DriveLM: Driving with Graph Visual Question Answering
Overview
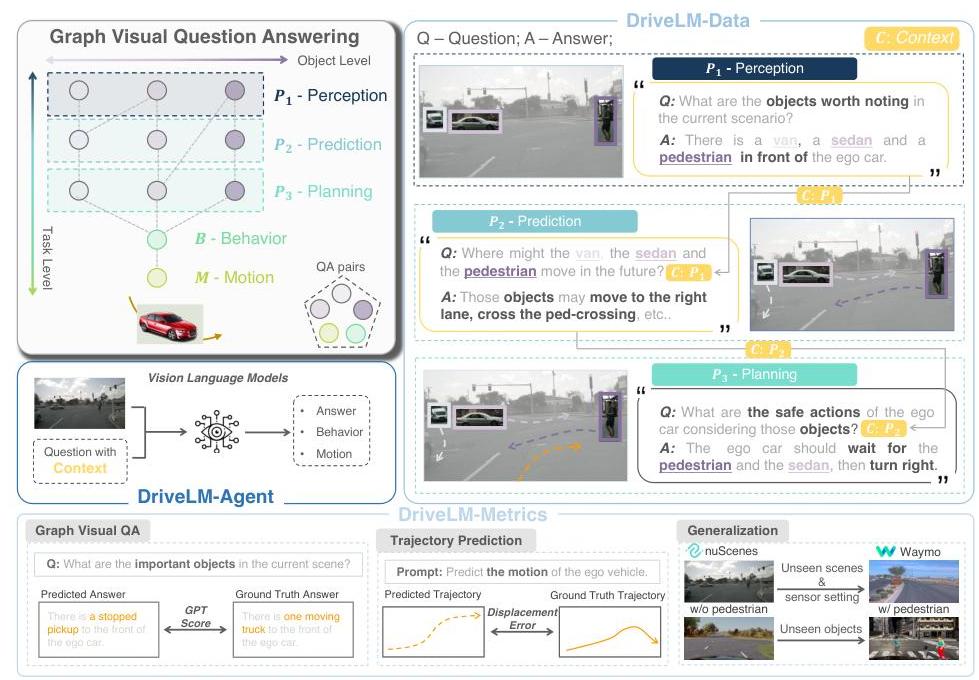
DriveLM formalizes driving reasoning as Graph Visual Question Answering (GVQA), where QA pairs are connected via logical dependencies forming a reasoning graph that spans the full driving stack from perception through prediction, planning, behavior, and motion. Rather than treating driving scene understanding as a set of independent questions, the paper recognizes that driving requires multi-step reasoning with explicit causal dependencies: identifying objects leads to predicting their motion, which informs planning decisions, which determine behavioral choices, which finally produce trajectory waypoints.
The core insight is that single-round VQA is an insufficient proxy for the reasoning required in autonomous driving. When approaching an intersection, a driver reasons about what objects are present, how they will move, what traffic rules apply, what behavior to take, and what trajectory to follow. These are logically dependent steps, not independent questions. DriveLM's GVQA framework captures these dependencies explicitly, exposing reasoning failures that flat QA would miss.
With an ECCV Oral acceptance and substantial citation impact, DriveLM-Data has become a widely-adopted benchmark covering the full reasoning stack. The graph-structured reasoning framing is increasingly used as a bridge between VLM reasoning and action generation in subsequent work on language-conditioned autonomous driving.
Key Contributions
- Graph Visual Question Answering (GVQA) framework: First formalization of driving reasoning as a dependency graph where QA pairs have explicit parent dependencies -- perception QAs feed prediction QAs, which feed planning QAs, then behavior tokens, then motion output
- DriveLM-Data benchmark: Graph-structured QA dataset built on nuScenes and CARLA covering the full driving stack (Perception -> Prediction -> Planning -> Behavior -> Motion), with each node having explicit parent dependencies
- DriveLM-Agent baseline: VLM model that uses DriveLM-Data for both GVQA reasoning and end-to-end driving, demonstrating that graph-structured reasoning can coexist with trajectory prediction
- Graph consistency metrics: Evaluation beyond standard QA accuracy to measure reasoning coherence across dependent steps in the graph
- Full-stack coverage: Unlike prior work that addressed single reasoning stages, DriveLM spans from "what objects are present?" through to continuous trajectory waypoints
Architecture / Method
┌───────────────────────────────────────────────────────────────┐
│ DriveLM: Graph VQA Reasoning Pipeline │
│ │
│ Reasoning DAG (per driving scene): │
│ │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │ Perception │ │ Perception │ │ Perception │ │
│ │ QA: "What │ │ QA: "Where │ │ QA: "What │ │
│ │ objects?" │ │ is car A?" │ │ is signal?"│ │
│ └─────┬──────┘ └─────┬──────┘ └──────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ │ │
│ ┌────────────┐ ┌────────────┐ │ │
│ │ Prediction │ │ Prediction │ │ │
│ │ QA: "Will │ │ QA: "Car A │ │ │
│ │ ped cross?"│ │ trajectory"│ │ │
│ └─────┬──────┘ └─────┬──────┘ │ │
│ └────────┬────────┘ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ Planning QA: "What should ego do?" │ │
│ └──────────────────┬───────────────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Behavior Token │ │
│ │ (discrete decision) │ │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Motion Waypoints │ │
│ │ (256-bin tokenized) │ │
│ └──────────────────────┘ │
│ │
│ DriveLM-Agent Model: │
│ ┌──────────┐ ┌──────────────────────────────┐ │
│ │ Multi-cam│───►│ BLIP-2 VLM + Graph Context │ │
│ │ Images │ │ (parent QA answers prepended) │──► QA + Traj│
│ └──────────┘ └──────────────────────────────┘ │
└───────────────────────────────────────────────────────────────┘
DriveLM constructs a directed acyclic graph (DAG) of QA pairs for each driving scene. Each node in the graph is a question-answer pair belonging to one of five stages: Perception (P), Prediction (Pred), Planning (Plan), Behavior (B), and Motion (M). Edges represent logical dependencies -- a prediction node depends on the perception nodes that identify the relevant agents, and a planning node depends on the prediction nodes that forecast those agents' future states.
The DriveLM-Data annotation process involves: (1) defining key objects in the scene, (2) generating perception QAs about object properties and positions, (3) creating prediction QAs about future states conditioned on perception answers, (4) producing planning QAs that reason about appropriate responses, (5) generating behavior tokens (discrete driving decisions), and (6) outputting continuous motion waypoints. The graph structure enforces that each QA at a later stage references specific earlier QAs as dependencies.
The DriveLM-Agent model builds on the BLIP-2 Vision-Language Model architecture and is fine-tuned on this graph-structured data. Context from parent nodes is appended as prefixes to child questions during both training (using ground truth context) and inference (using model predictions). A trajectory tokenization module discretizes waypoint coordinates into 256 bins, enabling continuous trajectory generation through the language model's token prediction. During inference, the model processes QA pairs sequentially following the graph ordering, using answers from earlier stages as context for later stages.
Evaluation uses comprehensive metrics across three categories: motion metrics (ADE, FDE, collision rates), behavior metrics (classification accuracy), and VQA metrics (SPICE and a novel GPT Score measuring semantic alignment). Novel graph consistency metrics that measure whether the model maintains coherent reasoning across dependent steps. If a model correctly identifies a pedestrian but incorrectly predicts they will stay still, the graph-based evaluation exposes this broken chain rather than scoring each QA independently.
Results
- GVQA forces reasoning coherence across steps: models must maintain consistency across dependent QA pairs, and graph structure exposes broken reasoning chains that flat QA scoring would miss
- DriveLM-Agent achieves competitive end-to-end driving performance versus state-of-the-art architectures while being interpretable, with superior zero-shot generalization across sensor configurations and remarkable adaptability to novel objects when contextual questions are provided
- Cross-domain coverage via nuScenes + CARLA data provides both real-world and simulation scenarios for training and evaluation. DriveLM-CARLA uses fully automated annotation via PDM-Lite (a rule-based expert algorithm), generating 1.6M question-answer pairs -- the largest driving-language benchmark at time of publication
- The graph structure reveals failure modes invisible to standard metrics: cascading errors in reasoning chains become detectable through dependency tracking
- DriveLM-Data has been adopted as a standard benchmark by numerous subsequent VLA driving papers
Limitations & Open Questions
- QA generation is partially synthetic, and GPT-based scoring can be noisy -- the quality of automatic evaluation remains a challenge
- Graph structure may not match how real users interact with driving systems, raising questions about ecological validity
- Reasoning correctness does not guarantee driving safety -- a model can reason correctly yet still produce unsafe trajectories
Connections
- Vision Language Action
- Autonomous Driving
- Foundation Models
- Textual Explanations For Self Driving Vehicles
- Gpt Driver Learning To Drive With Gpt
- Reason2Drive Towards Interpretable And Chain Based Reasoning For Autonomous Driving
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Emma End To End Multimodal Model For Autonomous Driving