Overview
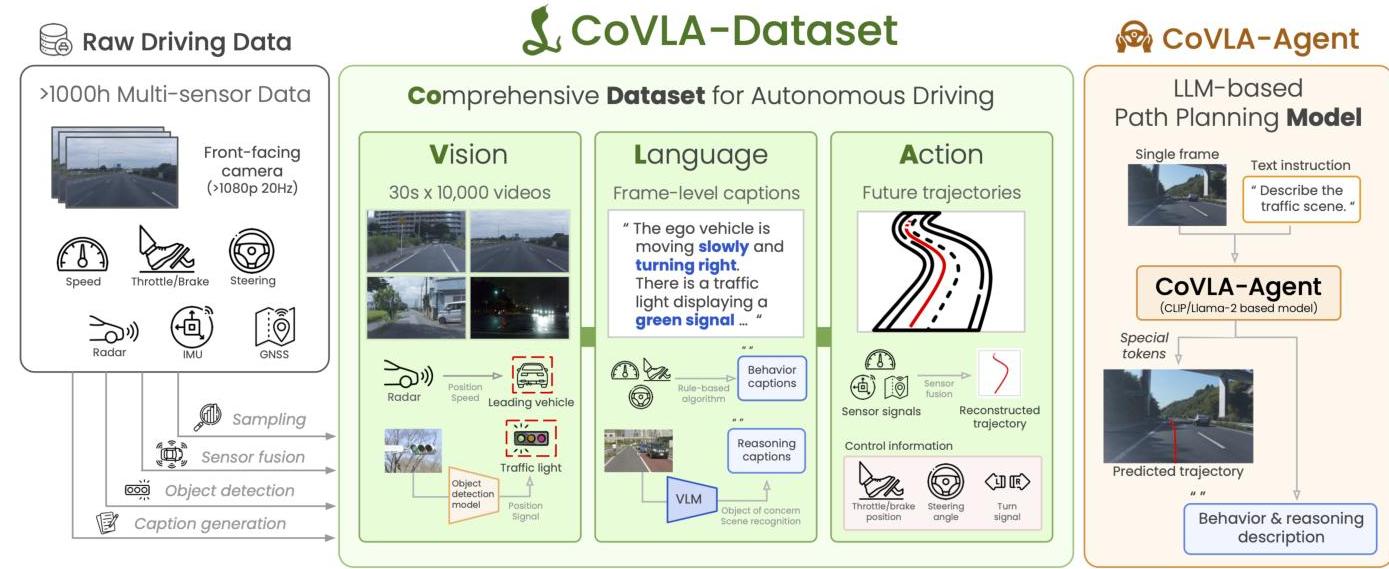
Autonomous driving systems face the "long tail" problem -- handling countless rare and complex driving scenarios beyond common situations. While traditional rule-based pipelines and even recent end-to-end methods rely on fixed perception-planning decompositions, Vision-Language-Action (VLA) models offer a path toward more human-like reasoning. However, a critical bottleneck has been the lack of large-scale datasets that jointly provide visual data, detailed language descriptions, and fine-grained driving actions. CoVLA directly addresses this by constructing the first large-scale dataset that comprehensively integrates vision, language, and action annotations for autonomous driving.
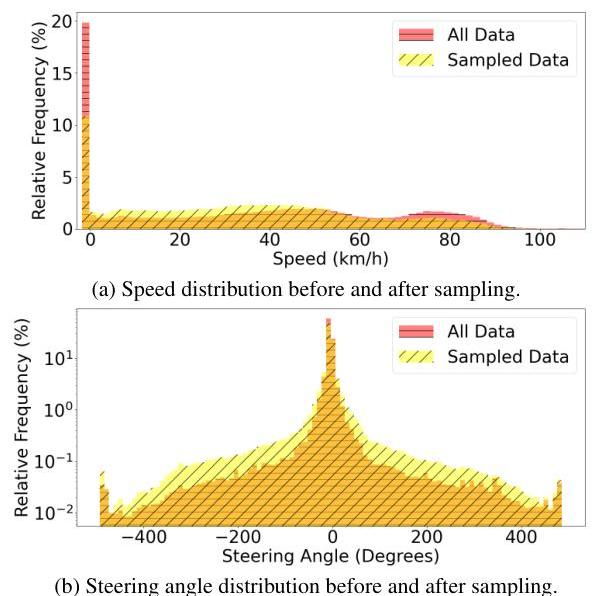
The authors (from Turing Inc., Japan) collected over 1,000 hours of raw driving data in and around Tokyo, Japan using instrumented vehicles equipped with cameras, CAN bus, GNSS, and IMU sensors. From this raw data, they produced 10,000 diverse 30-second scenes totaling approximately 6,000,000 annotated frames. Each frame is annotated with future trajectory predictions (from Kalman-filtered GNSS/IMU), traffic light states (from OpenLenda-s detection), and natural language captions (from a two-stage pipeline combining rule-based descriptions with VideoLLaMA2 VLM enhancement). A key design choice is the weighted inverse-probability sampling strategy based on steering angle, acceleration, and turn signal status, which significantly improves representation of complex and rare maneuvers.
As a baseline, the paper introduces CoVLA-Agent, a VLA model integrating a CLIP ViT-L vision encoder, Llama-2 language model, MLP-based speed embedding, and specialized trajectory prediction heads. With ground-truth captions, CoVLA-Agent achieves 0.814m ADE and 1.655m FDE; with predicted captions, 0.955m ADE and 2.239m FDE -- demonstrating that caption quality significantly impacts trajectory prediction accuracy. The paper was accepted as an oral presentation at WACV 2025.
Key Contributions
- First large-scale VLA dataset for driving -- 10,000 scenes, 6M frames with joint vision, language, and trajectory annotations, collected in real Tokyo driving conditions
- Scalable automated annotation pipeline -- combines Kalman-filtered trajectory generation, deep learning traffic light detection, and two-stage VLM captioning (rule-based + VideoLLaMA2), avoiding prohibitive manual annotation costs
- Intelligent diversity sampling -- inverse probability weighting on steering angle, acceleration, and turn signals ensures rare maneuvers (turns, hard braking, lane changes) are well-represented
- CoVLA-Agent baseline model -- demonstrates that jointly training on captions and trajectories improves driving performance, and quantifies the gap between ground-truth and predicted caption quality
- Error analysis of VLM captioning -- identifies systematic issues in automated captioning including object hallucination, spatial relationship errors, and limited understanding of local Japanese traffic contexts
Architecture / Method
Dataset Construction Pipeline
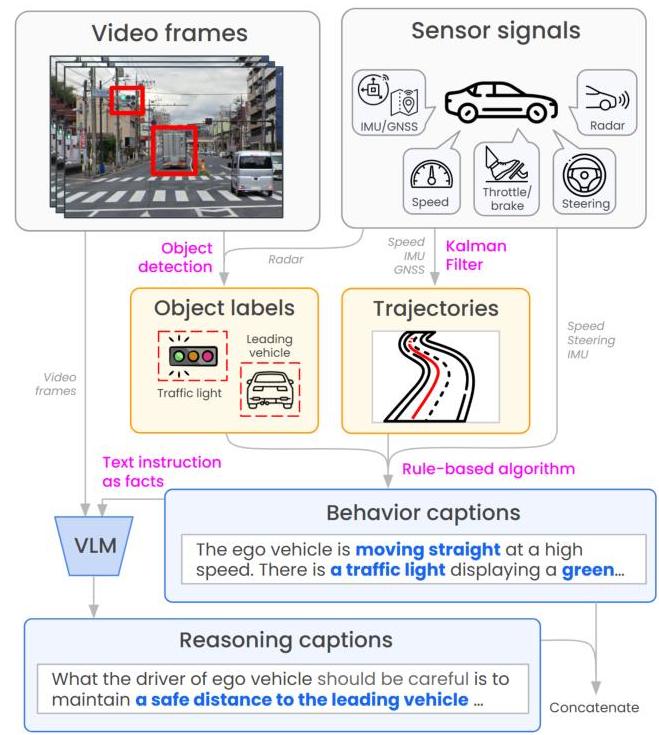
Data collection: 1,000+ hours of front-camera video from Tokyo driving, with synchronized CAN bus, GNSS, and IMU sensor streams.
Intelligent sampling: Rather than uniform sampling, CoVLA uses inverse probability weighting across three dimensions: - Steering angle distribution (over-samples sharp turns) - Acceleration distribution (over-samples hard braking/acceleration events) - Turn signal status (over-samples signaled maneuvers; turn signals active in 16.11% of frames vs ~5% in uniform sampling)
Trajectory annotation: Kalman Filter fusion of GNSS and IMU data produces future ego-vehicle trajectories for each frame.
Traffic light detection: OpenLenda-s deep learning model detects and classifies traffic light states across frames (traffic lights present in 22.90% of scenes).
Two-stage captioning pipeline: 1. Rule-based stage: generates structured descriptions from sensor data (speed, steering, turn signals, traffic lights) following templates 2. VLM enhancement stage: VideoLLaMA2 processes the video clip and rule-based caption together to produce naturalistic, context-rich descriptions incorporating visual scene understanding
CoVLA-Agent Model
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ Front Camera │ │ Caption (text) │ │ Ego Speed │
│ Image │ │ (GT or pred.) │ │ │
└──────┬───────┘ └────────┬─────────┘ └──────┬───────┘
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ CLIP ViT-L │ │ Llama-2 (7B) │ │ MLP Speed │
│ /14 Encoder │ │ Tokenizer + │ │ Embedding │
└──────┬───────┘ │ Language Model │ └──────┬───────┘
│ └────────┬─────────┘ │
│ Visual │ Language │
│ Features │ Features │
└────────────┬───────┴─────────┬───────────┘
│ Fused │
▼ ▼
┌────────────────┐ ┌──────────────────┐
│ Caption Head │ │ Trajectory Head │
│ (LM Cross- │ │ (MLP Regression)│
│ Entropy) │ │ (L2 Loss) │
└────────────────┘ └──────────────────┘
Joint Training Loss = Caption Loss + Trajectory Loss (1:1)
The baseline model architecture combines: - Vision encoder: CLIP ViT-L/14 processes front-camera images into visual features - Language model: Llama-2 (7B) processes and generates natural language captions - Speed embedding: MLP encodes current ego-vehicle speed as a conditioning signal - Trajectory prediction head: specialized MLP layers predict future waypoints
Training uses a joint loss combining caption generation (language modeling cross-entropy) and trajectory prediction (L2 regression) with equal weighting (1:1 ratio).
Results

Dataset Statistics
| Statistic | Value |
|---|---|
| Total scenes | 10,000 |
| Scene duration | 30 seconds |
| Total annotated frames | ~6,000,000 |
| Turn signal activation rate | 16.11% |
| Traffic light presence rate | 22.90% |
| Raw data collected | 1,000+ hours |
| Collection location | In and around Tokyo, Japan |
Trajectory Prediction Performance
| Setting | ADE (m) | FDE (m) |
|---|---|---|
| CoVLA-Agent (GT captions) | 0.814 | 1.655 |
| CoVLA-Agent (predicted captions) | 0.955 | 2.239 |
The 17% ADE degradation and 35% FDE degradation when switching from ground-truth to predicted captions highlights the sensitivity of trajectory prediction to caption quality, and motivates future work on improving automated captioning.
Caption Quality Analysis
Motion direction and acceleration descriptions proved particularly challenging for the automated VLM pipeline. Error analysis revealed three systematic failure modes: - Object hallucination (describing objects not present in the scene) - Spatial relationship misidentification (incorrect left/right/ahead descriptions) - Limited understanding of local Japanese traffic contexts (signs, road markings, driving conventions)
Limitations & Open Questions
- Geographic bias: All data collected in and around Tokyo -- generalization to other cities, countries, and driving cultures is untested
- Single front camera: Only front-view video is used, limiting perception of side and rear traffic
- VLM captioning quality: Automated captions contain systematic errors (hallucination, spatial confusion), and the 35% FDE gap between GT and predicted captions shows this is a bottleneck
- Open-loop evaluation only: CoVLA-Agent is evaluated in open-loop; closed-loop driving performance and sim-to-real transfer are not addressed
- No comparison to other VLA datasets: The paper does not directly compare CoVLA to other driving language datasets (DriveLM, Reason2Drive, BDD-X) on shared benchmarks
- Does scaling language quality (better VLMs for captioning) close the GT-predicted gap, or are there fundamental limits to automated annotation?
- Can the weighted sampling strategy be extended to automatically discover and over-sample novel or challenging scenarios beyond the three predefined dimensions?
Connections
Related papers in the wiki:
- Drivelm Driving With Graph Visual Question Answering -- another driving VQA/language dataset, uses structured graph reasoning rather than free-form captions
- Reason2Drive Towards Interpretable And Chain Based Reasoning For Autonomous Driving -- large-scale video-text reasoning chain dataset for driving, complementary annotation approach
- Textual Explanations For Self Driving -- BDD-X, the original driving language dataset with attention-aligned explanations
- Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model -- multimodal instruction tuning for joint control and explanation, similar joint caption+action objective
- Autovala Vision Language Action Model For End To End Autonomous Driving -- VLA model that could benefit from CoVLA-scale data
- S4 Driver Scalable Self Supervised Driving Mllm With Spatio Temporal Visual Representation -- self-supervised MLLM approach that avoids manual annotation entirely, different philosophy from CoVLA's automated annotation
- Nuscenes A Multimodal Dataset For Autonomous Driving -- canonical multi-sensor driving dataset, CoVLA extends the paradigm with language annotations
- Vision Language Action -- broader context on VLA systems and the role of language in driving
- Autonomous Driving -- autonomous driving overview and era taxonomy