VLP: Vision Language Planning for Autonomous Driving
Overview
VLP (Vision Language Planning) by Pan et al. (CVPR 2024) represents a fundamentally different approach to using language in autonomous driving compared to instruction-following VLAs like LMDrive or reasoning-focused systems like Senna. Rather than using language as an explicit user interface or intermediate reasoning representation, VLP uses language model features as an internal knowledge prior that enhances BEV-based planning through feature-space alignment. No language input is needed at inference time.
The key insight is that pretrained language models encode vast world knowledge -- about object affordances, spatial relationships, traffic conventions, and physical common sense -- that is useful for driving even when language is not part of the driving interface. VLP injects this knowledge by aligning local BEV features with pretrained LM feature spaces (ALP module) and by using LM comprehension to align planning queries with navigation goals and ego status (SLP module). The result is a driving system that benefits from language model knowledge without requiring language input, language output, or any language-related computation at inference time.
This establishes "language as prior" as a distinct paradigm alongside "language as interface" (LMDrive, Talk2Car) and "language as reasoning channel" (Senna, ORION). VLP demonstrates that the boundaries of what constitutes a VLA system are blurry: the system uses vision-language alignment during training but is purely vision-action at deployment, raising interesting questions about how to classify and compare these architectures.
Key Contributions
- ALP (Agent-centric Learning Paradigm): Aligns region-of-interest BEV features for each agent (ego-vehicle, foreground objects, lane elements) with LM-generated "agent expectation features" via contrastive learning, injecting richer semantic representations into the spatial planning pipeline without requiring language input at test time
- SLP (Self-driving-car-centric Learning Paradigm): Aligns the planner's ego-vehicle query with an LM-generated "ego-vehicle planning feature" derived from high-level driving commands and ground-truth trajectories via sample-wise contrastive learning, providing semantically grounded planning guidance
- Language as internal prior paradigm: LM knowledge improves planning without requiring language input at inference time, distinguishing VLP from instruction-following approaches and making it compatible with standard AD deployment
- Compatible with existing BEV planning stacks: The ALP/SLP modules can augment existing BEV-based AD systems without architectural overhaul, acting as plug-in improvements
- Strong empirical validation at CVPR: Published at a top venue with ~155 citations, demonstrating community interest in the language-as-prior approach
Architecture
┌──────────────────────────────────────────────────────────┐
│ VLP Framework │
│ │
│ Multi-camera Images Scene Descriptions (train only) │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────────┐ │
│ │ BEV Encoder │ │ Pretrained LM │ (frozen) │
│ │ (backbone + │ │ (CLIP / small LM)│ │
│ │ BEV lift) │ └────────┬─────────┘ │
│ └──────┬───────┘ │ │
│ │ │ │
│ ┌────┴─────────────┐ │ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────┐ ┌──────────────────────┐ │
│ │ BEV │ │ ALP Module │ (train only) │
│ │ Feat │◄───│ Contrastive align │ │
│ │ │ │ BEV ◄──► LM space │ │
│ └──┬───┘ └──────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ Transformer Planner │ │
│ │ ┌────────────────────────────┐ │ │
│ │ │ Ego queries + cross-attn │ │ │
│ │ │ to BEV features │ │ │
│ │ └────────────────────────────┘ │ │
│ │ ┌────────────────────────────┐ │ │
│ │ │ SLP: LM-aligned planning │ │ (train only) │
│ │ │ queries (nav goal + ego) │ │ │
│ │ └────────────────────────────┘ │ │
│ └──────────────┬───────────────────┘ │
│ ▼ │
│ Ego Trajectory │
│ │
│ Inference: LM removed; BEV features retain alignment │
└──────────────────────────────────────────────────────────┘
Architecture / Method
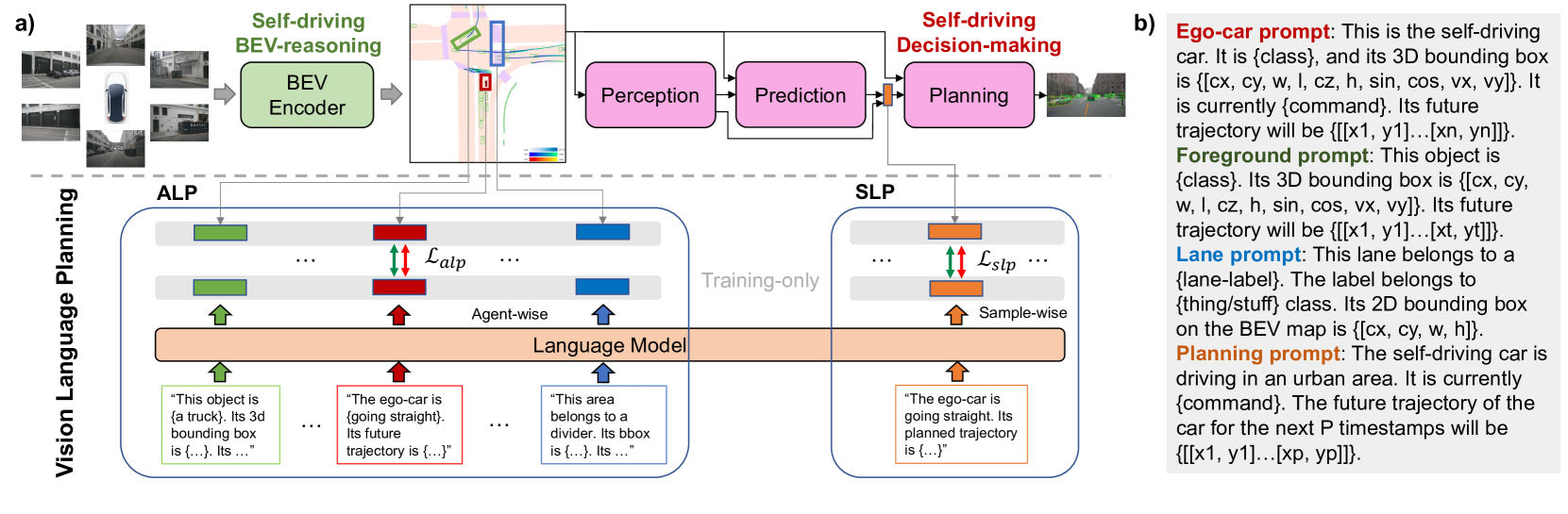
VLP builds on a standard BEV-based autonomous driving pipeline and adds two language-guided modules during training. The base system extracts multi-camera features, lifts them to BEV space, and uses a transformer-based planner to predict ego trajectories.
ALP (Agent-centric Learning Paradigm): During training, structured language prompts are generated for each agent (ego-vehicle, foreground objects, lane elements) using ground-truth bounding boxes, labels, and future trajectories (e.g., "This object is {a truck}. Its 3D bounding box is {...}. Its future trajectory will be {...}."). These prompts are fed into a frozen pretrained language model (e.g., CLIP text encoder) to produce "agent expectation features." A contrastive loss maximizes similarity between each agent's BEV region-of-interest feature and its corresponding expectation feature while minimizing similarity with other agents' features. At inference time, the language model and adaptation layers are removed entirely -- the BEV encoder retains the semantically richer representations learned during training.
SLP (Self-driving-car-centric Learning Paradigm): The planner's ego-vehicle query is aligned with an LM-generated "ego-vehicle planning feature." During training, a language prompt encoding the current high-level driving command ("going straight") and ground-truth future trajectory is fed into the same frozen LM. A sample-wise contrastive loss aligns the ego-vehicle query feature with this planning feature, embedding human driving logic into the planning representation. At inference, the LM and adaptation layers are discarded entirely.
Both modules use training-time language supervision to shape the feature space of the vision-only driving system. The total loss combines standard planning losses (waypoint L2, collision penalty) with the ALP contrastive loss and SLP alignment loss.
Results
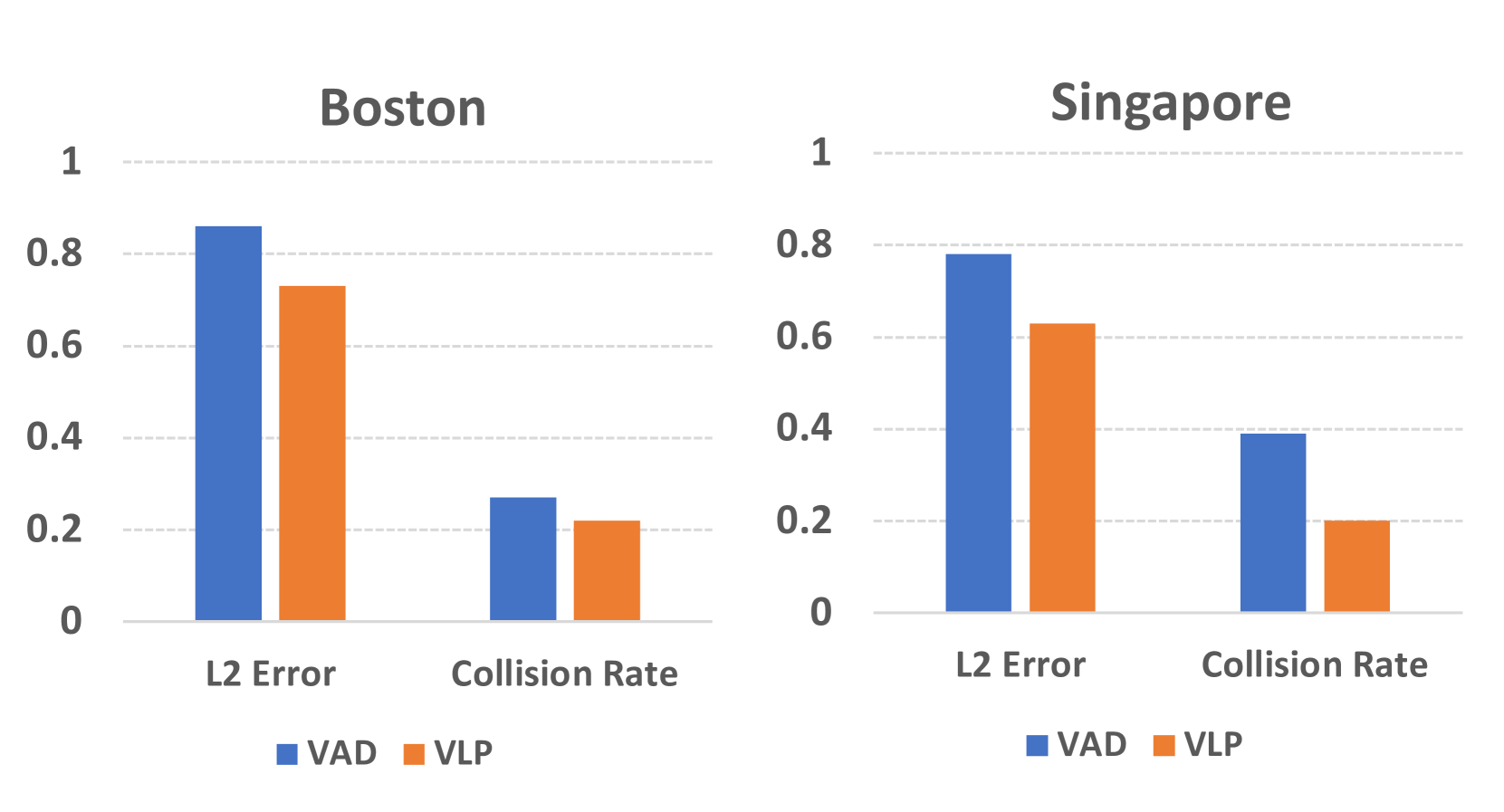
| Configuration | L2 Error Reduction | Collision Rate Reduction |
|---|---|---|
| VLP-VAD | 35.9% | 60.5% |
| VLP-UniAD | 28.1% | 48.4% |
| Cross-city (Boston) | 15.1% | 18.5% |
| Cross-city (Singapore) | 19.2% | 48.7% |
- Improvements across multiple driving tasks on nuScenes, particularly in long-tail and rare scenarios where LM world knowledge provides useful semantic priors that pure vision features lack
- LM features enhance semantic understanding of complex scenes that BEV features alone may not capture, with the largest improvements on scenarios involving unusual objects, ambiguous right-of-way, and complex intersections
- No language input needed at inference: The system is deployable in standard AD pipelines without a language interface, with all language benefit baked into the feature representations during training
- Plug-in improvement to existing systems: ALP and SLP can be added to multiple baseline BEV planners (e.g., UniAD, VAD) and consistently improve performance
- Ablation validates both modules: ALP alone improves performance, SLP alone improves performance, and the combination is additive, suggesting they capture complementary aspects of language knowledge
Limitations & Open Questions
- Ambiguous VLA classification: language functions as an internal prior rather than explicit instruction-following, blurring the boundary of what constitutes a VLA system and making comparison with other VLA approaches methodologically challenging
- Primarily open-loop evaluation on nuScenes, which does not capture closed-loop driving challenges (compounding errors, reactive agents)
- Limited interpretability: LM features improve performance but do not generate human-readable reasoning or explanations, forgoing the interpretability benefits that explicit language reasoning provides
- Dependent on the quality and alignment of pretrained LM features with driving-relevant semantics; misalignment between web-trained LM representations and driving-specific concepts could limit benefit
Connections
- Autonomous Driving
- Vision Language Action
- Lmdrive Closed Loop End To End Driving With Large Language Models
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment
- Vad Vectorized Scene Representation For Efficient Autonomous Driving
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving