiple prompt templates are averaged (prompt ensembling) to improve robustness. The image is encoded and compared to all class text embeddings, with the highest similarity class selected as the prediction. Prompt engineering and ensembling provides substantial gains over using class names alone, with both approaches showing smooth scaling with compute.
Results
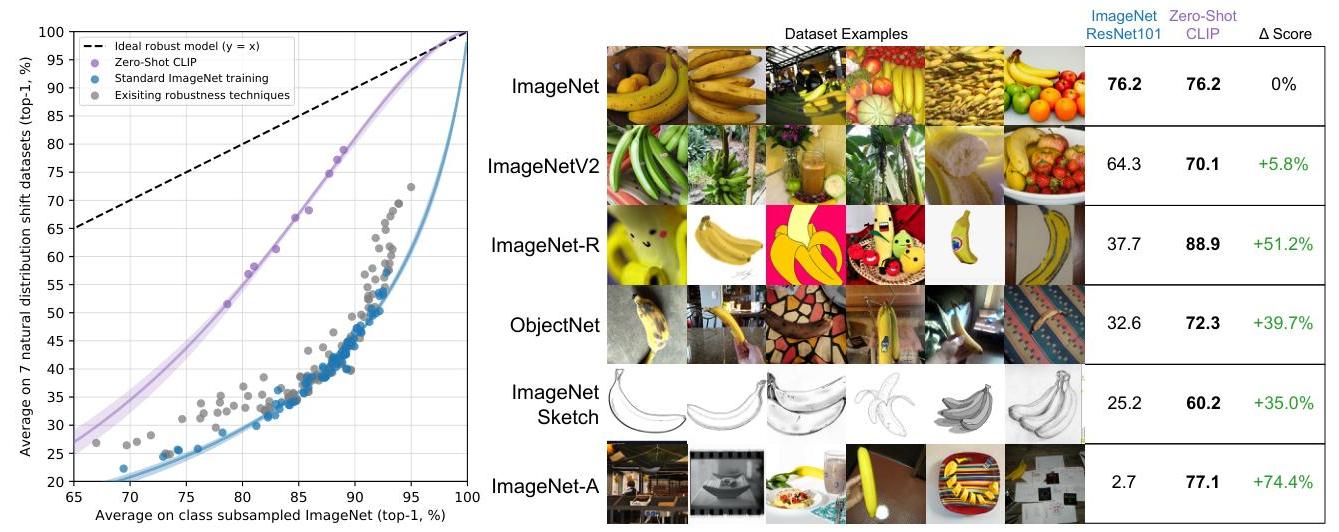
| Setting | ImageNet Top-1 | ImageNet-R | ImageNet-Sketch | ObjectNet |
|---|---|---|---|---|
| Zero-shot CLIP (ViT-L/14@336px) | 76.2% | 88.9% | 60.2% | 72.3% |
| Supervised ResNet-50 | 76.1% | 56.1% | 33.3% | 52.3% |
| Supervised ResNet-101 | 77.4% | 57.7% | 36.0% | 54.8% |
| Few-shot CLIP (16-shot) | 73.7% | — | — | — |
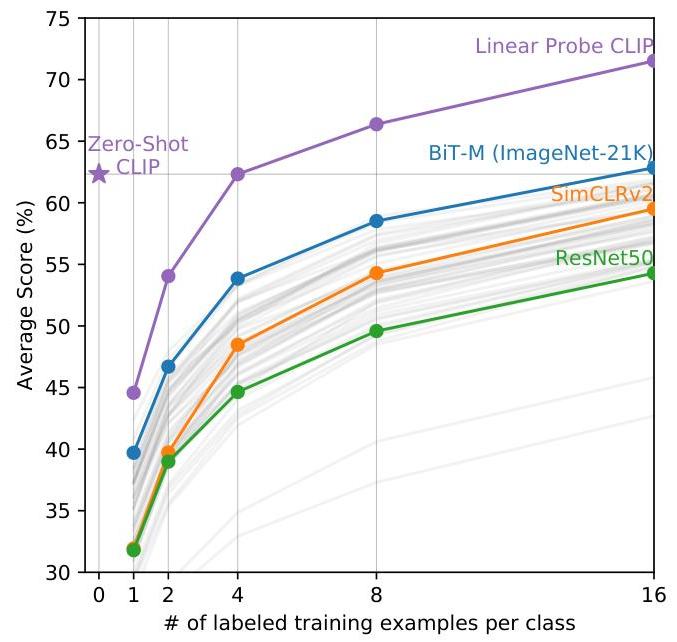
- Zero-shot CLIP matches the accuracy of a fully supervised linear probe on ResNet-50 features across 27 datasets, despite never training on any of those datasets' labeled examples
- On ImageNet, zero-shot CLIP (ViT-L/14) achieves 76.2% top-1 accuracy, matching the original supervised ResNet-50 result without any ImageNet-specific training
- Data efficiency: Zero-shot CLIP often matches the performance of supervised models trained with 1 to 4 shots (examples) per class
- Wide task coverage: Non-trivial zero-shot performance on OCR, action recognition, geo-localization, and specialized classification tasks
- CLIP shows dramatically better robustness to distribution shift: zero-shot CLIP significantly outperforms supervised models on ImageNet-R (renderings), ImageNet-Sketch, and ObjectNet, suggesting that learning from diverse internet data helps develop more robust representations that generalize better to out-of-distribution samples
- Scaling the training data and model size consistently improves performance, with smooth scaling of zero-shot performance similar to GPT-3's scaling properties, and no signs of saturation at the largest scales tested
- Prompt engineering matters significantly: using the template "a photo of a {class}" improves ImageNet zero-shot accuracy by several percentage points compared to using just the class name, and dataset-specific prompts can improve further
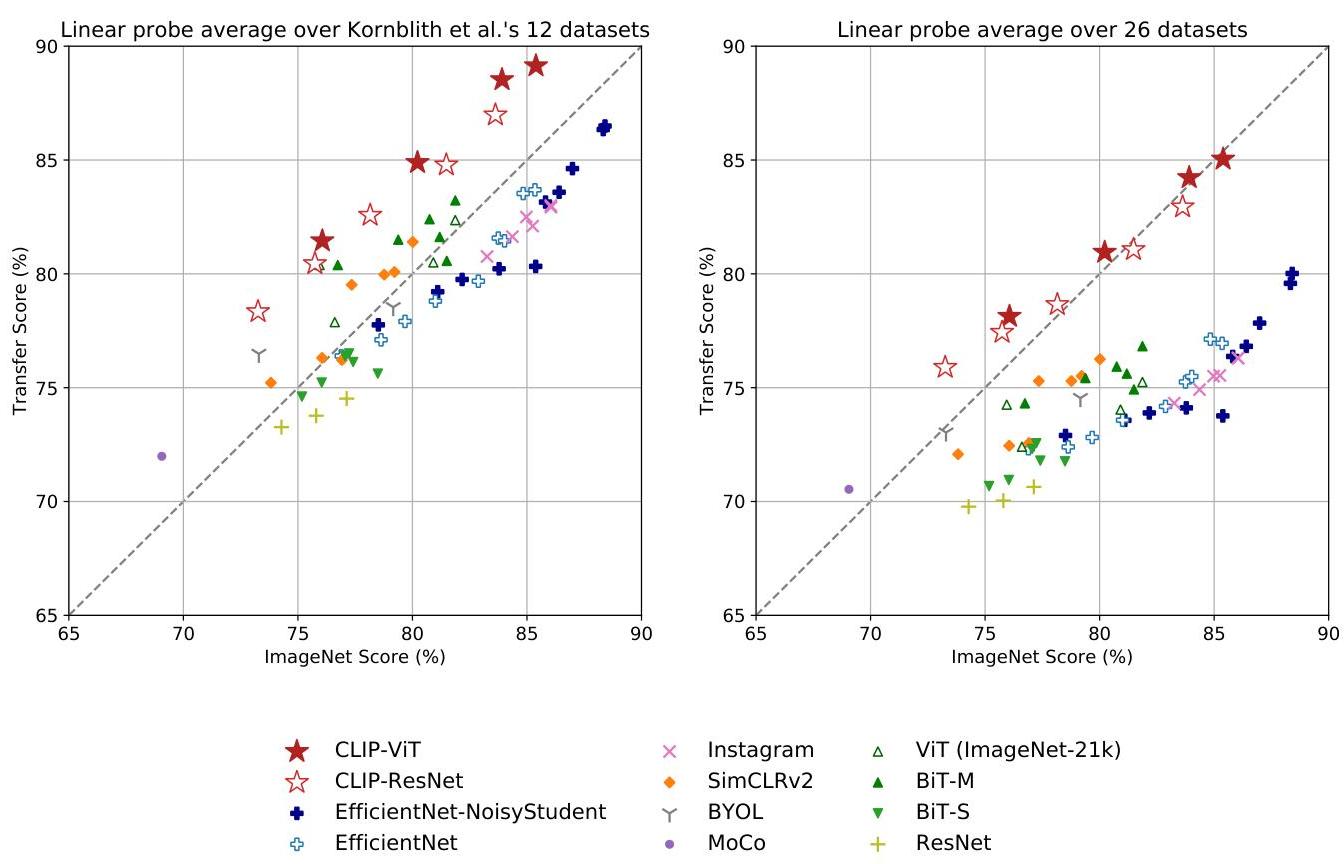
- Linear probe evaluation (training a linear classifier on frozen CLIP features) outperforms the best publicly available ImageNet models across multiple datasets, demonstrating that CLIP learns general-purpose visual features
- Data overlap analysis: Researchers verified performance was not due to test image memorization; overlap exists but does not significantly impact results
Limitations & Open Questions
- CLIP struggles with fine-grained classification tasks (distinguishing car models, flower species, aircraft types), abstract tasks, and counting, though it performs well on common objects. CLIP outperforms zero-shot humans on some tasks but generally falls short of one-shot human performance; human performance (even zero-shot) substantially exceeds CLIP on many specialized tasks
- The model relies on English text supervision, limiting its applicability to non-English visual concepts and culturally specific imagery
- Zero-shot performance remains below state-of-the-art fine-tuned models on most benchmarks, suggesting that task-specific adaptation still provides significant benefit when labeled data is available
- Social bias concerns: Extensive analysis revealed concerning patterns -- e.g., CLIP shows stereotyped associations between gender and occupations, appearances, and other attributes. Potential surveillance applications are acknowledged, though CLIP's performance was not exceptional compared to specialized models for those purposes
Connections
Related papers in the wiki: - Attention Is All You Need -- transformer architecture underpinning CLIP's text encoder (and ViT image encoder variant) - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT, used as CLIP's best-performing image encoder - Imagenet Classification With Deep Convolutional Neural Networks -- AlexNet, the supervised ImageNet paradigm that CLIP's zero-shot approach matches - Deep Residual Learning For Image Recognition -- ResNet, CLIP's alternative image encoder family - Language Models Are Few Shot Learners -- GPT-3, parallel demonstration that scale enables zero-shot/few-shot transfer in NLP - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT, bidirectional text pretraining; CLIP uses a unidirectional (GPT-style) text encoder instead - Denoising Diffusion Probabilistic Models -- diffusion models that use CLIP embeddings for text-conditioned image generation (DALL-E 2, Stable Diffusion) - Vlp Vision Language Planning For Autonomous Driving -- driving planner leveraging CLIP-style vision-language representations - Palm E An Embodied Multimodal Language Model -- embodied multimodal model building on contrastive vision-language pretraining - Foundation Models -- CLIP as a seminal vision-language foundation model - Vision Language Action -- CLIP encoders as visual backbone for VLA systems