DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
Overview
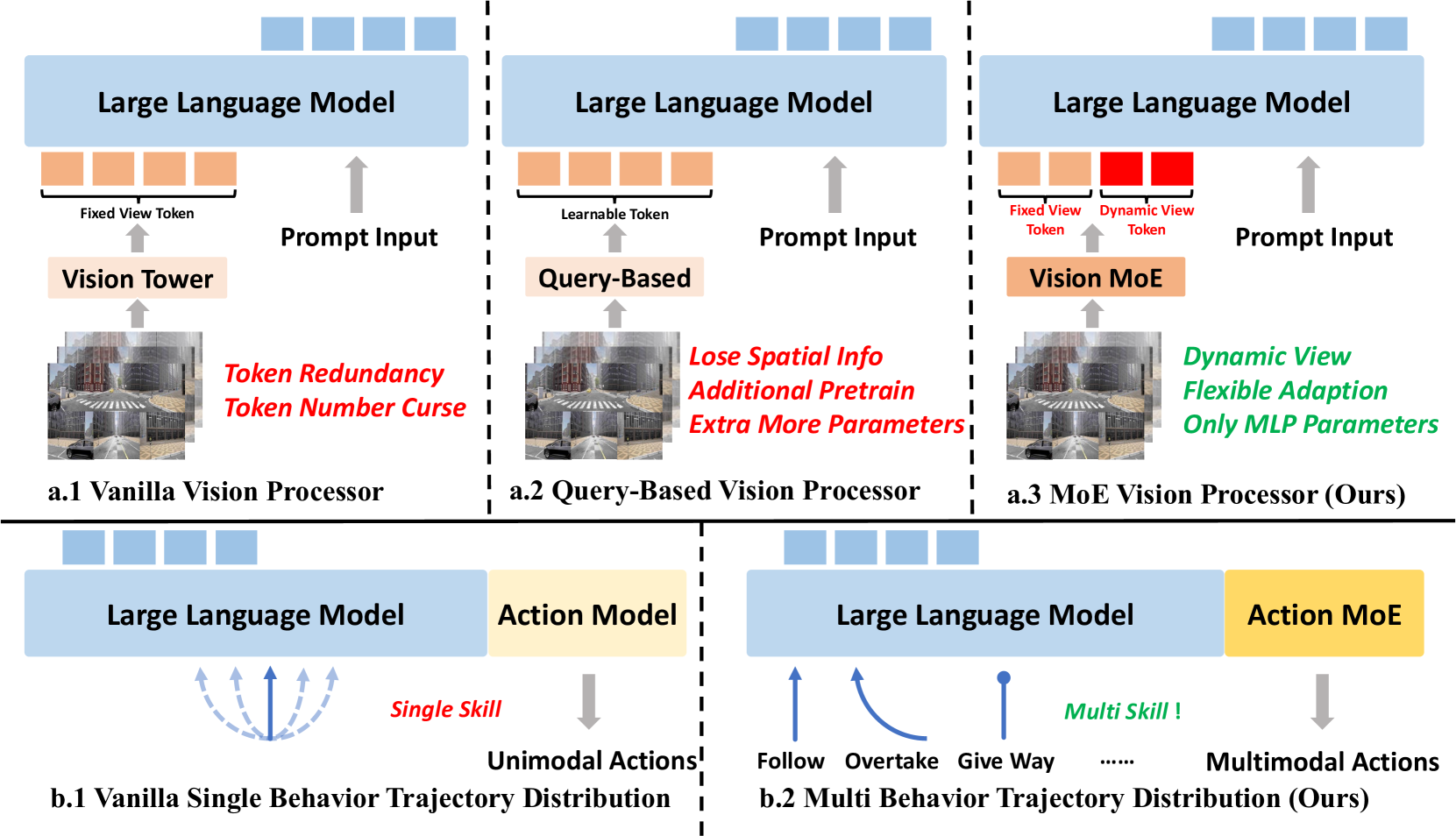
DriveMoE introduces a dual-level Mixture-of-Experts (MoE) architecture to driving Vision-Language-Action models. The key innovation is applying expert specialization at two distinct levels: a Scene-Specialized Vision MoE that dynamically selects which cameras to process based on the driving context, and a Skill-Specialized Action MoE that activates different expert modules for different driving behaviors. This addresses the mode averaging problem -- the tendency of monolithic models to produce compromised outputs when trained on diverse driving scenarios.
Monolithic driving VLA models use the same parameters for all scenarios, leading to averaged behaviors that fail to excel at any specific driving skill. Highway cruising, intersection navigation, parking, and emergency braking require fundamentally different capabilities in terms of which visual information matters and what action patterns are appropriate. DriveMoE addresses this by allowing the model to dynamically specialize both its perception (which cameras to attend to) and its action generation (which behavioral expert to activate) based on the current driving context.
Built on the Drive-pi-0 VLA baseline, DriveMoE represents the first application of MoE to driving VLA models. It achieves state-of-the-art performance on the Bench2Drive closed-loop driving benchmark while simultaneously improving computational efficiency through selective camera processing, demonstrating that the MoE scaling pattern from large language models transfers effectively to embodied driving agents.
Key Contributions
- Scene-Specialized Vision MoE: Learned router examines driving context and selects which cameras to process -- highway scenarios use front/side cameras while parking uses all cameras, reducing unnecessary computation
- Skill-Specialized Action MoE: Separate expert modules for different driving behaviors (highway cruising, intersection navigation, parking, etc.) with a learned router that activates the appropriate expert based on scene understanding
- Dual-level MoE (vision + action): Novel two-level expert routing that addresses the mode averaging problem at both the perception and planning stages simultaneously
- Built on Drive-pi-0 baseline: Extends an existing VLA architecture with MoE, demonstrating the general applicability of the MoE scaling pattern to driving
- Bench2Drive SOTA: State-of-the-art on the standard closed-loop driving benchmark
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ DriveMoE: Dual-Level MoE Architecture │
│ │
│ Multi-Camera Input │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │Front│ │FL │ │FR │ │Back │ │BL │ │BR │ │
│ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ │
│ └───────┼───────┼───────┼───────┼───────┘ │
│ ▼ ▼ ▼ ▼ │
│ ┌────────────────────────────────────────────┐ │
│ │ Scene-Specialized Vision MoE │ │
│ │ ┌────────────────┐ │ │
│ │ │ Camera Router │ (context + goal + state)│ │
│ │ │ ──► Top-K view │ selection (hard routing) │ │
│ │ └───────┬────────┘ │ │
│ │ ▼ │ │
│ │ Process only selected cameras │ │
│ │ (e.g., highway: front+side only) │ │
│ └──────────────────┬─────────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────────────┐ │
│ │ VLA Backbone (Drive-pi-0) │ │
│ │ Vision Encoder + Language Model Backbone │ │
│ └──────────────────┬─────────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────────────┐ │
│ │ Skill-Specialized Action MoE │ │
│ │ ┌────────────────┐ │ │
│ │ │ Action Router │ (scene understanding) │ │
│ │ └───────┬────────┘ │ │
│ │ ▼ │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ ┌──────┐ │ │
│ │ │Merging │ │Give-way│ │Overtake│ │General│ │ │
│ │ │Expert │ │Expert │ │Expert │ │Expert │ │ │
│ │ └───┬────┘ └───┬────┘ └───┬────┘ └──┬───┘ │ │
│ │ └──────────┼─────────┘ │ │ │
│ │ ▼ (weighted combine) │ │ │
│ └──────────────────┬─────────────────────────┘ │
│ ▼ │
│ Trajectory Waypoints │
└──────────────────────────────────────────────────────────────┘
DriveMoE builds on the Drive-pi-0 VLA architecture, which takes multi-camera images and produces trajectory waypoints through a vision encoder, language model backbone, and action decoder. The MoE modifications are applied at two levels.
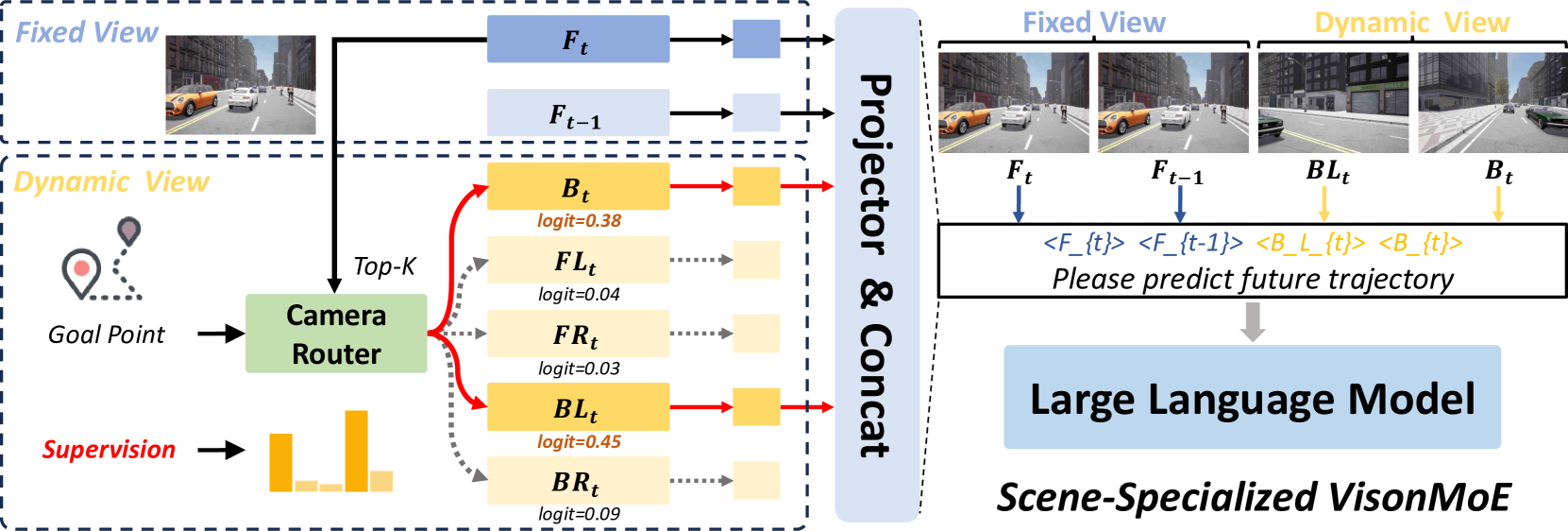
The Vision MoE implements dynamic view selection. A lightweight camera router analyzes the current driving context (including goal points and vehicle state) to compute probability distributions across all available camera views using top-K selection. The router considers current driving maneuver (lane changing, turning, parking), environmental context (intersections, highway, urban), and goal waypoint information. The Vision MoE router is trained using cross-entropy loss with ground-truth camera view annotations, encouraging the model to learn meaningful associations between driving contexts and relevant camera views. This is a hard routing decision (cameras are processed or not), unlike soft attention typically used in multi-camera fusion.
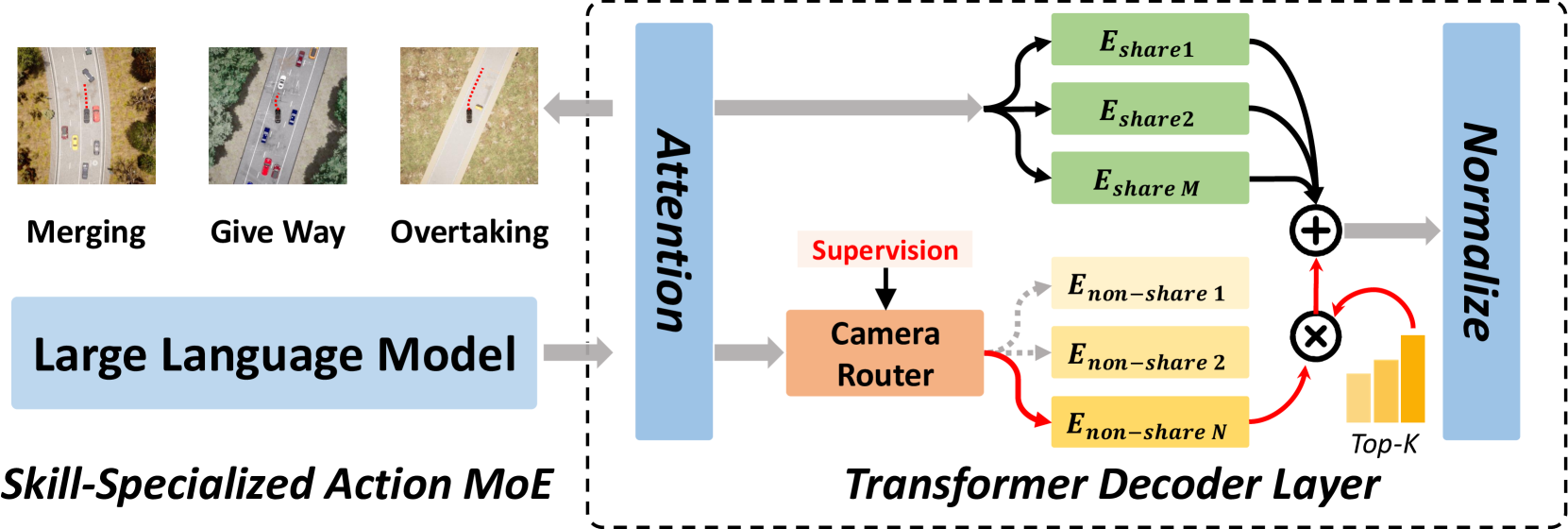
The Action MoE incorporates multiple specialized expert networks within the action generation decoder: merging experts (highway merging scenarios), give-way experts (yielding and intersection navigation), overtaking experts (passing maneuvers), and general experts (common driving scenarios). The Action router uses cross-entropy loss with supervision to learn appropriate expert selection. The MoE structure is embedded within the flow-matching transformer decoder, allowing specialized experts to influence trajectory generation while maintaining flow-matching benefits. Outputs of selected experts are combined using router confidence weights.
Two-Stage Training Strategy: In Stage 1, both MoE modules select ground-truth experts while training routing mechanisms. In Stage 2, the system transitions to router-based expert selection, removing ground-truth annotation dependence. Load balancing losses ensure all experts receive sufficient training signal and prevent expert collapse.
Results
| Metric | DriveMoE | Drive-pi-0 Baseline | Delta |
|---|---|---|---|
| Driving Score | 74.22 | 60.45 | +13.77 |
| Success Rate | 48.64% | 30.00% | +18.64% |
| Ablation | Driving Score Impact |
|---|---|
| Remove Vision MoE | -5.54 (DS: 68.68) |
| Remove Action MoE | -6.91 (DS: 67.31) |
| Optimal expert count | 6 non-shared experts |
- Bench2Drive state-of-the-art: Driving Score 74.22 (vs. baseline Drive-pi-0 at 60.45), Success Rate 48.64% (vs. 30.00% baseline), with improved performance on challenging maneuvers like emergency braking and aggressive turning
- Mode averaging eliminated: expert specialization allows each driving skill to be handled by a dedicated expert rather than averaged across a shared parameter set
- Vision MoE impact: Removing Vision MoE led to DS drop to 68.68 (from 74.22), demonstrating value of dynamic camera view selection
- Action MoE impact: Eliminating Action MoE resulted in DS drop to 67.31 (from 74.22), confirming importance of skill specialization
- Router training validated: Models trained without explicit router supervision showed degraded performance, validating the two-stage training approach
- Expert count analysis: Optimal performance achieved with 4-6 experts per MoE module, with diminishing returns beyond this range due to load balancing issues
- The dual-level MoE provides complementary benefits -- Vision MoE and Action MoE each contribute independently, with the combination outperforming either alone
- Authors indicate they will release code and models of DriveMoE and Drive-pi-0
Limitations & Open Questions
- MoE routing quality is critical -- incorrect expert selection could lead to worse performance than monolithic models, and routing failures may be hard to diagnose
- Training MoE architectures is more complex than standard models due to load balancing requirements and routing stability concerns
- Evaluation is Bench2Drive/simulation only without real-world deployment validation
Connections
- Autonomous Driving
- Vision Language Action
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment
- Emma End To End Multimodal Model For Autonomous Driving
- Gpipe Easy Scaling With Micro Batch Pipeline Parallelism