ReAct: Synergizing Reasoning and Acting in Language Models
Overview
Large language models had demonstrated two powerful capabilities in isolation: chain-of-thought reasoning for multi-step problem solving, and action generation for interacting with external environments. ReAct bridges these by proposing a simple yet effective paradigm where the model interleaves reasoning traces (free-form "thoughts") with task-specific actions in a single generation stream. The core insight is that reasoning and acting are synergistic -- reasoning helps the agent plan, track progress, and handle exceptions, while observations from acting ground the reasoning in real-world information and reduce hallucination.
The method works by expanding the agent's action space from A (domain-specific actions) to A_hat = A ∪ L, where L is the space of natural-language thoughts. Thoughts do not affect the external environment but update the agent's internal context, enabling it to compose information, formulate strategies, and reflect on observations. The approach requires no fine-tuning or architectural changes -- it operates entirely through few-shot in-context learning with human-authored trajectories as exemplars, using PaLM-540B as the primary backbone.
ReAct achieves strong results across diverse tasks: on FEVER fact verification, it reaches 60.9% accuracy versus 56.3% for chain-of-thought alone, with hallucination rates cut from 14% to 6%. On ALFWorld interactive decision-making, ReAct achieves 71% success rate with just 1-2 examples, compared to 45% for act-only baselines and 37% for BUTLER (which requires 10^5 expert trajectories). The paper further shows that combining ReAct with CoT self-consistency yields the best overall performance, demonstrating the complementary nature of internal reasoning and external grounding. ReAct became foundational to the LLM agent paradigm, directly influencing tool-use frameworks, retrieval-augmented generation, and autonomous agent systems.
Key Contributions
- Unified reasoning-and-acting framework: Expands the agent action space to include language-based "thoughts" interleaved with domain actions, enabling synergistic reasoning and acting in a single generation stream
- Few-shot agent prompting without training: Achieves strong interactive task performance through in-context learning with human-authored thought-action-observation trajectories, requiring no fine-tuning
- Reduced hallucination through grounding: External information retrieval during reasoning cuts hallucination rates dramatically (14% to 6% false positive rate on FEVER vs. CoT alone)
- Task-adaptive thought generation: Demonstrates two thought strategies -- dense thoughts alternating with every action for knowledge tasks, and sparse asynchronous thoughts for decision-making tasks
- Complementarity of ReAct and CoT: Shows that hybrid methods (ReAct → CoT-SC fallback, and vice versa) outperform either alone, establishing that internal and external reasoning are complementary
Architecture
┌─────────────────────────────────────────────────────┐
│ ReAct Agent Loop │
│ │
│ ┌───────────────────────────────────────────────┐ │
│ │ LLM (PaLM-540B) with Few-Shot Exemplars │ │
│ │ │ │
│ │ Context: [exemplar trajectories] + [history] │ │
│ └────────────────────┬──────────────────────────┘ │
│ │ │
│ Generate â_t ∈ A ∪ L │
│ │ │
│ ┌────────┴────────┐ │
│ ▼ ▼ │
│ ┌────────────────┐ ┌──────────────┐ │
│ │ Thought (∈ L) │ │ Action (∈ A) │ │
│ │ "I need to │ │ search[query]│ │
│ │ find..." │ │ lookup[term] │ │
│ │ │ │ finish[ans] │ │
│ └───────┬────────┘ └──────┬───────┘ │
│ │ │ │
│ │ (no env effect) │ │
│ ▼ ▼ │
│ ┌────────────┐ ┌──────────────┐ │
│ │ Update │ │ Environment │──► Obs │
│ │ Context │ │ (Wikipedia, │ │
│ │ Only │ │ ALFWorld,..)│ │
│ └────────────┘ └──────────────┘ │
│ │ │ │
│ └────────┬────────┘ │
│ ▼ │
│ Append to history ĉ_t │
│ Loop until finish │
└─────────────────────────────────────────────────────┘
Method

ReAct operates within a standard agent-environment interaction loop but augments it with a language-based thought space. At each step, the model generates either a thought or an action:
- Thoughts (prefixed
Thought:) are free-form language that reason over the current context. They do not produce observations from the environment. Thoughts compose information from prior observations, formulate sub-goals, track progress, handle exceptions, and revise strategies. - Actions (prefixed
Act:) are domain-specific operations that produce environment observations. For knowledge tasks:search[entity],lookup[string],finish[answer]. For interactive environments: navigation, object manipulation, or web interface commands. - Observations (prefixed
Obs:) are environment feedback returned after each action.
The generation is structured as a few-shot prompting approach: human-authored exemplar trajectories demonstrate the interleaved thought-action-observation pattern, and the model follows this format for new tasks. For knowledge-intensive tasks (HotpotQA, FEVER), thoughts are generated densely -- typically before every action -- to decompose multi-hop questions and reason about retrieved evidence. For interactive decision-making (ALFWorld, WebShop), thoughts are generated sparsely and asynchronously, providing high-level goal decomposition and reflection only when needed.
The key equations are simple. The standard action generation at time t is:
a_t ~ π(a_t | o_t, c_t) where c_t = (o_1, a_1, ..., o_{t-1}, a_{t-1})
ReAct modifies this so the context also includes thoughts:
â_t ~ π(â_t | o_t, ĉ_t) where â_t ∈ A ∪ L
When â_t is a thought, no observation is generated; when it is an action, the environment returns o_{t+1}. This minimal modification yields substantial behavioral improvements because thoughts enable the model to maintain working memory, plan ahead, and recover from errors.
Results
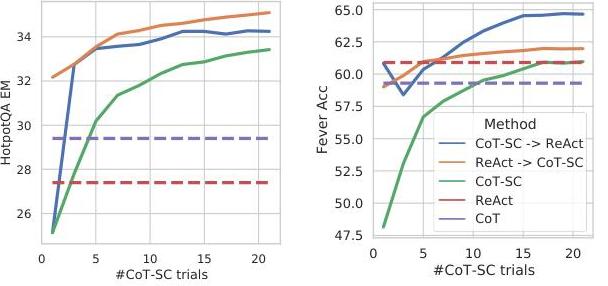
Knowledge-Intensive Reasoning
| Method | HotpotQA (EM) | FEVER (Acc) |
|---|---|---|
| Standard Prompting | 28.7 | 57.1 |
| CoT Prompting | 29.4 | 56.3 |
| Act Only | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| CoT-SC (21 samples) | 33.4 | 60.4 |
| ReAct → CoT-SC | 35.1 | 62.0 |
| CoT-SC → ReAct | 34.2 | 64.6 |
ReAct outperforms CoT on FEVER by 4.6% and significantly reduces hallucination. On HotpotQA, ReAct slightly underperforms CoT due to retrieval limitations, but the hybrid ReAct → CoT-SC achieves the best overall HotpotQA result (35.1% EM), and CoT-SC → ReAct achieves the best FEVER result (64.6%). Error analysis shows ReAct's false positive rate is 6% versus CoT's 14%, confirming the grounding benefit.
Interactive Decision-Making
| Method | ALFWorld (Success %) | WebShop (Success %) |
|---|---|---|
| BUTLER (10^5 trajectories) | 37 | -- |
| Act Only (1-2 shot) | 45 | 30 |
| ReAct (1-2 shot) | 71 | 40 |
| IL+RL baselines | -- | 29 |
On ALFWorld, ReAct nearly doubles the act-only baseline (71% vs 45%) with just 1-2 in-context examples, and dramatically outperforms BUTLER which was trained on 10^5 expert trajectories. On WebShop, ReAct achieves a 10% absolute improvement over prior IL+RL methods.
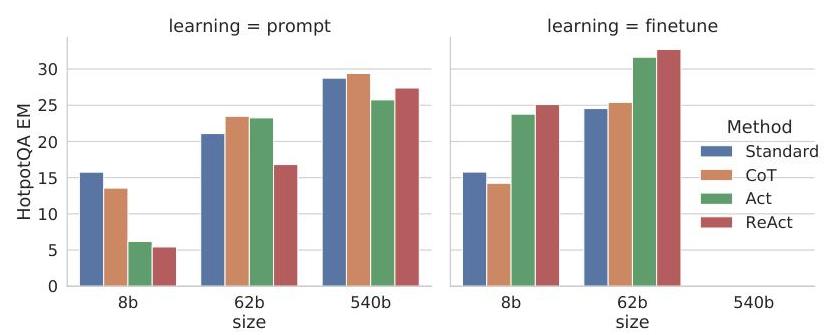
Fine-tuning Experiments
Fine-tuning smaller models (PaLM-8B/62B) on ReAct-format trajectories generated by PaLM-540B showed that: (1) ReAct fine-tuning substantially outperforms standard fine-tuning, (2) gains transfer across tasks, and (3) the approach teaches generalizable reasoning-and-acting skills rather than task-specific memorization.
Limitations & Open Questions
- Retrieval bottleneck on multi-hop reasoning: On HotpotQA, ReAct is limited by the quality of Wikipedia search -- if the right article is not retrieved, reasoning cannot compensate, leading to lower performance than CoT on some questions
- Prompt sensitivity: Performance depends on the quality and format of human-authored exemplar trajectories; no principled method exists for selecting optimal demonstrations
- Thought faithfulness: Like CoT, the generated thoughts may not faithfully represent the model's actual computation -- they are post-hoc verbalizations that appear reasonable but may not reflect internal mechanisms
- Scale dependence: The approach relies on large models (540B) for strong performance; smaller models struggle to maintain coherent interleaved reasoning and acting
- Action space design: The effectiveness of ReAct depends on having well-designed action APIs (search, lookup, finish); extending to environments with large or continuous action spaces remains underexplored
Connections
Related papers in the wiki: - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- ReAct directly extends CoT by adding grounded actions; the paper shows CoT and ReAct are complementary - Language Models Are Few Shot Learners -- GPT-3's few-shot in-context learning is the foundational capability that ReAct exploits for agent prompting - Attention Is All You Need -- the transformer architecture underpinning the PaLM backbone - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT established retrieval-oriented NLP that ReAct's search actions build upon - Ecot Embodied Chain Of Thought Reasoning For Vision Language Action Models -- extends the ReAct idea of interleaved reasoning to embodied VLA policies with chain-of-thought for robot control - A Language Agent For Autonomous Driving -- Agent-Driver applies ReAct-style reasoning-and-acting to autonomous driving with tool use and cognitive memory - Foundation Models -- ReAct exemplifies the "LLM as agent" paradigm within the foundation model landscape