Agent-Driver: A Language Agent for Autonomous Driving
Overview
Agent-Driver reframes autonomous driving as a cognitive agent problem, positioning a large language model as the central reasoning and planning engine rather than treating it as a drop-in replacement for individual modules in the perception-prediction-planning pipeline. The key insight is that an LLM can orchestrate specialized tools (perception detectors, trajectory predictors, map queries) much like a human driver selectively attends to relevant information, rather than processing all sensor data indiscriminately. This tool-use paradigm distinguishes Agent-Driver from earlier LLM-for-driving work like GPT-Driver, which reformulated planning as direct language generation.
The system introduces three core components: a tool library of over 20 specialized functions that dynamically retrieve scene-relevant information, a cognitive memory module that combines commonsense traffic knowledge with experiential memory of successful driving scenarios, and a reasoning engine that performs chain-of-thought analysis, motion planning reformulated as language modeling, and self-reflection with collision checking. The cognitive memory uses a two-stage retrieval mechanism mixing vector similarity search with LLM-based ranking, enabling the system to recall relevant past driving experiences and apply traffic rules contextually.
Agent-Driver achieves strong results on both open-loop and closed-loop benchmarks: a 0.09% collision rate on nuScenes (ST-P3 metrics) with 0.37m average L2 error, and 91.37% route completion on CARLA Town05-Short. Most notably, the system demonstrates remarkable data efficiency, outperforming baseline methods using only 1% of the training data, and produces zero invalid waypoint outputs across thousands of validation scenarios. The work is significant as one of the earliest papers to demonstrate that LLMs can effectively serve as cognitive agents orchestrating the entire driving pipeline, with transparency in decision-making as a native feature rather than a post-hoc addition.
Key Contributions
- LLM-as-cognitive-agent paradigm: Positions the LLM as a central orchestrator that dynamically invokes specialized tools, rather than as a monolithic end-to-end model or a simple planner replacement
- Tool library with 20+ functions: Specialized functions (e.g.,
get_leading_object_detection(),get_pred_trajs_for_object()) that mimic human selective attention by retrieving only task-relevant information - Cognitive memory with two-stage retrieval: Combines commonsense knowledge (traffic rules, safety guidelines) with experiential memory, using vector search followed by LLM-based re-ranking to surface the most relevant past scenarios
- Chain-of-thought reasoning with self-reflection: The reasoning engine performs step-by-step analysis including task decomposition, motion planning as language, and collision checking for safety validation
- Strong few-shot performance: Outperforms baselines with only 1% of training data, demonstrating the data efficiency advantages of leveraging pretrained LLM knowledge
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ Agent-Driver Architecture │
├──────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────────┐ ┌──────────────────────────────────────┐│
│ │ Tool Library │ │ Cognitive Memory ││
│ │ (20+ functions) │ │ ┌────────────┐ ┌────────────────┐ ││
│ │ get_leading_obj()│ │ │ Commonsense │ │ Experiential │ ││
│ │ get_pred_trajs() │ │ │ (rules, │ │ (past driving │ ││
│ │ get_lane_info() │ │ │ safety) │ │ scenarios) │ ││
│ │ get_traffic() │ │ └─────┬──────┘ └───────┬────────┘ ││
│ └────────┬─────────┘ │ └────┬────────────┘ ││
│ │ │ Vector Search + LLM Re-rank ││
│ │ └──────────────┬───────────────────────┘│
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ LLM Reasoning Engine │ │
│ │ ┌──────────┐ ┌──────────┐ ┌───────────┐ ┌───────────┐ │ │
│ │ │1. Task │ │2. Motion │ │3. Self- │ │4. Correct-│ │ │
│ │ │ Planning │►│ Planning │►│ Reflect │►│ ion │ │ │
│ │ └──────────┘ └──────────┘ └───────────┘ └─────┬─────┘ │ │
│ └─────────────────────────────────────────────────┼────────┘ │
│ ▼ │
│ Trajectory Waypoints │
└──────────────────────────────────────────────────────────────────┘
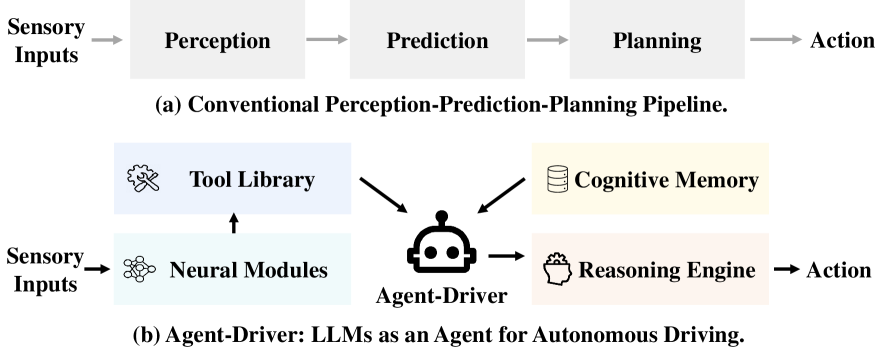
Agent-Driver's architecture centers on three interconnected components that together enable the LLM to function as a cognitive driving agent.
Tool Library. The system maintains a library of over 20 callable functions organized by driving subtask. These include perception tools (get_leading_object_detection(), get_surrounding_vehicles()), prediction tools (get_pred_trajs_for_object()), and map query tools (get_lane_info(), get_traffic_signal_state()). Each tool wraps a specialized neural module or database query, converting structured driving data into natural language descriptions that the LLM can reason over. The LLM selects which tools to invoke based on the current driving context, analogous to how human drivers selectively attend to relevant elements rather than processing everything simultaneously.
Cognitive Memory. This module has two components: (1) a commonsense memory bank encoding traffic rules, safety guidelines, and general driving conventions as text; and (2) an experiential memory that stores successful past driving scenarios with their associated reasoning traces and actions. Retrieval operates in two stages: first, a vector similarity search identifies candidate memories, then the LLM re-ranks these candidates for contextual relevance to the current scenario. This dual-stage approach ensures both efficiency (fast vector retrieval) and quality (LLM-based semantic filtering).
Reasoning Engine. Given tool outputs and retrieved memories, the reasoning engine performs chain-of-thought planning in four steps: (1) task planning -- decomposing the driving task into subtasks and selecting appropriate tools; (2) motion planning -- generating trajectory waypoints reformulated as a language modeling task; (3) self-reflection -- analyzing the proposed trajectory for potential collisions or rule violations; and (4) correction -- adjusting the trajectory if safety issues are detected. This self-reflective loop is a distinguishing feature that provides a mechanism for safety validation before action execution.
The planning output is a sequence of future waypoint coordinates at fixed time intervals, consistent with the nuScenes planning benchmark format. The LLM generates these as text tokens, with the self-reflection step providing an additional safety check that can trigger trajectory re-generation.
Results
Agent-Driver demonstrates competitive or superior performance across both open-loop and closed-loop evaluations:
nuScenes Open-Loop Planning (ST-P3 metrics):
| Method | L2 (avg, m) ↓ | Collision (%) ↓ |
|---|---|---|
| Agent-Driver | 0.37 | 0.09 |
| GPT-Driver | 0.44 | 0.17 |
| VAD | 0.37 | 0.14 |
| ST-P3 | 2.11 | 0.71 |
CARLA Closed-Loop (Town05-Short):
| Method | Route Completion (%) ↑ | Driving Score ↑ |
|---|---|---|
| Agent-Driver | 91.37 | 57.33 |
| VAD | 87.26 | 64.29 |
| ST-P3 | 86.74 | 55.14 |
| TransFuser | 78.41 | 54.52 |
Key findings: - Over 30% collision rate improvement compared to prior methods on nuScenes - Zero invalid waypoint outputs across thousands of validation scenarios, indicating robust output formatting - Few-shot superiority: With only 1% of training data, Agent-Driver outperforms baselines trained on full datasets, demonstrating strong data efficiency from leveraging pretrained LLM knowledge - The chain-of-thought reasoning traces provide interpretable decision rationale, enabling human inspection of the planning process
Limitations & Open Questions
- Latency: Tool invocation and multi-step LLM reasoning introduce significant computational overhead compared to direct neural planners, making real-time deployment challenging without optimization
- Tool library design: The set of available tools is hand-designed; automatic tool discovery or generation could improve generality
- Numeric precision: Like GPT-Driver, trajectory waypoints are generated as language tokens, inheriting the fundamental tension between discrete tokenization and continuous coordinate precision
- Open-loop evaluation limitations: While CARLA closed-loop results are included, the primary nuScenes evaluation is open-loop, which has known weak correlation with actual driving quality (as shown by "Is Ego Status All You Need?")
- Memory scalability: The experiential memory's effectiveness at scale (millions of scenarios) and its interaction with distribution shift in deployment remain untested
- Is tool-use the right abstraction? Later work (EMMA, ORION) moves toward tighter integration of perception and planning -- it remains unclear whether the tool-use paradigm or the unified model paradigm will prove more scalable
Connections
Related papers in the wiki: - Gpt Driver Learning To Drive With Gpt -- direct predecessor; Agent-Driver extends GPT-Driver's planning-as-language paradigm with tool use, memory, and self-reflection - Drivelm Driving With Graph Visual Question Answering -- similar chain-of-thought decomposition of driving reasoning, but via graph VQA rather than tool use - Lmdrive Closed Loop End To End Driving With Large Language Models -- another LLM-based driving system with language-conditioned closed-loop control - Drivemlm Aligning Multi Modal Llms With Behavioral Planning States -- concurrent work using LLM for behavioral planning decisions - Emma End To End Multimodal Model For Autonomous Driving -- later work that takes the opposite approach (unified model vs. tool-use agent) - Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation -- later holistic VLA that integrates reasoning into a single forward pass - Senna Bridging Large Vision Language Models And End To End Autonomous Driving -- decoupled reasoning + E2E planning, a middle ground between Agent-Driver's tool-use and EMMA's full unification - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- foundational technique for the reasoning engine - React Synergizing Reasoning And Acting In Language Models -- ReAct's reasoning-and-acting paradigm directly inspired Agent-Driver's tool-use and self-reflection approach - Reason2Drive Towards Interpretable And Chain Based Reasoning For Autonomous Driving -- reasoning chains for driving with large-scale video-text data - Planning -- planning module context - Autonomous Driving -- broader autonomous driving landscape - Vision Language Action -- VLA paradigm evolution