Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Overview
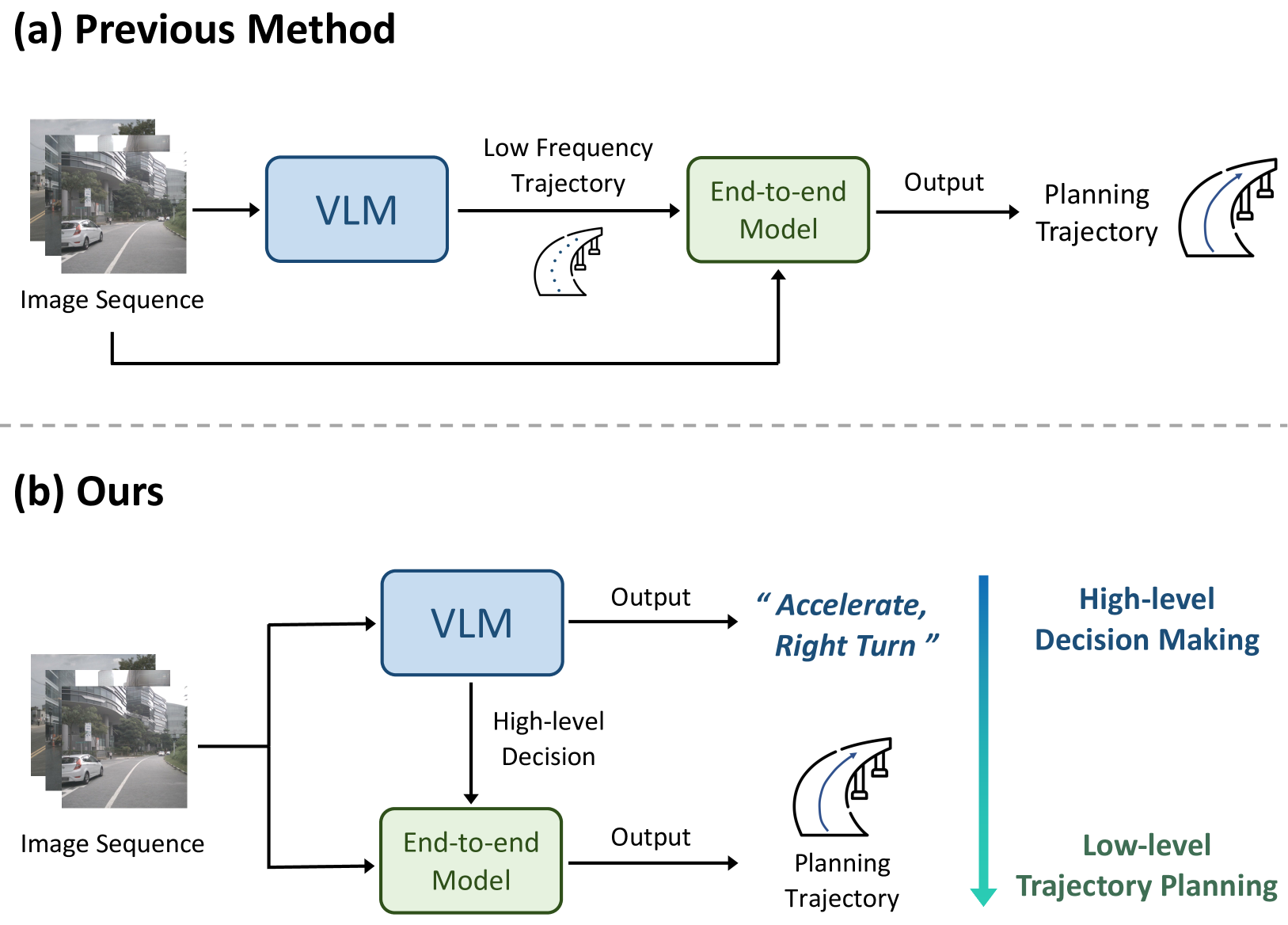
Two dominant paradigms exist in autonomous driving: large vision-language models (LVLMs) with strong reasoning but poor trajectory precision, and end-to-end (E2E) models with precise waypoint prediction but no high-level reasoning capability. Senna bridges these two worlds with a clean architectural insight -- let the LVLM handle "what to do" via natural language while a specialized E2E module handles "how to execute it" with precise waypoints. This decoupled design lets each component operate in its strength zone.
Unlike ORION, which bridges the reasoning-action gap via a dense learned planning token, Senna uses human-readable natural language as the interface between reasoning and planning. The LVLM generates driving decisions like "decelerate and yield to crossing pedestrian, then proceed straight," which condition the E2E trajectory prediction module alongside visual features. This makes the reasoning-to-planning bridge interpretable and debuggable, a significant practical advantage for safety-critical deployment.
The decoupled LVLM+E2E design pattern achieves a 27.12% planning error reduction and 33.33% collision rate reduction over the model without pre-training (pre-trained on DriveX, fine-tuned on nuScenes), demonstrating that domain-specific pre-training and the combined architecture genuinely outperform either component alone. This architecture is shared by NVIDIA's Alpamayo-R1, suggesting it may become the dominant VLA architecture for autonomous driving, where human-readable intermediate representations provide both performance and interpretability benefits.
Key Contributions
- Decoupled LVLM + E2E architecture: LVLM generates natural-language driving decisions, which condition a separate E2E trajectory prediction module alongside visual features, letting each module do what it does best
- Natural language as interpretable bridge: The interface between reasoning and planning is human-readable text, unlike dense embeddings (ORION) or tightly coupled outputs (DriveGPT4), enabling debugging and interpretability
- Large-scale LVLM pre-training on driving data: Pre-training the vision-language component on diverse driving data substantially improves downstream performance, demonstrating the value of domain-specific foundation model preparation
- Significant quantitative improvements: 27.12% planning error (L2) reduction and 33.33% collision rate reduction over the model without pre-training, measured when pre-training on DriveX and fine-tuning on nuScenes
- Best-of-both-worlds validation: First clear demonstration that LVLM-level reasoning combined with E2E-level trajectory precision outperforms either paradigm individually
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Senna-VLM │
│ ┌──────────────┐ ┌───────────────┐ ┌───────────┐ │
│ │ Multi-View │──►│ Vision Encoder │──►│ Driving │ │
│ │ Cameras (6x) │ │ + Adapter │ │ Vision │ │
│ └──────────────┘ └───────────────┘ │ Adapter │ │
│ └─────┬─────┘ │
│ ┌──────────────┐ ┌───────────────┐ │ │
│ │ Surround-View│──►│ Text Encoder │────┐ │ │
│ │ Prompts │ └───────────────┘ ▼ ▼ │
│ └──────────────┘ ┌──────────────────┐ │
│ │ LLM Backbone │ │
│ └────────┬─────────┘ │
└─────────────────────────────────────────┼───────────────┘
│
Meta-Action Text │ "Decelerate, Straight"
(Speed + Path) ▼
┌─────────────────────────────────────────────────────────┐
│ Senna-E2E │
│ ┌────────────┐ ┌────────────┐ ┌──────────────────┐ │
│ │ BEV Feature│ │ Multi-View │ │ Text Encoder │ │
│ │ Transform │ │ Cam Features│ │ (Meta-Action) │ │
│ └─────┬──────┘ └─────┬──────┘ └────────┬─────────┘ │
│ └───────────┬───┘───────────────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Cross-Attention │ │
│ │ Fusion │ │
│ └────────┬────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Trajectory Head │──► Future Waypoints │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────────┘
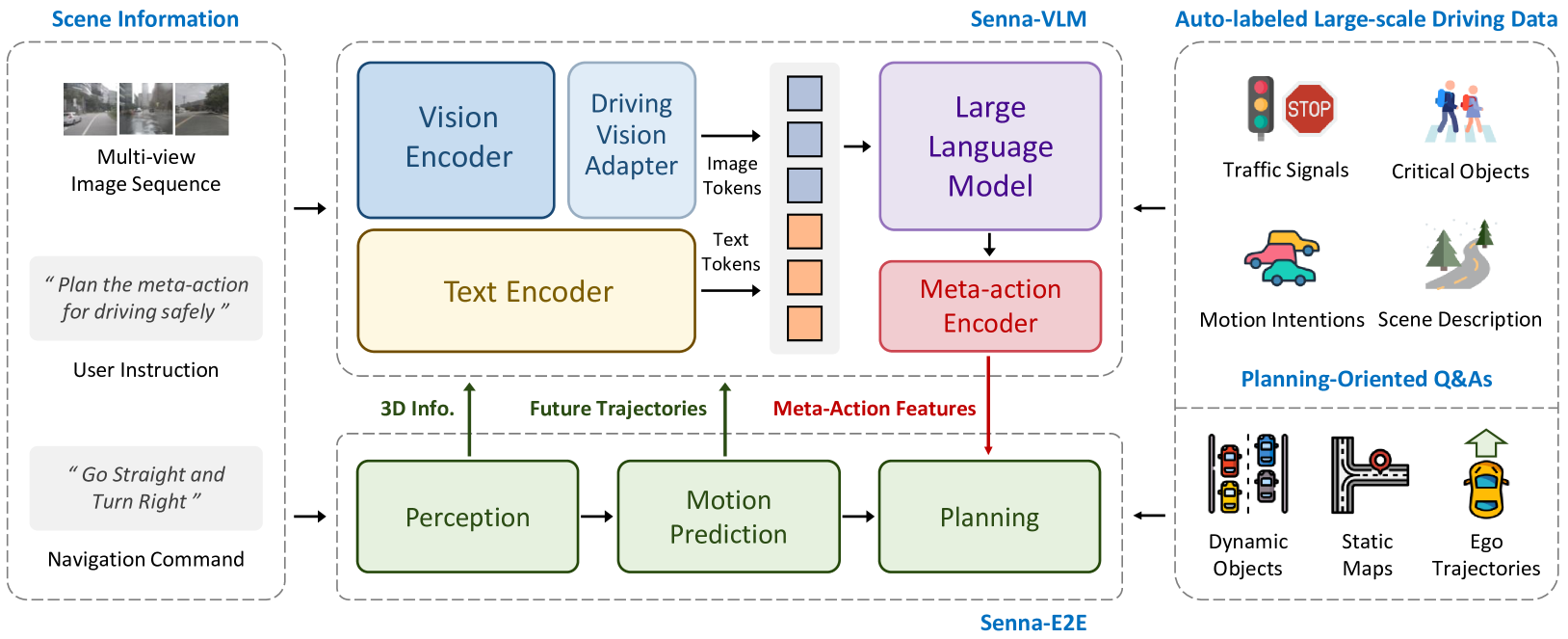
Senna consists of two core components: Senna-VLM (high-level planning in natural language) and Senna-E2E (precise trajectory prediction using meta-actions).
Senna-VLM predicts meta-actions combining speed decisions (Keep, Accelerate, Decelerate, Stop) with path decisions (Straight, Right Turn, Left Turn) in natural language. These are encoded into high-dimensional features and fed into Senna-E2E. Meta-action distribution shows balance across categories: "Keep, Straight" (15.18%), "Keep, Right" (15.95%), "Decelerate, Straight" (15.36%), with less frequent actions like "Accelerate, Right" (3.54%).
Senna-VLM handles surround-view data through a vision encoder processing multi-view sequences, a driving vision adapter compressing image tokens, and surround-view prompts (e.g., <FRONT>, <FRONT LEFT>, <BACK RIGHT>) enabling spatial understanding across camera perspectives. The text encoder processes instructions and prompts.
Six planning-oriented Q&A task categories train the LVLM: (1) driving scene description, (2) traffic signal detection, (3) vulnerable road user identification, (4) motion intention prediction, (5) meta-action planning, and (6) planning explanation.
Three-Stage Training Strategy: - Stage 1 (Mix Pre-training): Vision adapter training with general instruction-following and driving scene data - Stage 2 (Driving Fine-tuning): LVLM fine-tuning on Q&As excluding meta-action planning, focusing on traffic signals, vulnerable users, and motion intentions - Stage 3 (Planning Fine-tuning): LVLM specialization using only meta-action planning Q&As
This progressive approach builds foundational understanding before task specialization.
Senna-E2E receives three types of input: (1) multi-view camera features from a vision encoder, (2) BEV features from a spatial feature transformation, and (3) the natural-language driving decision from Senna-VLM, encoded via a text encoder. These features are fused through cross-attention mechanisms, and the trajectory prediction head outputs future waypoints.
At training time, both modules are optimized jointly: the LVLM with language supervision on driving decisions, and the E2E module with L2 trajectory loss and collision penalties. At inference time, the LVLM first generates the driving decision text, which is then fed to the E2E module along with visual features to produce the final trajectory.
Results

- 27.12% planning error reduction (L2) and 33.33% collision rate reduction over the model without pre-training (with DriveX pre-training + nuScenes fine-tuning), demonstrating that domain-specific pre-training and the decoupled architecture improve both precision and safety
- LVLM-level reasoning quality alongside E2E model-level trajectory accuracy, validating the best-of-both-worlds claim
- Pre-training the LVLM component on driving data substantially improves performance, as demonstrated by the cross-scenario transfer gains from DriveX pre-training
- Decoupled design outperforms tightly coupled approaches where a single model must handle both reasoning and precise coordinate generation
- Ablation studies confirm both modules are necessary: removing the LVLM decisions degrades to baseline E2E performance, removing the E2E module degrades trajectory precision
- Multi-image input significantly improved performance versus front-view only; three-stage training yielded best results among training ablations
- Cross-scenario generalization: Pre-training on the large-scale DriveX dataset and fine-tuning on nuScenes demonstrates strong cross-scenario transfer
- Inference speed remained comparable despite multi-image complexity, and the system provides detailed planning explanations highlighting reasoning about traffic lights, pedestrians, and environmental elements
Limitations & Open Questions
- Natural language bottleneck: text may lose information compared to dense embeddings, potentially limiting the expressiveness of the reasoning-to-planning interface for complex maneuvers
- Sequential LVLM-then-E2E inference adds latency compared to single-model approaches, which may be problematic for real-time safety-critical applications
- Language decision errors propagate to the trajectory module without recovery -- no error correction or feedback mechanism between the two stages
- Pre-training data requirements are substantial, limiting accessibility for smaller research groups without large-scale driving data collection infrastructure
Connections
- Autonomous Driving
- Vision Language Action
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model
- Gpt Driver Learning To Drive With Gpt
- Alpamayo R1 Bridging Reasoning And Action Prediction For Autonomous Driving
- Alphadrive Unleashing The Power Of Vlms In Autonomous Driving
- Emma End To End Multimodal Model For Autonomous Driving