DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model
Citation
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K. Wong, Zhenguo Li, Hengshuang Zhao, IEEE Robotics and Automation Letters, 2024.
Overview
DriveGPT4 applies LLaVA-style multimodal instruction tuning to autonomous driving, building a driving-specific visual instruction dataset from BDD-X via ChatGPT and training a VLM that simultaneously predicts control signals and generates natural-language descriptions and justifications. It established the widely-copied recipe of driving-domain visual instruction tuning with joint language and control output.
As the highest-cited driving VLM in the early VLA driving corpus, DriveGPT4 demonstrated that the general-purpose multimodal instruction tuning approach (CLIP vision encoder + LLaMA2 with full fine-tuning) could be adapted to the driving domain. By expanding the BDD-X dataset into diverse instruction-following QA pairs using ChatGPT, it made BDD-X the de facto benchmark for language+control models and accelerated the "VLM agent" framing for driving.
The work's open-loop-only evaluation was an important limitation that motivated critical follow-ups like LMDrive and SimLingo, which moved to closed-loop settings where compounding errors and interactive behavior could be properly tested. Nevertheless, DriveGPT4's template -- vision encoder feeding into an instruction-tuned LLM producing both controls and explanations -- became the standard starting point for subsequent driving VLA research.
Key Contributions
- Driving-domain multimodal instruction tuning: Adapts an MLLM recipe (CLIP vision encoder + LLaMA2 with full fine-tuning) specifically for driving, treating both control prediction and language generation as instruction-following tasks
- ChatGPT-augmented BDD-X training data: Expands BDD-X's action descriptions and justifications into diverse instruction-following QA pairs, creating a rich driving-specific instruction dataset
- Joint control + language multi-task output: Single model simultaneously predicts speed/turning angle and generates action descriptions, justifications, and scene narrations without degrading either capability
- Open-loop control evaluation protocol: Speed RMSE, turning angle RMSE, and threshold accuracies on BDD-X alongside language quality metrics
- Established the VLM driving agent template: Vision encoder feeding into an instruction-tuned LLM producing both controls and explanations
Architecture / Method
┌───────────────────────────────────────────────────────────┐
│ DriveGPT4 Architecture │
│ │
│ ┌─────────────┐ │
│ │ Video Frames │ │
│ │ (BDD-X) │ │
│ └──────┬───────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ CLIP ViT-L/14 │ (Frozen) │
│ │ Vision Encoder │ │
│ └──────┬──────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Linear Projection│ Visual tokens ──► LLM embedding │
│ └──────┬──────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────┐ │
│ │ LLaMA2 LLM │ │
│ │ ┌───────────────────────────────────────┐ │ │
│ │ │ Input: [visual tokens] + [instruction]│ │ │
│ │ └───────────────┬───────────────────────┘ │ │
│ │ ▼ │ │
│ │ ┌──────────────────────────────────────┐ │ │
│ │ │ Multi-Task Output Heads │ │ │
│ │ │ ├─► Control: speed, turning angle │ │ │
│ │ │ ├─► Action description (text) │ │ │
│ │ │ ├─► Action justification (text) │ │ │
│ │ │ └─► Scene narration (text) │ │ │
│ │ └──────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────┘
Training Data Pipeline:
BDD-X annotations ──► ChatGPT expansion ──► Diverse QA pairs
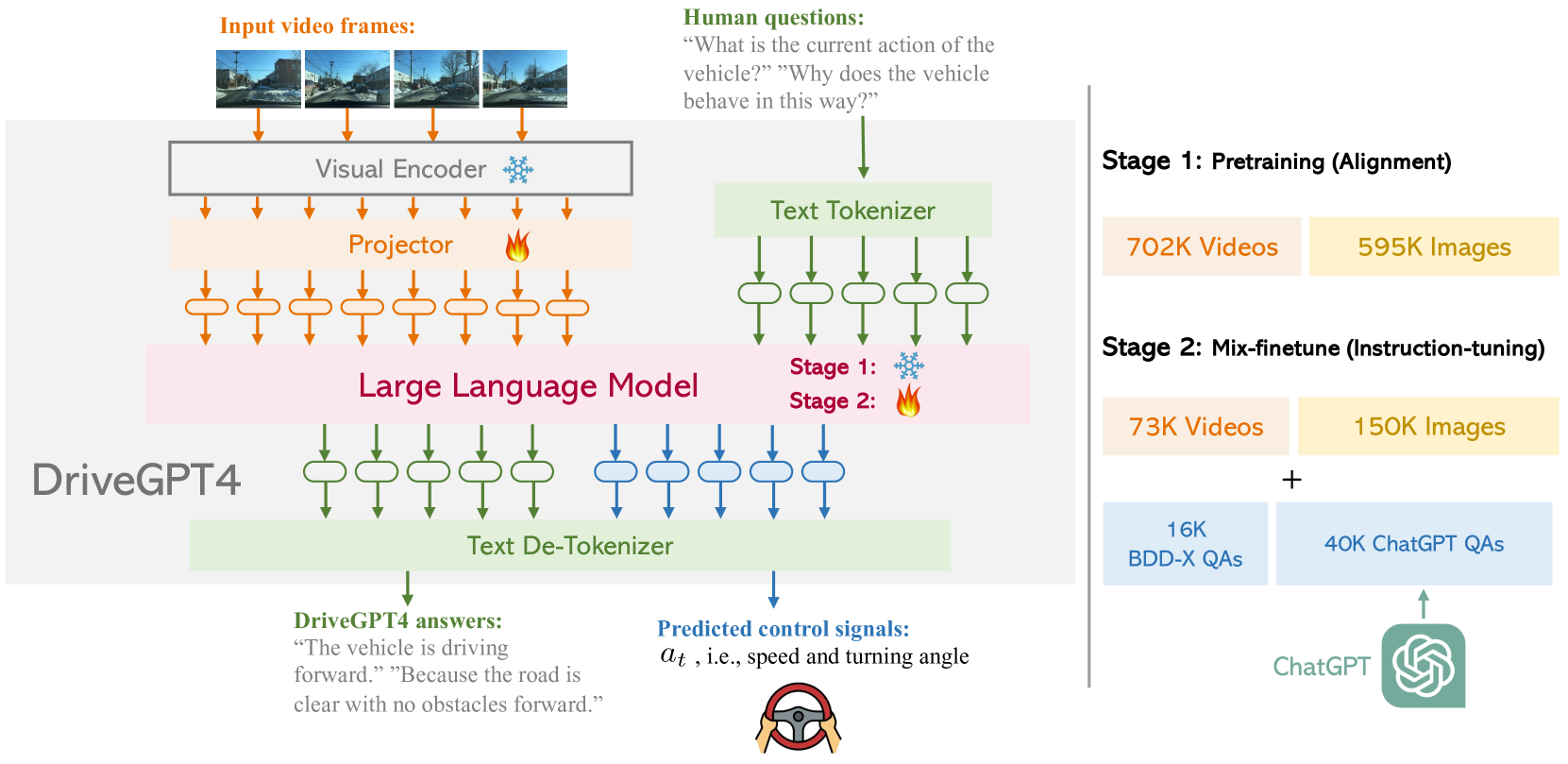
DriveGPT4 integrates a CLIP visual encoder with a LLaMA2 LLM. A pre-trained vision encoder (CLIP ViT-L/14) processes each video frame into visual tokens. These tokens are projected through a learned projector into the embedding space of LLaMA2. In Stage 2 (mix-finetuning), both the LLM and the projector are fully fine-tuned while the vision encoder remains frozen.
The training data is constructed by taking the BDD-X dataset (which contains driving videos with human-written action descriptions and justifications) and using ChatGPT to expand each annotation into multiple instruction-following QA pairs. For example, a single clip might generate questions about what the car is doing, why it is doing it, what objects are visible, and what the driver should do next. This produces a diverse instruction-tuning dataset without additional human annotation.
The model is trained on a mixture of tasks: (1) control prediction (regressing speed and turning angle from visual input), (2) action description (generating text describing the driving action), (3) action justification (explaining why the action is taken), and (4) scene narration (describing the visual scene). All tasks share the same model weights, with the task specified by the instruction prompt. Control signals are predicted as discrete tokens that are decoded into continuous values.
Results
| Metric | DriveGPT4 | ADAPT | Improvement |
|---|---|---|---|
| CIDEr (All) | 99.10 | 85.38 | +13.72 |
| BLEU4 (All) | 18.32 | 17.40 | +0.92 |
| ROUGE-L (All) | 44.73 | 43.04 | +1.69 |
| Speed RMSE (m/s) | 1.30 | 3.02 | -57% |
| Turning Angle RMSE (deg) | 8.98 | 11.98 | -25% |
| Model | CIDEr (Flexible QA) | ChatGPT Score |
|---|---|---|
| DriveGPT4 | 56.34 | 81.62 |
| Valley | 11.37 | 43.23 |
| Video-LLaMA | 5.71 | 27.75 |
- Competitive open-loop control prediction on BDD-X with speed and turning angle RMSE comparable to specialized models
- Fluent, contextually appropriate driving explanations generated alongside control predictions, demonstrating multi-task feasibility
- Multi-task training does not degrade either capability -- joint language+control training maintains performance on both tasks
- Qualitative examples show the model generates coherent scene descriptions and plausible justifications for driving actions
Limitations & Open Questions
- Open-loop evaluation only -- no closed-loop validation means compounding errors and interactive behavior are untested
- Language reasoning can be fluent but non-causal: the model may generate plausible but incorrect explanations that are not grounded in the actual decision process
- Synthetic instruction tuning via ChatGPT can introduce biases and artifacts
- Language is output only (explanations), not input (instructions) -- no instruction-following capability for controlling driving behavior