EMMA: End-to-End Multimodal Model for Autonomous Driving
Overview
EMMA is Waymo's industry-scale demonstration of the "everything as language tokens" paradigm for autonomous driving. A single large multimodal foundation model unifies planning, perception, and road graph understanding through a prompt-driven interface where all inputs and outputs are represented as natural language. Rather than requiring separate modules for detection, tracking, prediction, mapping, and planning, EMMA handles all tasks through different text prompts to the same model, with task-specific outputs generated as token sequences.
The paper represents the most extreme version of the unified language-space approach to autonomous driving. Where previous work like GPT-Driver showed that trajectories could be represented as language tokens, EMMA extends this to the entire driving stack: 3D object detections, road graph structure, and planning trajectories are all generated as natural language. Navigation instructions ("turn right in 200m") and ego vehicle state ("speed: 30km/h, heading: 45deg") are provided as text context alongside camera images, creating a fully text-mediated interface between the driving system and its inputs/outputs.
Coming from Waymo -- the leading autonomous vehicle company with real-world deployment experience -- EMMA carries significant industry credibility. The key conceptual contribution is demonstrating that cross-task knowledge sharing through a unified language representation can benefit all driving tasks simultaneously: training on perception data improves planning, and vice versa. This challenges the conventional wisdom that specialized architectures are needed for each driving subtask.
Key Contributions
- Unified prompt-driven multi-task architecture: Single multimodal foundation model handles planning, perception, and road graph understanding through different text prompts, without task-specific architectural changes
- Everything-as-language representation: Planning trajectories, perception objects, and road graph elements are all represented as natural language tokens, enabling cross-task knowledge sharing
- Non-sensor inputs as text: Navigation instructions and ego status are provided as text context alongside camera images, creating a natural language interface for all driving information
- Cross-task knowledge transfer: Unified training on multiple tasks improves individual task performance compared to task-specific models, demonstrating positive transfer across the driving stack
- Industry-scale validation: Large-scale pretrained multimodal foundation model fine-tuned on Waymo's extensive driving data
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ EMMA Architecture │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌──────────────────────┐ │
│ │ Surround │ │ Ego State │ │ Navigation Cmd │ │
│ │ Camera Imgs │ │ (vel,heading│ │ "turn right in 200m" │ │
│ └──────┬──────┘ │ pos) │ └──────────┬───────────┘ │
│ │ └──────┬──────┘ │ │
│ ▼ │ │ │
│ ┌─────────────┐ │ │ │
│ │ Vision │ │ │ │
│ │ Encoder │ │ │ │
│ └──────┬──────┘ │ │ │
│ │ visual tokens │ text tokens │ text tokens │
│ └────────────────┼────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Gemini Transformer Decoder │ │
│ │ (pretrained, fine-tuned on driving) │ │
│ └──────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │ Planning │ │ Perception │ │ Road Graph │ │
│ │ (x,y) wpts│ │ 3D BBoxes │ │ Polylines │ │
│ │ as text │ │ as text │ │ as text │ │
│ └────────────┘ └────────────┘ └────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Chain-of-Thought (for planning) │ │
│ │ R1: Scene description (weather, road) │ │
│ │ R2: Critical objects (3D coords) │ │
│ │ R3: Object behavior description │ │
│ │ R4: Meta driving decision ──► trajectory waypoints │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
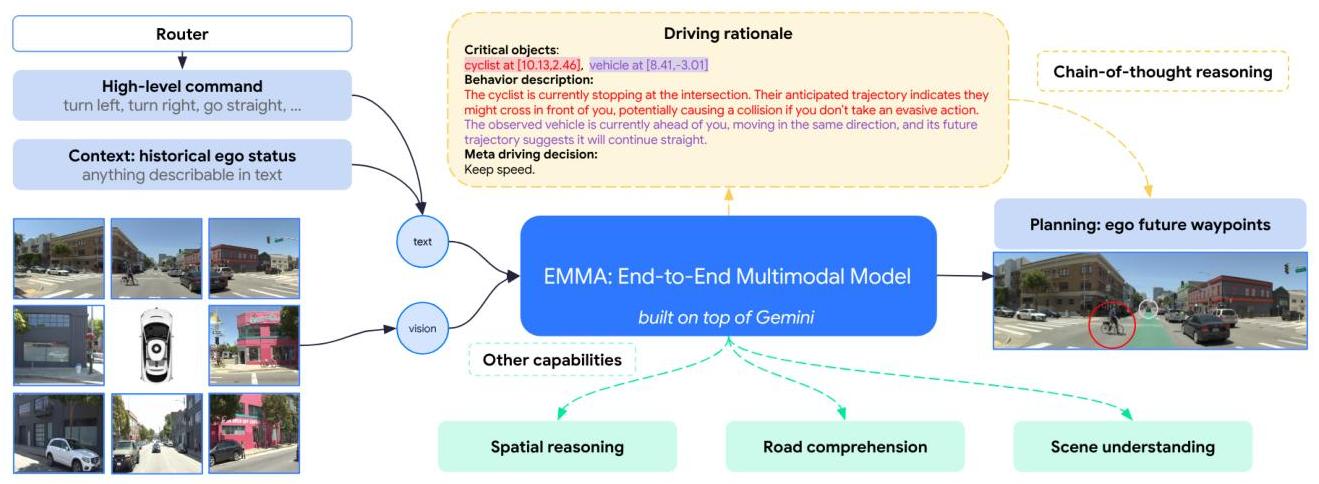
EMMA is built on top of a large pretrained multimodal foundation model (Gemini family). The model takes as input a set of camera images from the vehicle's sensor suite, along with text prompts that specify both the task and contextual information. The architecture follows the standard vision-language model pattern: images are encoded by a vision encoder into visual tokens, which are concatenated with text tokens and processed by a large transformer decoder.
For planning, the prompt includes the ego vehicle's current state (position, velocity, heading), navigation instructions (route commands), and optionally scene descriptions. The model generates trajectory waypoints as a sequence of (x, y) coordinate pairs expressed in text. For perception, the prompt requests object detection, and the model generates 3D bounding boxes as text tokens specifying center coordinates, dimensions, heading, and class label. For road graph understanding, the prompt requests lane structure, and the model generates polylines representing lane boundaries and centerlines.
The key architectural decision is the absence of task-specific heads or decoders. All tasks share the same model weights and the same autoregressive generation mechanism. Task selection happens purely through the input prompt, and the model learns to generate the appropriate output format for each task. Multi-task training is performed by sampling from all task datasets with appropriate mixing ratios.
The coordinate representation uses a discretized token vocabulary for numeric values, converting continuous coordinates into discrete tokens. This introduces quantization error but enables the use of standard language model training and inference infrastructure without modification.
EMMA incorporates chain-of-thought reasoning by generating structured rationales before planning decisions in a hierarchical structure: R1 (scene description -- weather, time, road conditions), R2 (critical objects with 3D coordinates), R3 (behavior description of critical objects), and R4 (meta driving decision). These rationales are generated automatically using existing perception/prediction models and designed prompts, ensuring scalability without manual annotation.
For 3D object detection, the model generates text-encoded 7D bounding boxes (x, y, z, l, w, h, theta, class) sorted by depth. For road graph estimation, critical design innovations include dynamic sampling (waypoints per polyline adjusted by curvature and length), ego-origin alignment, shuffled ordering with padding within distance bins, and semantic punctuation using language-like structures (e.g., "(x,y and x,y);...") to leverage Gemini's pre-trained language understanding. Multi-task training samples batches from all datasets with probability proportional to dataset size.
Results
Key Performance Summary
| Task / Metric | EMMA Result | Improvement |
|---|---|---|
| nuScenes Avg L2 (vs self-supervised) | SOTA | 17.1% improvement |
| nuScenes Avg L2 (vs supervised) | SOTA | 12.1% improvement |
| WOMD 5-sec horizon (EMMA+ w/ CoT) | SOTA | 13.5% over baselines |
| 3D Detection: Vehicle Precision vs BEVFormer | +16.3% relative | 5.5% recall gain at same precision |
| Multi-task vs Single-task | Up to +5.5% | Positive cross-task transfer |
| CoT Integration | +6.7% overall | Meta-decision: 3.0%, Critical object ID: 1.5% |
- WOMD planning: EMMA+ with chain-of-thought reasoning surpasses existing baselines by 13.5% at the 5-second prediction horizon, using only camera inputs and ego vehicle history while many baselines incorporate LiDAR, agent histories, and detailed road graphs
- nuScenes planning: Outperforms previous self-supervised methods by 17.1% in average L2 metric and supervised methods by 12.1%, using only camera inputs and ego vehicle history
- Chain-of-thought benefits: CoT integration provides a 6.7% performance gain overall; "driving meta-decision" contributes most (3.0%), "critical object identification" contributes 1.5%, and "scene description" primarily enhances explainability
- 3D object detection: 16.3% relative increase in vehicle precision at equivalent recall levels over BEVFormer on Waymo Open Dataset
- Road graph estimation: Dynamic polyline sampling and ego-origin alignment prove critical (40-90% quality differences in ablations), semantic punctuation improves performance by up to 10%
- Multi-task generalist benefits: Co-training yields up to 5.5% improvement over single-task variants, demonstrating positive cross-task transfer
- Data scaling: Performance continues to improve with dataset size and has not saturated even with 24 million scenarios on Waymo's internal dataset
- Joint multi-task capability: a single model achieves competitive performance on planning, perception, and road graph understanding simultaneously, matching or approaching task-specific baselines
- The language interface enables flexible task specification and natural integration of contextual information (navigation instructions, traffic rules) that would be difficult to encode in fixed-format inputs
Limitations & Open Questions
- Limited number of image frames processable -- cannot handle long temporal sequences needed for some driving scenarios, and temporal reasoning is constrained by context window size
- Camera-only with no LiDAR or radar, missing depth and velocity sensor redundancy important for safety-critical applications; camera-primary approach may need multi-modal sensor fusion for optimal 3D spatial reasoning
- Language representation of precise coordinates may lose fidelity compared to dedicated numeric heads -- the quantization introduced by tokenization creates a precision ceiling that may matter for safety-critical trajectory generation
- Computational requirements remain significant for real-time deployment; mitigation strategies like model distillation are suggested but not validated
- Ensuring consistency between generated CoT explanations and actual driving decisions remains an open challenge
Connections
- Autonomous Driving
- Vision Language Action
- Foundation Models
- Gpt Driver Learning To Drive With Gpt
- Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Attention Is All You Need
- Drivelm Driving With Graph Visual Question Answering