Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
Overview
Driving with LLMs (Wayve, ICRA 2024) is one of the first concrete demonstrations of using a large language model as the decision-making "brain" for autonomous driving. The paper addresses the "black box" problem in E2E driving by fusing object-level vector representations with a frozen LLaMA-7B model, enabling both driving action prediction and natural language explanations of driving decisions.
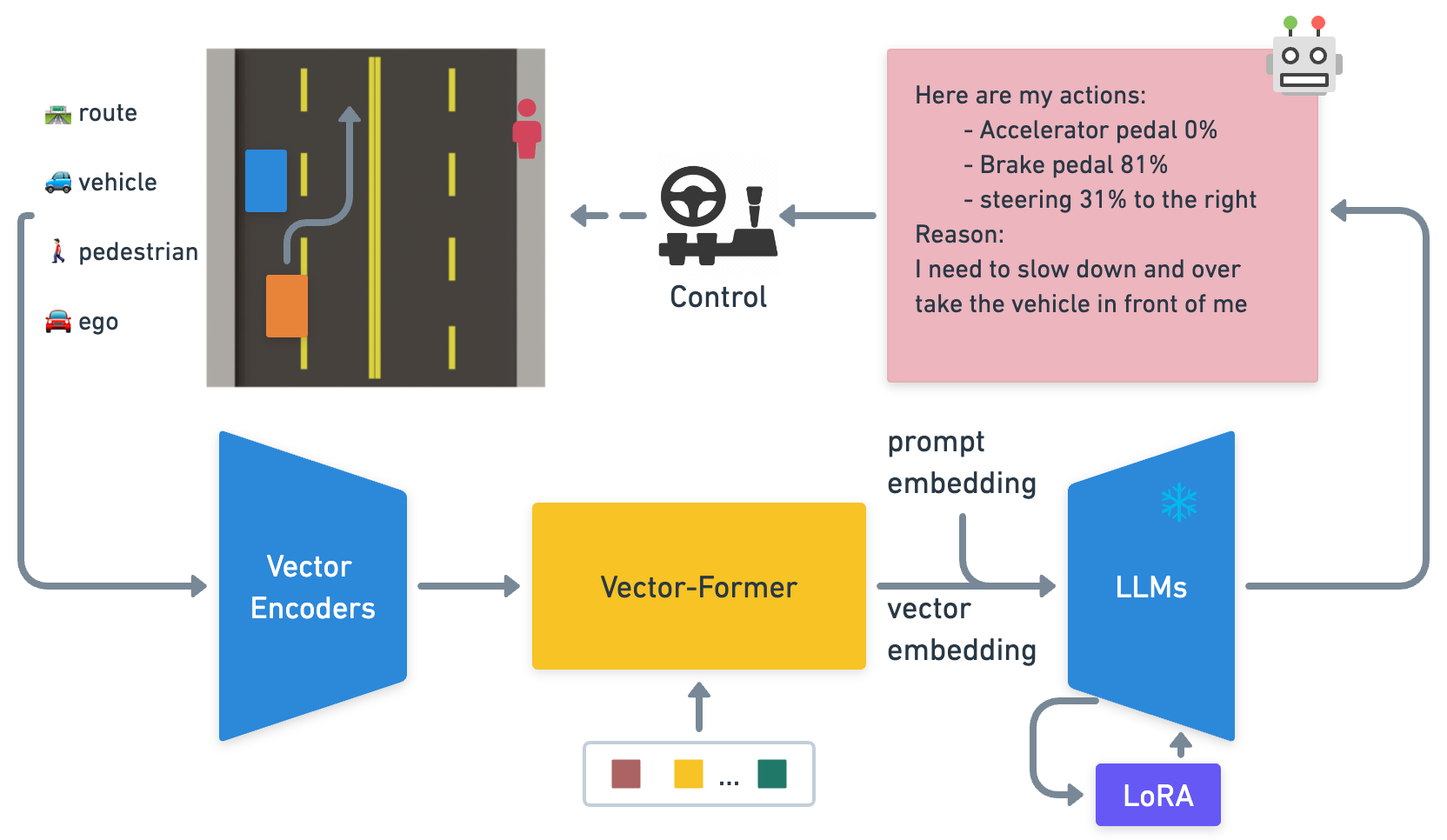
The system introduces a novel three-component architecture (Vector Encoder, Vector Former, and LLM with LoRA) trained in two stages: vector representation pretraining followed by driving QA finetuning. A key innovation is the data generation pipeline using a PPO-trained RL agent in a custom 2D simulator, with a lanGen function translating vector state into natural language, and GPT-3.5 generating 160k QA pairs for training. The system demonstrates improved perception and action prediction while providing interpretable explanations.
Key Contributions
- First concrete LLM-for-driving system: Among the earliest papers to demonstrate a working LLM integrated into an autonomous driving pipeline with measurable driving performance
- Object-level vector modality: Novel approach of representing driving scenes as vectorized object-level features (positions, velocities, types) rather than raw images, enabling efficient LLM integration
- Two-stage training pipeline: Vector representation pretraining captures driving-relevant features before QA finetuning aligns the model with language-based driving reasoning
- Scalable data generation: Uses PPO-trained RL agent + GPT-3.5 to generate 160k driving QA pairs, establishing a template for LLM driving data creation
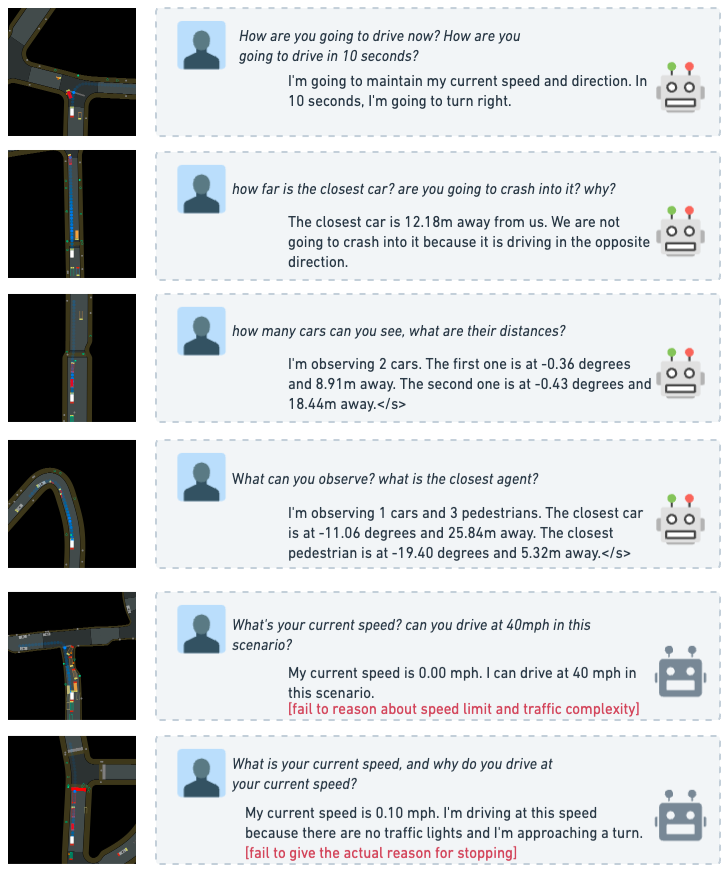
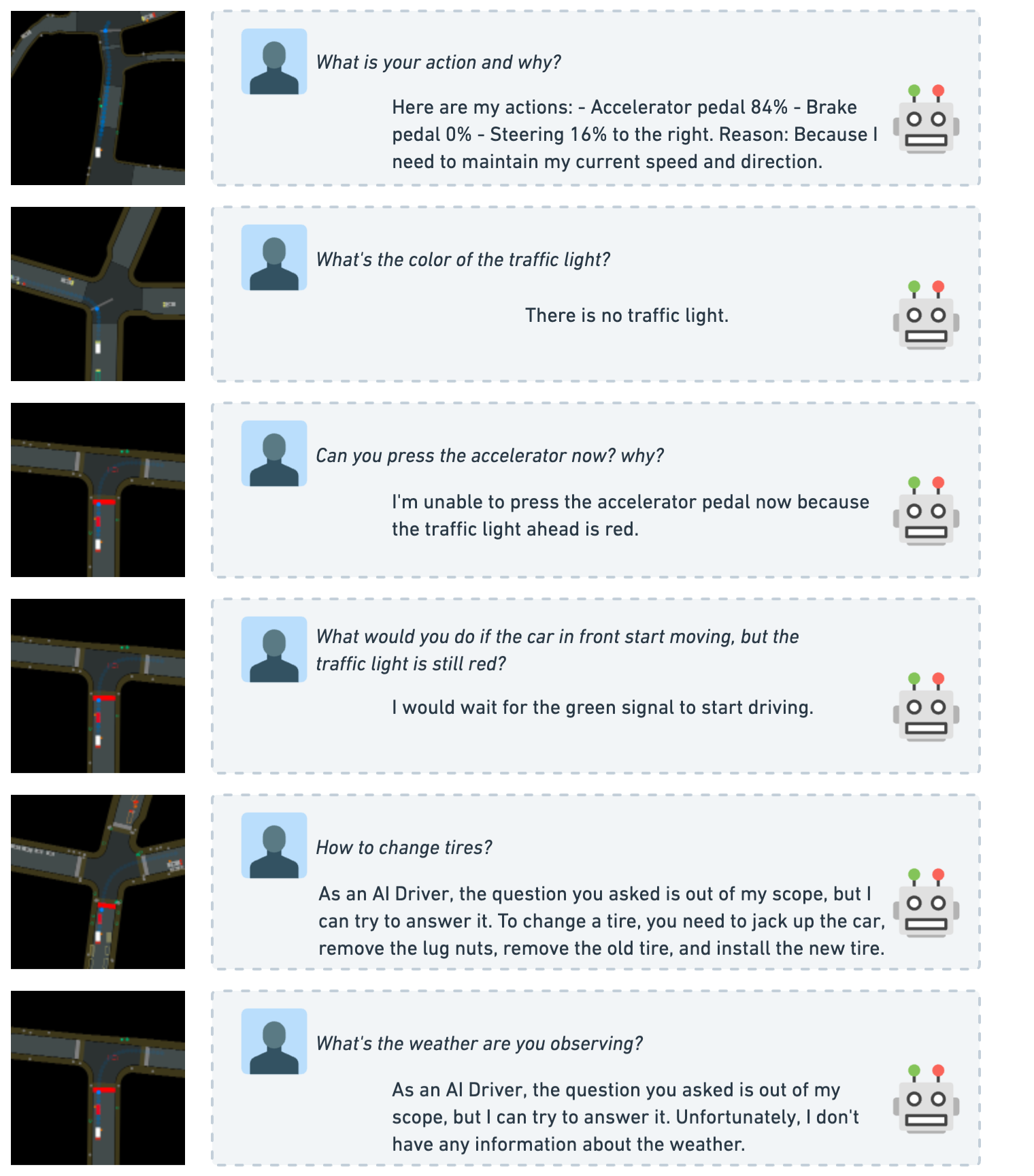
- Explainable decision-making: The LLM can articulate reasons for its driving decisions in natural language, addressing the black-box problem
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ Driving with LLMs: Vector-to-Language Pipeline │
│ │
│ Driving Scene (from custom 2D simulator) │
│ ┌────────────────────────────────────────┐ │
│ │ Object Vectors: [pos, vel, heading, │ │
│ │ dims, type] for each agent + road │ │
│ │ elements + ego state │ │
│ └──────────────────┬─────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Vector Encoder │ │
│ │ (per-object feature embed) │ │
│ └──────────────┬───────────────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Vector Former │ │
│ │ (Transformer self-attn │ │
│ │ across all object tokens) │ │
│ │ ──► Fixed-size scene embed │ │
│ └──────────────┬───────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────┐ │
│ │ Frozen LLaMA-7B + LoRA │ │
│ │ Input: [scene embed] + [text query] │ │
│ │ Output: action tokens + explanation │ │
│ └──────────────────────────────────────────┘ │
│ │
│ Two-Stage Training: │
│ ┌──────────────┐ ┌──────────────────────┐ │
│ │ Stage 1: │ │ Stage 2: │ │
│ │ Vector │─────►│ Driving QA Finetuning│ │
│ │ Pretraining │ │ (160k QA pairs from │ │
│ │ (perception) │ │ PPO agent + GPT-3.5)│ │
│ └──────────────┘ └──────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
The architecture consists of three main components:
1. Vector Encoder
Encodes the driving scene as a set of object-level vectors: - Each traffic participant is represented by a feature vector: position (x, y, z), velocity (vx, vy), heading, dimensions, and object type - Road elements (lanes, traffic lights, signs) are similarly vectorized - Ego vehicle state (velocity, acceleration, heading) is included - Cross-attention layers map inputs into latent space; ego vehicle features are added to each learned latent vector to maintain consistent self-awareness
2. Vector Former
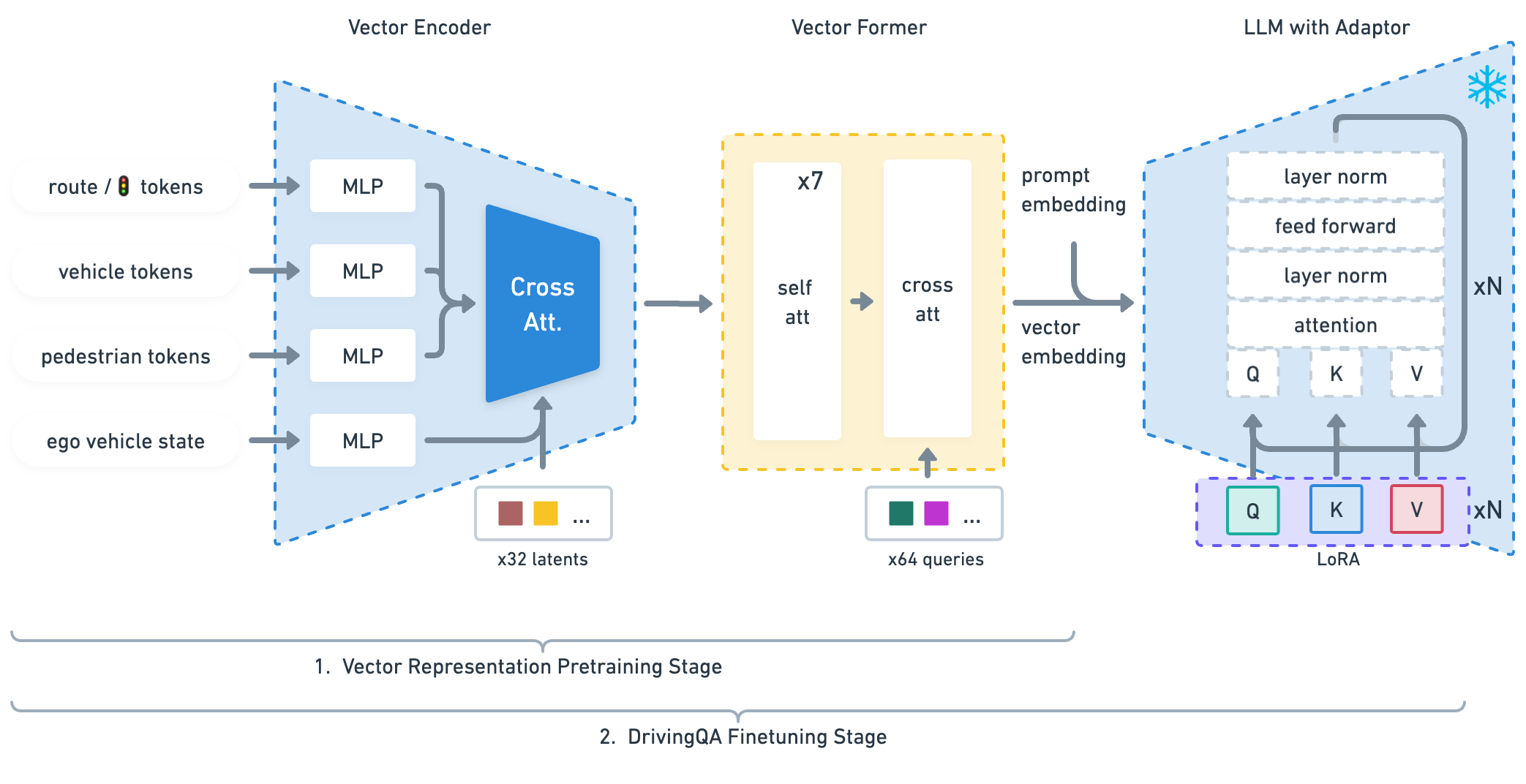
A transformer module that processes the vectorized scene: - Self-attention and cross-attention layers interact between latent space and question tokens - Generates 64 queries that serve as the fixed-size interface between the numeric vector representation and the LLM's token space - Acts as a bridge between the vector representation and the LLM's token space
3. Frozen LLaMA-7B with LoRA
The scene embedding from Vector Former is projected into the LLM's input space: - LLaMA-7B is kept frozen; only LoRA adapters are trained - Input: scene embedding tokens + text query tokens - Output: driving action tokens + natural language explanation
Training Pipeline
Stage 1 -- Vector Pretraining: The Vector Encoder and Vector Former are pretrained on 100k pseudo vector-captioning QA pairs (derived from 100k simulated scenarios) to learn driving-relevant representations. The language model remains frozen during this stage.
Stage 2 -- QA Finetuning: The full system (Vector Former + LoRA adapters) is finetuned on 160k driving QA pairs:
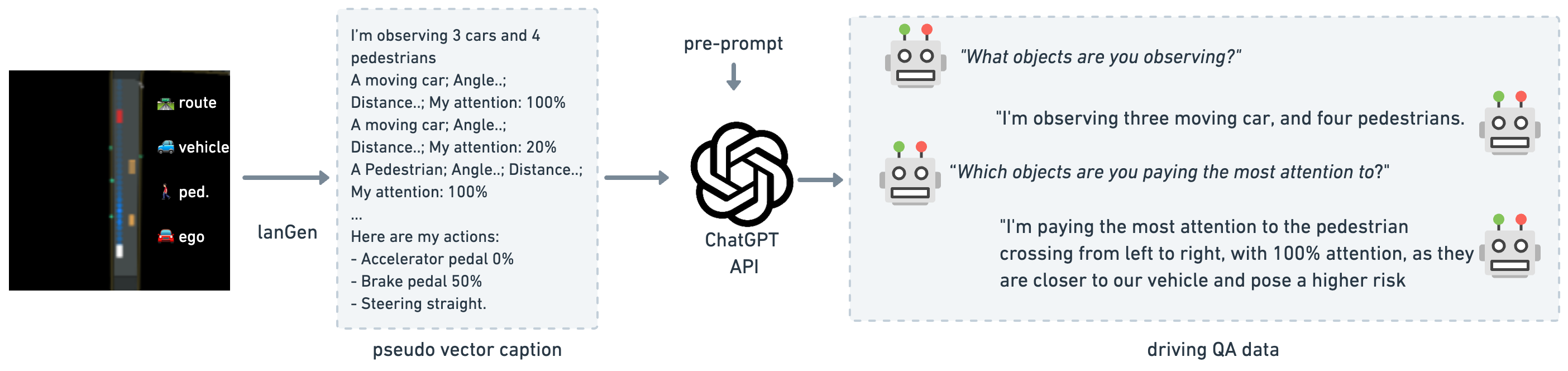
- A PPO-trained RL agent drives in the custom 2D simulator
- The
lanGenfunction translates simulator state vectors into structured natural language descriptions - GPT-3.5 generates diverse question-answer pairs about driving decisions, perceptions, and explanations
- Questions cover: "What should you do?", "Why?", "How many cars ahead?", "What is the speed limit?"
Results
Perception (Mean Absolute Error):
| Metric | Without Pretraining | With Pretraining |
|---|---|---|
| Car count MAE | 0.101 | 0.066 |
| Pedestrian count MAE | 1.668 | 0.313 |
| Token prediction loss (L_token) | 0.644 | 0.502 |
Action prediction vs. Perceiver-BC baseline:
| Control axis | LLM-Driver | Perceiver-BC |
|---|---|---|
| Longitudinal error | 0.066 | 0.180 |
| Lateral error | 0.014 | 0.111 |
Driving QA scores (0–10 scale):
| Grader | Without Pretraining | With Pretraining |
|---|---|---|
| GPT-3.5 automated | 7.48 | 8.39 |
| Human | 6.63 | 7.71 |
- Pretraining substantially improves perception: Car count MAE drops from 0.101 to 0.066 and pedestrian count MAE drops from 1.668 to 0.313 with vector pretraining
- Strong action prediction: LLM-Driver outperforms Perceiver-BC substantially on longitudinal (0.066 vs 0.180) and lateral (0.014 vs 0.111) control error
- Traffic light distance regression: Perceiver-BC (D_TL: 0.410) outperforms LLM-Driver (D_TL: 6.624) on this specific regression task, a known weakness of the approach
- QA quality improves ~9–11% with pretraining: GPT grading 8.39 vs 7.48; human grading 7.71 vs 6.63
- Multi-task capability: A single model handles perception queries, action prediction, and explanation generation
Limitations & Open Questions
- Simulation only: All experiments are in a custom 2D simulator; real-world transfer is not demonstrated
- Open-loop evaluation: No closed-loop driving evaluation; the LLM predicts actions but does not drive in a feedback loop
- Vector input only: Does not process raw camera images, limiting applicability to scenarios where a good perception system is already available
- Frozen LLM: LLaMA-7B is not fine-tuned end-to-end; full fine-tuning might unlock better integration
- Latency concerns: LLM inference at 7B parameters may be too slow for real-time driving (not measured in paper)
- GPT-3.5 data quality: Generated QA pairs may contain errors or inconsistencies that limit training quality
- Numeric regression weakness: On traffic light distance estimation, Perceiver-BC (D_TL: 0.410) substantially outperforms LLM-Driver (D_TL: 6.624), indicating the LLM struggles with precise numeric regression tasks
Connections
- Autonomous Driving -- LLM integration in driving systems
- Planning -- language-model-based planning
- Vision Language Action -- early driving VLA work
- Language Models Are Few Shot Learners -- GPT-3, foundation for LLM capabilities
- Gpt Driver Learning To Drive With Gpt -- concurrent LLM-for-planning approach
- Lmdrive Closed Loop End To End Driving With Large Language Models -- subsequent closed-loop LLM driving
- Drivelm Driving With Graph Visual Question Answering -- subsequent driving QA approach
- Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model -- concurrent multimodal instruction tuning for driving