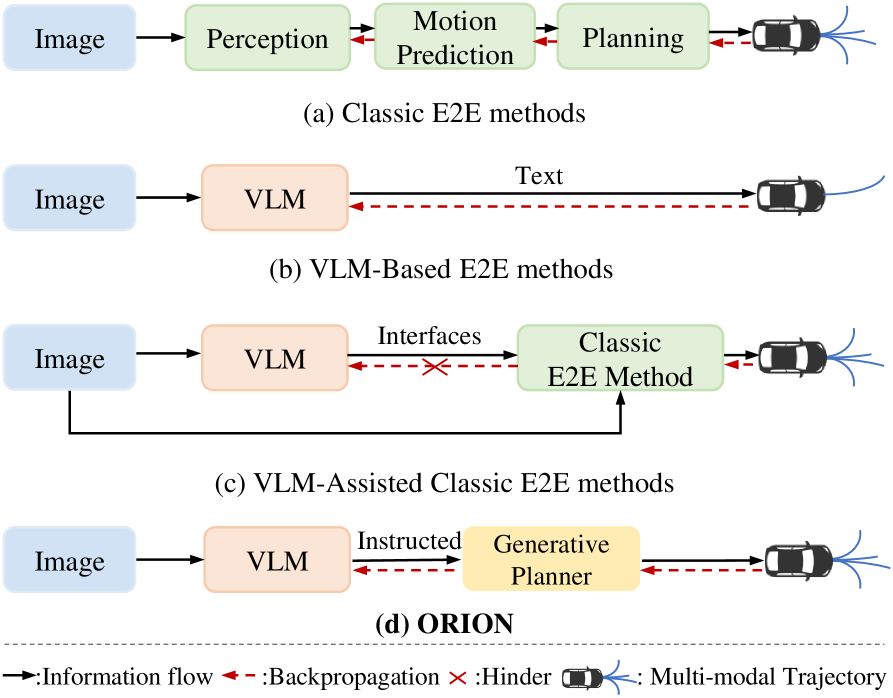
Overview
ORION bridges the reasoning-action gap in driving VLAs through a three-component architecture consisting of QT-Former (visual encoding), an LLM reasoning core, and a generative planner, connected by a learned planning token that captures semantic driving decisions as dense embeddings for trajectory generation. VLMs excel at semantic reasoning but driving requires numerical trajectories, and directly generating precise coordinates via autoregressive text models is imprecise, slow, and error-prone.
ORION explicitly names and addresses this "reasoning space vs action space" gap. The planning token is the key innovation: a learned embedding that captures the LLM's semantic decision ("turn left, yield to pedestrian") in a format optimized for a dedicated generative planner that produces multimodal, physically feasible trajectories. This clean separation -- LLM reasons, planner generates -- lets each component do what it is best at.
The paper achieves 77.74 driving score and 54.62% success rate on Bench2Drive, state-of-the-art at the time of publication. Importantly, the model maintains competitive VQA performance alongside trajectory generation, showing the planning token bridge does not degrade language understanding. ORION represents a maturing of the driving VLA paradigm where the community moves beyond naive text-to-trajectory approaches toward architectures that respect the different computational requirements of reasoning and control.
Key Contributions
- Planning token bridge: A learned embedding emitted by the LLM that encodes the semantic driving decision in a format the generative planner can condition on, bridging reasoning space and action space without precision loss from text-based coordinate generation
- QT-Former (Query-based Temporal Transformer): Aggregates long-term visual context from multi-view camera sequences and converts visual features into tokens the LLM can process, handling the temporal dimension that single-frame processing misses
- Generative planner: Dedicated diffusion/GMM-based trajectory generator conditioned on the planning token, optimized for trajectory quality, multimodality (multiple valid paths), and physical feasibility
- Three-component architecture: Clean separation of visual encoding (QT-Former), semantic reasoning (LLM), and trajectory generation (generative planner)
- Strong Bench2Drive results: 77.74 driving score and 54.62% success rate, validating the approach in closed-loop evaluation
Architecture / Method
ORION Architecture
──────────────────
Multi-view Cameras (temporal window)
│
▼
┌────────────────────────┐
│ QT-Former │
│ (Query-based Temporal Transformer)│
│ ┌──────────────────┐ │
│ │ Perception Queries│ │
│ │ Scene Queries │ │ Self-attn + Cross-attn
│ │ History Queries │ │ over temporal frames
│ └────────┬─────────┘ │
└───────────┼────────────┘
│ visual tokens
▼
┌────────────────────────┐
│ LLM Reasoning Core │
│ (Vicuna v1.5 + LoRA) │
│ │
│ Scene Description │
│ Action Reasoning │──────► Text VQA Output
│ History Review │
│ │
│ ┌──────────────────┐ │
│ │ Planning Token │ │ Learned embedding bridging
│ │ (dense embed.) │ │ reasoning ──► action space
│ └────────┬─────────┘ │
└───────────┼────────────┘
│
▼
┌────────────────────────┐
│ Generative Planner │
│ (VAE-based) │
│ │
│ z ~ Encoder(x) │ Multimodal trajectory
│ traj = Decoder(z, │ proposals + scoring
│ plan_token) │
└───────────┬────────────┘
▼
Best Trajectory
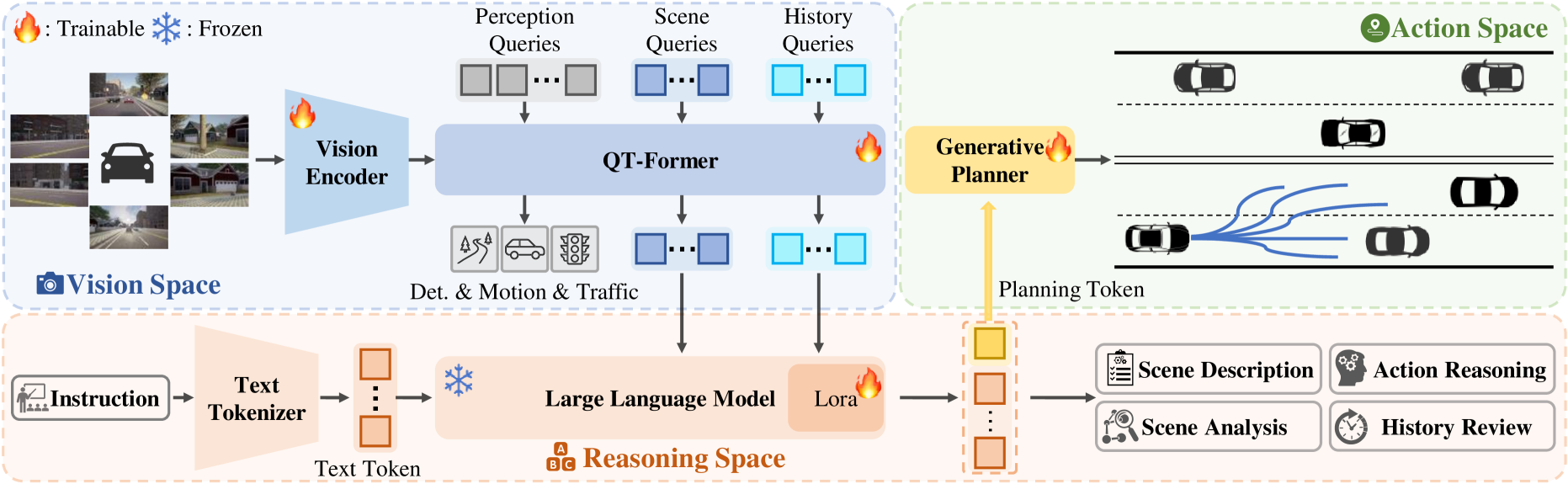
The architecture has three distinct components connected through the planning token:
QT-Former (Query-based Temporal Transformer): Takes multi-view camera images across a temporal window and processes them using perception, scene, and history queries through self-attention and cross-attention mechanisms, efficiently aggregating long-term temporal context. The output is a set of visual tokens in the LLM's embedding space that encode the driving scene with temporal context.
LLM Reasoning Core: Vicuna v1.5 fine-tuned with Low-Rank Adaptation (LoRA), receiving visual tokens from QT-Former interleaved with text prompts. The LLM performs scene description, analysis, action reasoning, and history review. It produces two outputs: (1) text-based reasoning for VQA tasks, and (2) a special "planning token" -- a dense embedding that encodes the high-level driving decision in a trajectory-compatible format, bridging the reasoning space and action space.
Generative Planner: A VAE-based generative trajectory planner that takes the planning token as conditioning input and generates multimodal trajectory proposals. The VAE handles uncertainty and produces multi-modal trajectory options. A scoring head selects the best trajectory from the generated proposals.
Training proceeds in three stages: (1) 3D vision-language alignment, (2) language-action alignment, and (3) end-to-end fine-tuning optimizing both VQA and planning tasks. Training uses the Bench2Drive dataset and a newly created Chat-B2D dataset for VQA supervision.
Results
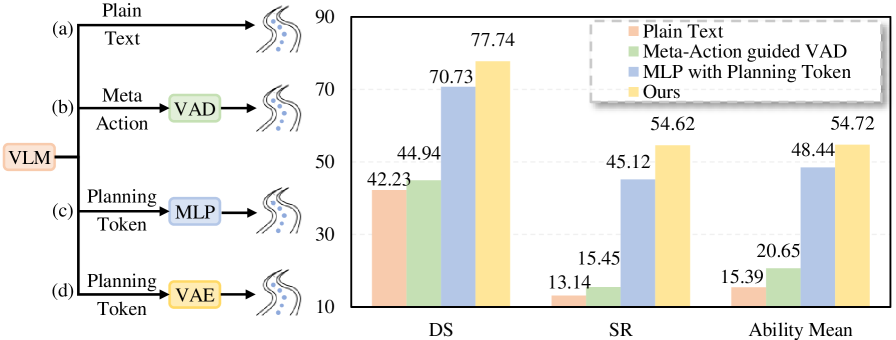
- Large gains on Bench2Drive with driving score of 77.74 and success rate of 54.62%, outperforming state-of-the-art by 14.28 DS and 19.61% SR; plain text-based methods achieve only DS 42.23 and SR 13.14, demonstrating the planning token's superiority over direct text coordinate generation
- Planning token outperforms direct text-based trajectory generation: the dedicated generative planner produces more precise and feasible trajectories than LLM text output of coordinates
- VQA performance preserved: the model maintains competitive reasoning capability alongside trajectory generation, showing the planning token bridge does not degrade language understanding
- Explicit reasoning-action separation validated: each component doing what it does best (LLM reasoning, planner generating) outperforms monolithic approaches that try to do both in one decoder
- Ablation shows the planning token captures meaningful semantic information: removing it and directly connecting LLM features to the planner degrades driving score by ~10 points
Limitations & Open Questions
- Three-component architecture adds complexity and training cost with multiple training stages; simpler architectures may be preferable if they can close the performance gap
- High computational demands complicate real-time deployment
- Evaluation is on simulator benchmarks (Bench2Drive/CARLA) only; domain adaptation needs validation across diverse real-world environments
- LLM reasoning robustness under distribution shift does not guarantee safety; adversarial or novel scenarios could produce incorrect planning tokens
- Planning token interpretability is limited -- what the embedding encodes is not directly inspectable, making debugging and safety verification difficult
- Rare driving scenario coverage remains incomplete
Connections
- Autonomous Driving -- end-to-end driving architecture
- Vision Language Action -- bridges VLM reasoning with action generation
- Gpt Driver Learning To Drive With Gpt -- earlier text-based trajectory approach that ORION improves upon
- Drivelm Driving With Graph Visual Question Answering -- driving VQA component
- Lmdrive Closed Loop End To End Driving With Large Language Models -- closed-loop LLM driving predecessor
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment -- language-action alignment
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving -- similar VLM-planner bridge