Overview
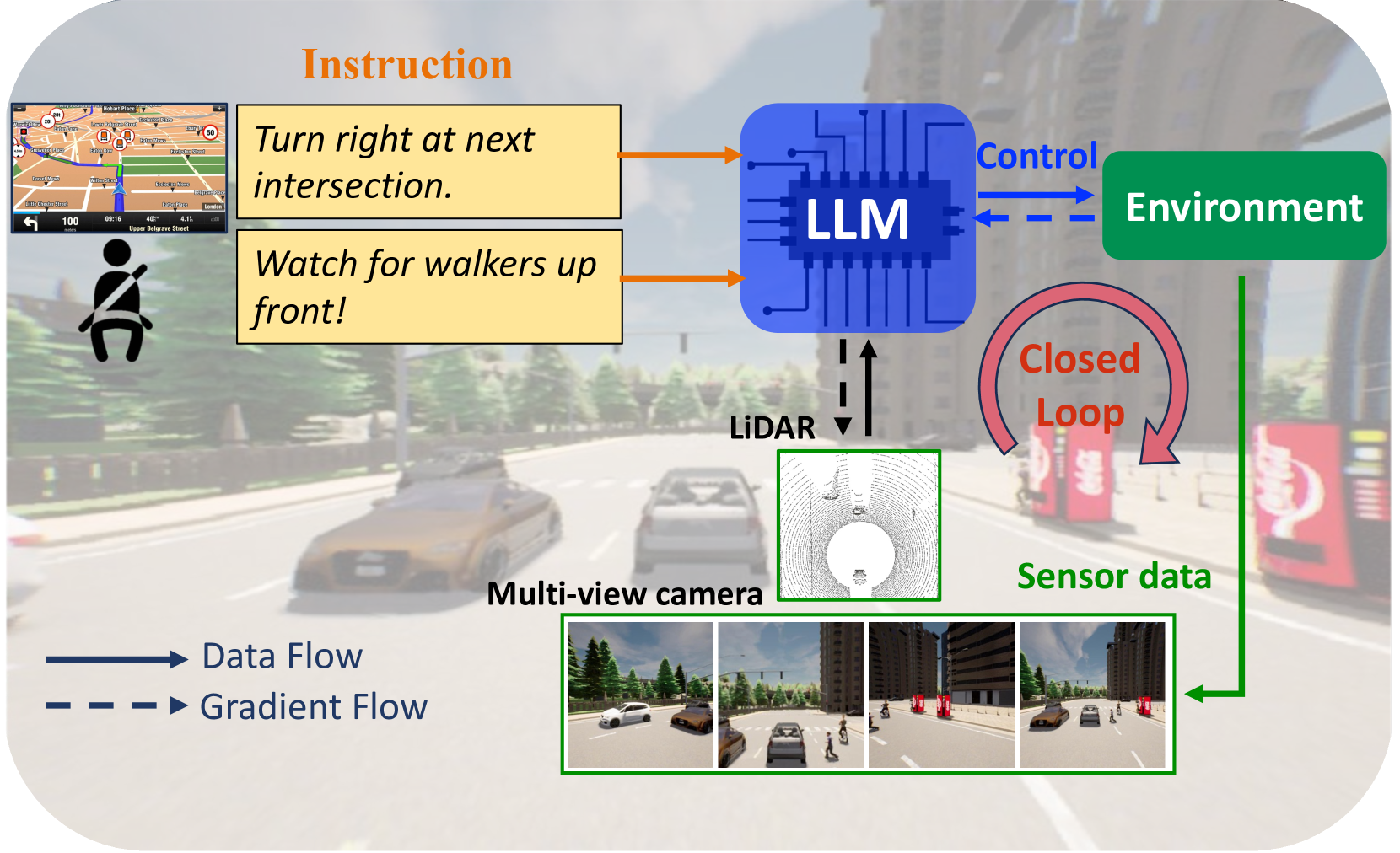
LMDrive is the first system to demonstrate and benchmark LLM-based driving in closed-loop simulation, introducing the LangAuto benchmark with ~64K instruction-following clips that include navigation commands, cautionary notices, and adversarial misleading instructions. Prior LLM driving works like DriveGPT4 and GPT-Driver evaluated only open-loop on replayed logged data, which cannot capture compounding errors or interactive driving competence.
LMDrive addressed this critical gap by building an instruction-following multimodal LLM that operates in closed-loop CARLA simulation where errors compound and the agent must react to a changing environment. Its LangAuto benchmark became the first widely-referenced language-guided closed-loop driving evaluation, establishing the standard for testing whether language-conditioned driving agents can actually drive, not just predict actions on logged frames.
The system fuses camera and LiDAR inputs through separate encoders with a Querying Transformer (Q-Former) that efficiently compresses visual tokens, feeding into a frozen LLM core (pre-trained multi-modal LLMs such as LLaVA-v1.5) with MLP adapters that convert LLM outputs into waypoints and instruction completion flags. By keeping the LLM frozen, the system preserves its language reasoning capabilities (including the ability to reject unsafe instructions) while adapting to driving-specific control output. Pre-training the vision encoder on large-scale perception tasks establishes robust scene understanding. This design choice proved prescient -- later work confirmed that frozen LLM backbones with learned adapters provide the best trade-off between reasoning and control.
Key Contributions
- LangAuto benchmark: First named closed-loop language-conditioned driving benchmark built on CARLA, with ~64K instruction-following clips covering navigation, notice, and adversarial instruction types
- Multi-sensor multimodal architecture: Fuses camera and LiDAR inputs through separate encoders with a multimodal adapter, feeding into a frozen LLM core with learnable adapters
- Instruction-following driving: Supports diverse natural-language instruction types including turn-by-turn navigation ("turn left at the intersection"), cautionary notices ("watch out for the pedestrian on the right"), and multiple phrasings per scenario
- Robustness to adversarial instructions: Tests misleading and infeasible commands; the frozen LLM retains reasoning capability to prioritize safe driving over unsafe instruction compliance
- Frozen LLM with learnable adapters: Preserves the LLM's language reasoning capabilities while adapting to driving-specific control output through encoder and adapter modules
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ LMDrive Architecture │
│ │
│ ┌────────────┐ ┌───────────┐ │
│ │ Multi-view │──►│ Vision │──► Visual │
│ │ Cameras │ │ Encoder │ Tokens ──┐ │
│ └────────────┘ └───────────┘ │ │
│ ┌────────┴──────┐ │
│ ┌────────────┐ ┌───────────┐ │ Q-Former │ │
│ │ LiDAR │──►│ 3D Encoder│──► BEV│ (compress) │ │
│ │ Points │ │ (Voxel) │ Tokens└────────┬──────┘ │
│ └────────────┘ └───────────┘ │ │
│ ┌────────┴──────┐ │
│ ┌────────────┐ │ Multimodal │ │
│ │ Language │──► Tokenize ──────►│ Adapter │ │
│ │ Instruction │ │ (to LLM │ │
│ │ "turn left" │ │ embed space) │ │
│ └────────────┘ └────────┬──────┘ │
│ │ │
│ ┌────────┴──────┐ │
│ │ Frozen LLM │ │
│ │ (LLaMA-based)│ │
│ │ + Adapters │ │
│ └────────┬──────┘ │
│ │ │
│ ┌────────┴──────┐ │
│ │ Output Head │ │
│ │ Waypoints + │ │
│ │ Completion │ │
│ └───────────────┘ │
└──────────────────────────────────────────────────────────────┘
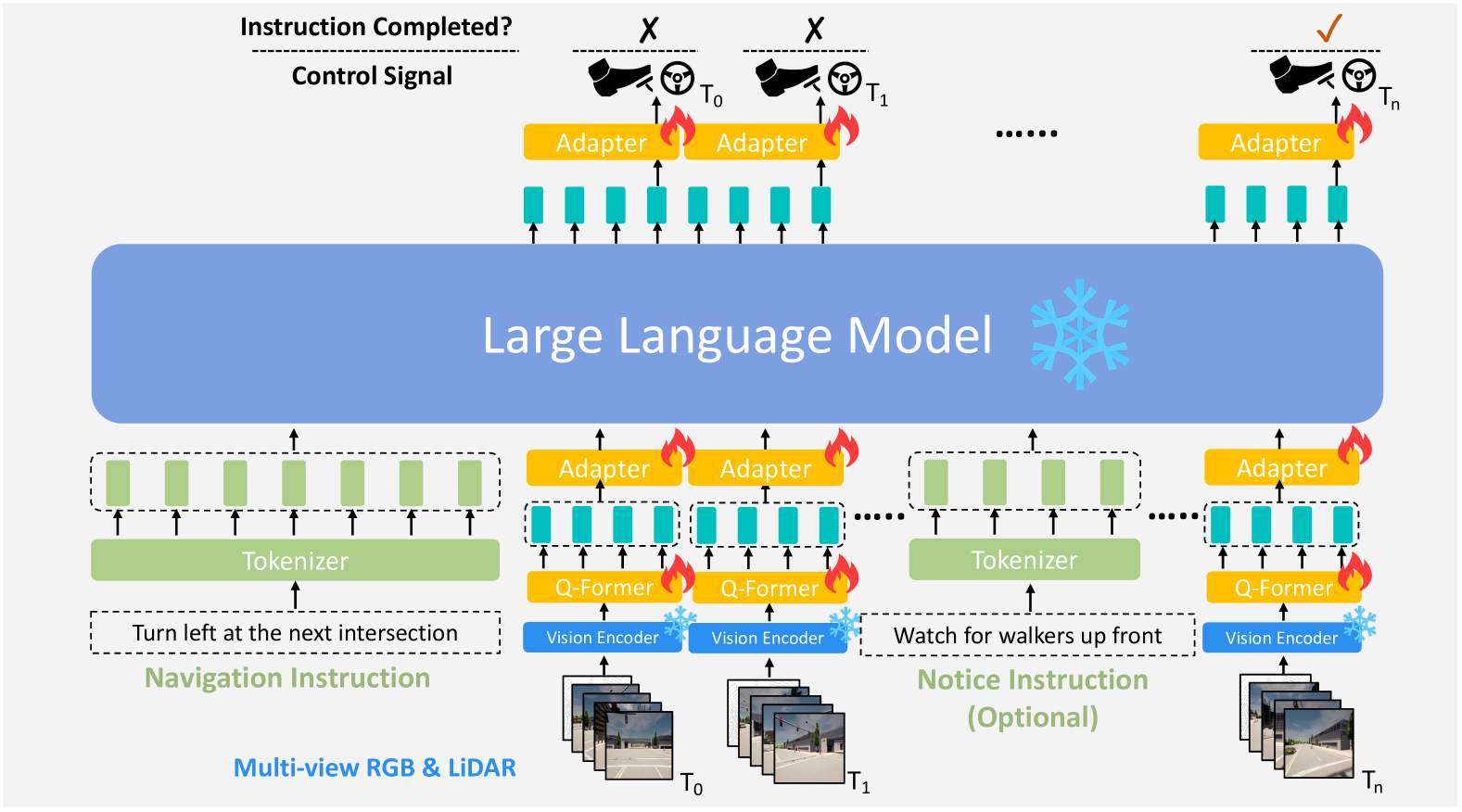
LMDrive uses a multi-modal encoder-adapter-LLM architecture. Camera images are processed through a ResNet backbone to produce image feature maps, which are then fused across views via a transformer encoder to produce visual tokens. LiDAR point clouds are processed through a PointPillars backbone to produce 3D features. A BEV decoder transformer (with learned BEV queries) attends from these BEV queries to multi-view image features to generate BEV tokens. A Q-Former (adapted from BLIP-2) then efficiently compresses these visual tokens before they are projected into the LLM's embedding space alongside tokenized language instructions.
The LLM backbone (LLaMA-based, e.g., LLaVA-v1.5 7B) is kept frozen during training. Two-layer MLP adapters bridge the Q-Former output to the LLM's input dimension and convert the LLM's final hidden states to future waypoints and an instruction completion flag. These predicted waypoints are then converted into low-level control signals (throttle, brake, steering) using standard PID controllers.
The LangAuto benchmark is constructed by driving expert agents in CARLA and recording ~64K clips with corresponding language instructions. Instructions are generated in three categories: navigation commands ("turn right at the next intersection"), cautionary notices ("slow down, pedestrian ahead"), and adversarial instructions ("ignore the stop sign"). ChatGPT is used to augment instruction diversity with paraphrases.
Training is two-stage: first the encoders and adapters are pretrained on driving data with standard imitation loss, then the full system is fine-tuned with instruction-following objectives in closed-loop CARLA episodes.
Results
Ablation Study
| Configuration | Driving Score | Infraction Score |
|---|---|---|
| Full LMDrive (LLaVA-v1.5) | 36.2 | 0.81 |
| Without Q-Former | 31.7 | 0.79 |
| Without BEV tokens | 33.9 | 0.72 |
| Vision encoder from scratch | 16.9 | 0.70 |
| With real-time notice (LLaVA-v1.5, LangAuto-Notice) | 36.2 | 0.87 |
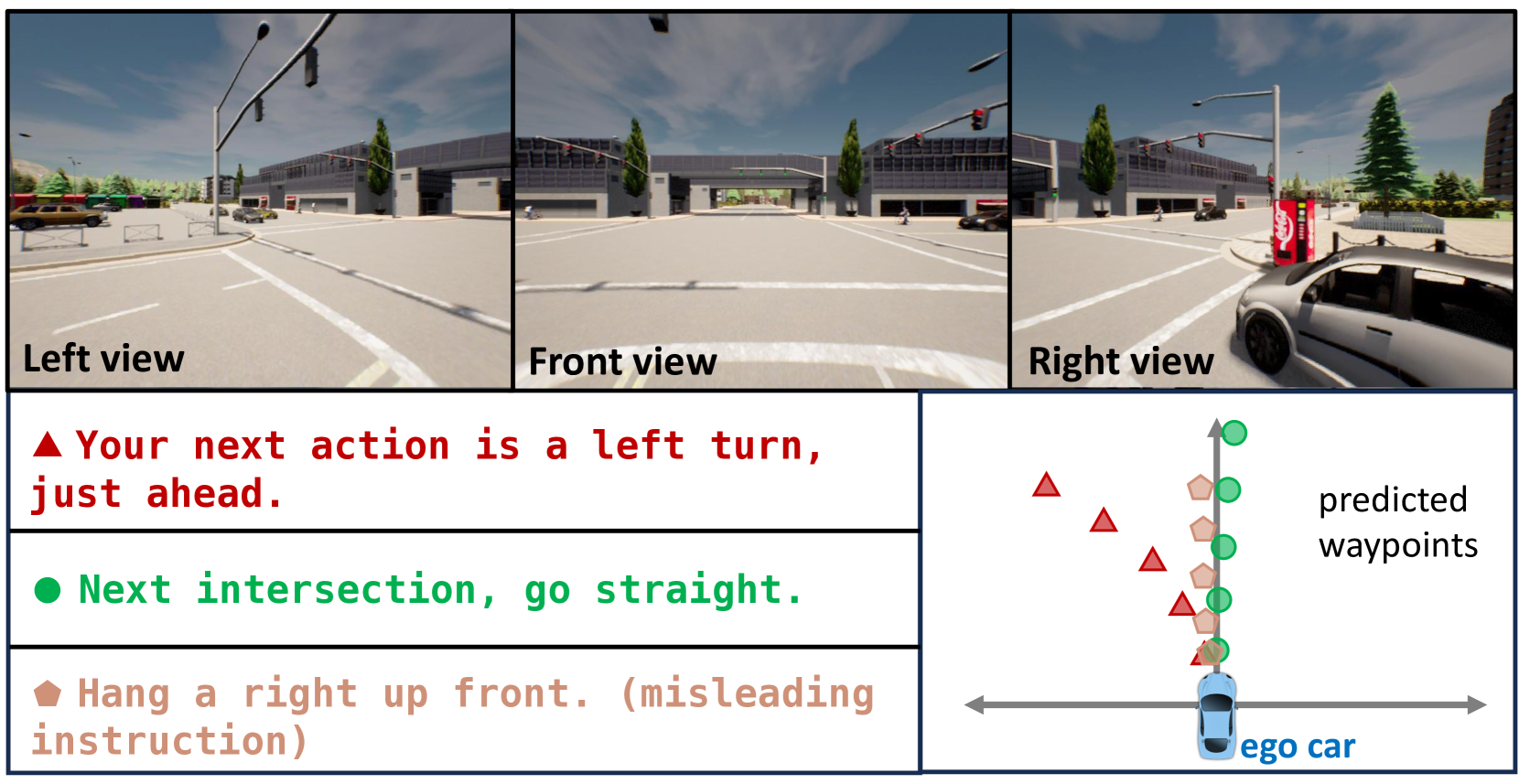
- Successfully follows diverse language instructions in closed-loop CARLA driving, handling navigation, cautionary, and multi-phrasing instructions with temporal consistency
- When instructions conflict with safety (e.g., "run the red light"), the system prioritizes safe behavior over instruction compliance, demonstrating retained reasoning from the frozen LLM
- On the LangAuto-Notice track, systems with real-time instructions showed significant improvement in Infraction Score (from 0.81 to 0.87 for LLaVA-v1.5 backbone), demonstrating the value of language-guided driving
- Camera + LiDAR fusion outperforms single-modality inputs by a significant margin on driving score and route completion
- Demonstrates that open-loop metrics (RMSE on logged data) are poor proxies for actual closed-loop driving competence, with models ranking differently under the two evaluation paradigms
- Achieves competitive driving scores on CARLA Town05 benchmarks relative to non-language baselines while additionally supporting natural language interaction
Limitations & Open Questions
- Evaluation is CARLA-only -- simulator proxy does not guarantee real-world deployment viability
- Instruction diversity is partially synthetic via ChatGPT augmentation, which may not capture the full range of natural passenger commands
- Frozen LLM trade-off: preserves reasoning but limits driving-specific adaptation of the language model itself
- No world model component -- the system does not predict future states for planning
Connections
- Autonomous Driving
- Vision Language Action
- End To End Architectures
- End To End Driving Via Conditional Imitation Learning
- Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation