Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
Citation
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Marco Pavone + 37 co-authors (NVIDIA), arXiv, 2025.
Overview
Alpamayo-R1 is NVIDIA's production-grade Vision-Language-Action (VLA) model for autonomous driving that combines VLM reasoning with trajectory generation at 99ms end-to-end latency. The system is trained on a causally-grounded dataset targeting long-tail scenarios and has been validated on real-world roads, representing a significant step from academic VLA prototypes toward deployable autonomous driving systems.
The key innovation is the causally-grounded dataset, built with hybrid labeling that explains why certain actions are correct, not just what actions to take. This addresses a fundamental weakness of standard imitation learning datasets where the model learns to mimic expert trajectories without understanding the reasoning behind them. The multi-stage training pipeline (VLM pre-training, supervised trajectory learning, then RL-based safety refinement) produces a model that reasons about driving scenarios before generating trajectories.
Alpamayo-R1 achieves real-time inference well under the ~150ms threshold for safe highway driving, has been tested on actual roads, and targets the long-tail scenarios that matter most for safety. With open weights on HuggingFace and 41+ authors at NVIDIA scale, it bridges the gap between research VLAs and deployable autonomous driving systems, following the decoupled VLM + trajectory architecture pattern established by ORION and Senna.
Key Contributions
- Real-time VLA at 99ms latency: Production-viable inference speed for a full VLM reasoning + trajectory generation pipeline on an NVIDIA RTX 6000 Pro Blackwell platform
- Causally-grounded dataset via hybrid labeling: Training data built with combined human annotation and automated methods that explicitly labels why actions are correct (causal reasoning chains), not just the actions themselves, with focus on long-tail scenarios
- Multi-stage training pipeline: Stage 1 (VLM pre-training on driving data), Stage 2 (supervised learning on expert trajectories), Stage 3 (reinforcement learning for safety refinement)
- Modular VLM + trajectory generation architecture: Separates reasoning from trajectory prediction, following the pattern established by ORION and Senna
- Real-world road testing: Validated beyond simulation on actual vehicles, a critical deployment milestone
- Open weights and code on HuggingFace and GitHub for reproducibility
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ Alpamayo-R1 Architecture │
├──────────────────────────────────────────────────────────────────┤
│ │
│ Multi-Camera Egomotion Text │
│ Images History Input │
│ │ │ │ │
│ ▼ │ │ │
│ ┌────────────────┐ │ │ │
│ │ Vision Encoder │ │ │ │
│ │ (triplane 3D │ │ │ │
│ │ tokenization) │ │ │ │
│ │ 3.6x-20x │ │ │ │
│ │ compression │ │ │ │
│ └───────┬────────┘ │ │ │
│ └─────┬────┘────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Cosmos-Reason VLM Backbone │ │
│ │ (pretrained on 3.7M VQA + 24.7K driving) │ │
│ │ │ │
│ │ Autoregressive generation: │ │
│ │ CoT Reasoning ──► Meta-Actions ──► Traj Tokens │ │
│ └───────────────────────────────────┬──────────────┘ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Diffusion Trajectory │ │
│ │ Decoder │ │
│ │ (discrete ──► continuous) │ │
│ └──────────────┬───────────┘ │
│ ▼ │
│ Continuous Waypoints │
├──────────────────────────────────────────────────────────────────┤
│ Training: Stage 1 (Action Injection) ──► Stage 2 (SFT on CoC) │
│ ──► Stage 3 (GRPO RL with multi-signal rewards) │
└──────────────────────────────────────────────────────────────────┘
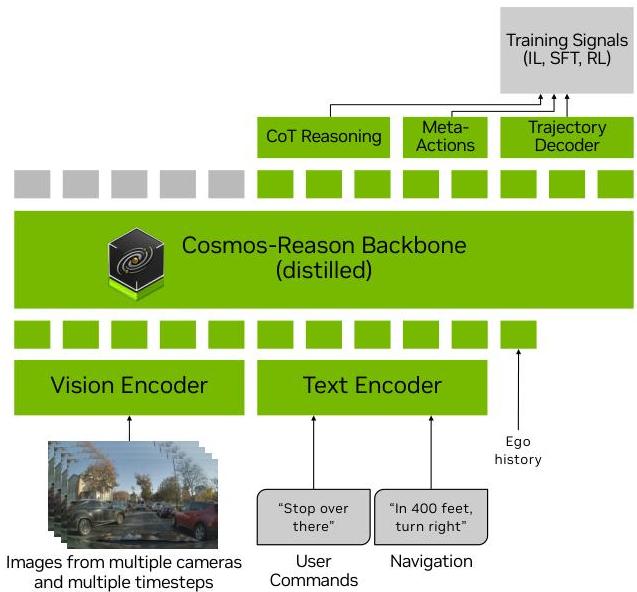
Alpamayo-R1 employs a modular architecture processing multi-camera, multi-timestep observations with egomotion history and optional textual inputs. The system tokenizes inputs into a unified sequence fed into the Cosmos-Reason VLM backbone, which autoregressively generates Chain-of-Thought reasoning, meta-actions, and discrete trajectory tokens. The Cosmos-Reason backbone was pre-trained on 3.7 million VQA samples including 24,700 driving-specific video samples, providing general physical common sense and embodied reasoning capabilities.
A diffusion-based trajectory decoder converts discrete trajectory tokens into continuous, kinematically feasible waypoints. This dual representation -- discrete tokens during training, continuous trajectories during inference -- ensures unified autoregressive training with computational efficiency. For handling high token counts from multi-camera inputs, efficient vision encoding strategies include Multi-Camera Tokenization using triplanes as 3D inductive bias and Multi-Camera Video Tokenization for temporal compression, achieving 3.6x to 20x token compression while preserving semantic information.
The core dataset contribution is the structured Chain of Causation (CoC) dataset, providing causally grounded reasoning traces directly linking observed evidence to driving decisions. The CoC framework defines a closed set of high-level driving decisions (e.g., "Lead obstacle following," "Lane change") and an open-ended set of critical components (causal factors). The curation process involves clip selection (scenarios with explicit driving decisions), keyframe labeling (precise decision-making moments), and hybrid labeling combining human annotation with VLM-based automation. Quality assurance evaluates causal coverage, correctness, proximate cause, and decision minimality, with human verification confirming a 132.8% improvement in causal relationship scores over free-form reasoning approaches.
Three-stage training pipeline: - Stage 1 (Action Modality Injection): VLM learns to predict discrete trajectory tokens via cross-entropy loss; a separate action-expert uses conditional flow matching to map tokens to continuous control - Stage 2 (SFT): Model learns causally grounded reasoning traces alongside trajectory predictions using the CoC dataset - Stage 3 (RL Post-Training): GRPO with a comprehensive reward signal combining reasoning quality reward (evaluated by large reasoning models as critics), CoC-action consistency reward (alignment between reasoning and predicted actions), and low-level trajectory quality reward (imitation learning, collision penalties, comfort constraints)
Results
| Metric | Alpamayo-R1 | Baseline | Improvement |
|---|---|---|---|
| minADE_6 (nominal) | 0.794m | 0.837m | 4.8% |
| minADE_6 (challenging) | 0.868m | 0.994m | 12% |
| Close encounter rate | 11% | 17% | 35% reduction |
| AlpaSim score | 0.50 | 0.38 | +32% |
| Reasoning quality | 4.5 | 3.1 | +45% |
| Reasoning-action consistency | 0.85 | 0.62 | +37% |
| Metric | AR1-10B | AR1-0.5B | Improvement |
|---|---|---|---|
| minADE_6 | 0.849m | 0.913m | 7.0% |
| At-fault close encounters | 4% | 9% | 55% reduction |
| AlpaSim score | 0.72 | 0.35 | 2x |
- Open-loop trajectory prediction: 4.8% improvement in minADE_6 on nominal scenarios (0.794m vs 0.837m); 12% improvement on challenging scenarios (0.868m vs 0.994m)
- Closed-loop simulation (AlpaSim): 35% reduction in close encounter rate (11% vs 17%); overall AlpaSim score improvement from 0.38 to 0.50
- 10B parameter model (AR1-10B): 7.0% improvement in minADE_6 (0.849m vs 0.913m); 55% reduction in at-fault close encounter rate (4% vs 9%); over 2x improvement in AlpaSim score (0.72 vs 0.35)
- RL post-training benefits: 45% improvement in reasoning quality scores (3.1 to 4.5); 37% increase in reasoning-action consistency (0.62 to 0.85); 9.4% reduction in trajectory prediction error
- 99ms inference latency on NVIDIA RTX 6000 Pro Blackwell platform, production-viable for real-time deployment
- Real-world road testing completed in urban environments, navigating complex scenarios without human intervention
- Long-tail scenario handling through the CoC dataset specifically designed for rare safety-critical events
- Open weights: NVIDIA released Alpamayo-R1-10B model weights and inference code for reproducible benchmarking
Limitations & Open Questions
- Full architecture details pending final publication beyond arXiv
- Real-world testing scope and conditions not fully disclosed
- Long-tail dataset construction methodology may not generalize to all driving domains and geographies
- Reinforcement learning stage adds significant training complexity and cost
Connections
- Autonomous Driving
- Vision Language Action
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment
- Emma End To End Multimodal Model For Autonomous Driving
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving