Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Overview
Language models are typically used in a left-to-right token-generation mode, which limits their ability to explore alternative reasoning paths or backtrack from mistakes. Tree of Thoughts (ToT) addresses this fundamental limitation by generalizing the chain-of-thought (CoT) prompting paradigm into a structured search over a tree of coherent reasoning steps ("thoughts"). Where CoT produces a single linear chain, ToT maintains and explores multiple candidate reasoning paths simultaneously, enabling deliberate decision-making akin to dual-process "System 2" thinking.
The core insight is to treat the language model itself as both a generator of candidate reasoning steps and a heuristic evaluator of intermediate states -- then wrap classical search algorithms (BFS, DFS) around it. Each node in the tree represents a partial solution state, and the LM both proposes next steps and judges which branches are most promising. This allows lookahead, backtracking, and deliberate exploration, which are impossible in standard autoregressive generation or simple CoT prompting.
ToT dramatically improves performance on tasks requiring non-trivial planning and search. On the Game of 24 mathematical reasoning task, ToT achieves 74% success compared to just 4% for chain-of-thought prompting. On creative writing coherence and mini crossword puzzles, ToT similarly outperforms standard prompting baselines by large margins, demonstrating that structured search over LM-generated thoughts is a powerful general-purpose problem-solving framework.
Key Contributions
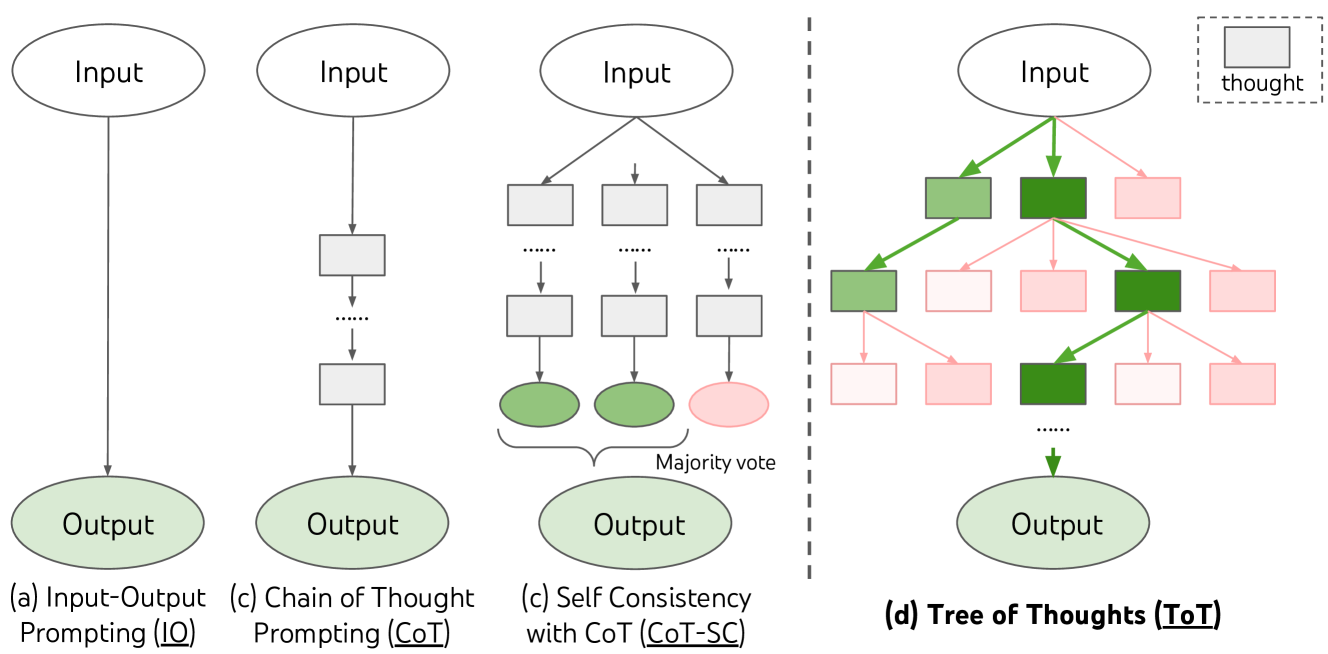
- Generalizes CoT to tree-structured reasoning: Frames LM inference as search over a tree of "thoughts" (coherent language sequences serving as intermediate reasoning steps), unifying and extending prior prompting methods (IO, CoT, CoT-SC) as special cases.
- LM as heuristic evaluator: Uses the language model itself to evaluate intermediate reasoning states (via deliberate prompting), enabling value-guided search without any task-specific training or external reward models.
- Flexible search integration: Supports pluggable search algorithms (BFS, DFS) with configurable branching factors and pruning thresholds, adapting the exploration strategy to task structure.
- Massive gains on hard reasoning tasks: Achieves 74% on Game of 24 (vs. 4% CoT), 7.56 coherence on creative writing (vs. 6.93 CoT), and 60% word-level accuracy on mini crosswords with DFS.
- Modular, training-free framework: All components (thought decomposition, generation, evaluation, search) are modular and require only prompting -- no fine-tuning or gradient updates needed.
Architecture
┌─────────────────────────────────────────────────────┐
│ Tree of Thoughts (ToT) │
│ │
│ Problem x ──► [Root Node] │
│ │ │
│ ┌─────────┼─────────┐ Thought │
│ ▼ ▼ ▼ Generation │
│ [s1a] [s1b] [s1c] (LM proposes k) │
│ ✓ 0.8 ✓ 0.6 ✗ 0.1 State Evaluation │
│ │ │ │ (LM scores) │
│ ┌─┘ └──┐ ┌──┘ │
│ ▼ ▼ ▼ │
│ [s2a] [s2b] [s2c] ◄── Prune low-value states │
│ ✓ 0.9 ✗ 0.2 ✓ 0.7 │
│ │ │ │
│ ▼ ▼ │
│ [s3a] [s3b] ◄── Continue best branches │
│ ★ SOLUTION │
│ │
│ Search: BFS (bounded breadth b) │
│ or DFS (with backtracking on low value) │
│ │
│ IO: x ──────────────────────► y (single pass) │
│ CoT: x ── z1 ── z2 ── z3 ───► y (single chain) │
│ ToT: x ── tree of z's ──────► y (search) │
└─────────────────────────────────────────────────────┘
Architecture / Method
ToT is built on four modular components:
1. Thought Decomposition
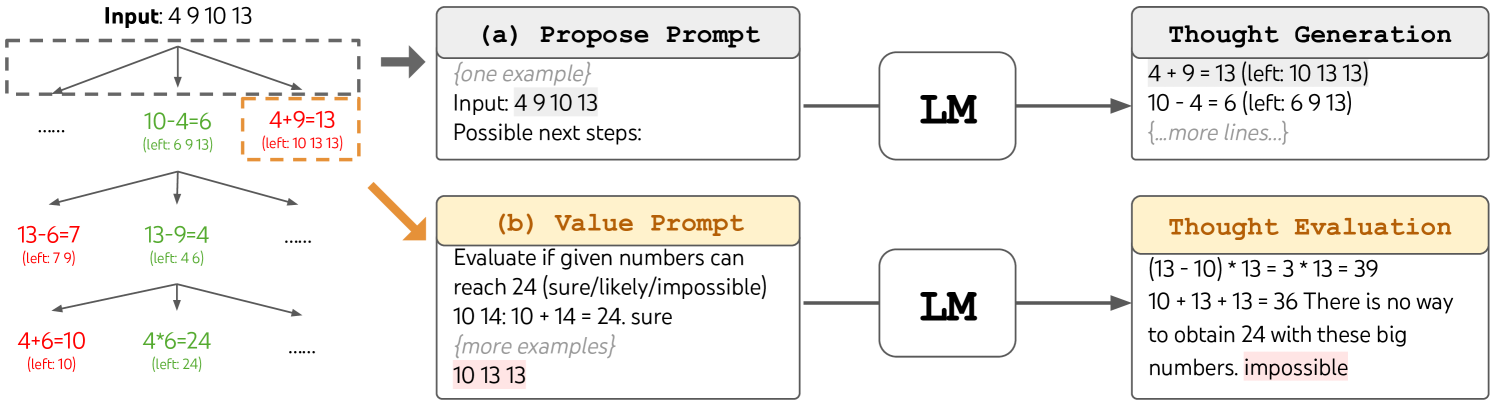
The problem is decomposed into a sequence of intermediate "thought" steps, where each thought is a coherent chunk of language (a few words to a paragraph) that represents a meaningful reasoning step. The granularity is task-dependent: for Game of 24, each thought is one arithmetic equation; for creative writing, each thought is a writing plan or paragraph; for crosswords, each thought is a word fill.
2. Thought Generation
At each tree node (partial solution state), the LM generates candidate next thoughts via one of two strategies:
- Sample (i.i.d.): Draw k independent completions from the LM's CoT prompt. Best when the thought space is rich and diversity matters.
- Propose (sequential): Prompt the LM to propose a list of k candidates in a single inference. Best when the thought space is more constrained.
3. State Evaluation
The LM evaluates intermediate states to guide search. Two strategies: - Value: Independently score each state (e.g., "sure / maybe / impossible" for Game of 24). The LM reasons about whether a partial solution can lead to success. - Vote: Compare multiple candidate states and vote for the most promising one. Used when absolute evaluation is hard but relative comparison is feasible.
4. Search Algorithm
- Breadth-First Search (BFS): Maintains a set of the
bmost promising states at each level. Best for problems with limited depth (e.g., Game of 24 with 3 steps). At each step, expand all states, evaluate, prune to topb. - Depth-First Search (DFS): Explores the most promising branch first, with backtracking when the LM evaluator deems a state unpromising. Best for deeper problems requiring backtracking (e.g., crosswords). Uses a pruning threshold on the value function.
Pseudocode (BFS variant)
Input: LM p_theta, problem x, thought generator G, state evaluator V,
breadth limit b, number of steps T
S_0 = {x} # initial state set
for t = 1 to T:
candidates = {[s, z] : s in S_{t-1}, z in G(p_theta, s, k)} # generate k thoughts per state
V_t = V(p_theta, candidates) # evaluate all candidates
S_t = top-b candidates by V_t # keep best b states
return G(p_theta, S_T) # final generation from best state
Results
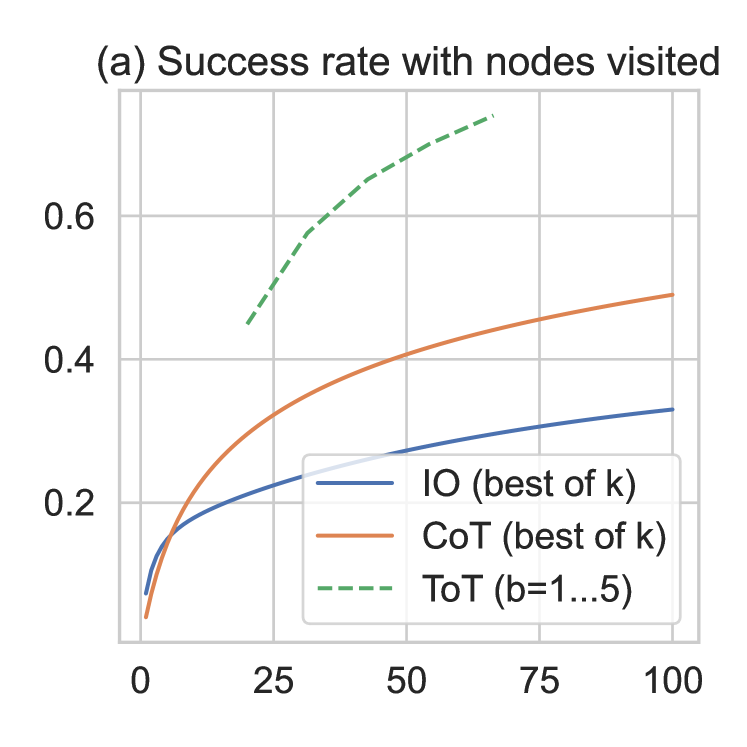
Game of 24 (Mathematical Reasoning)
| Method | Success Rate |
|---|---|
| IO prompting | 7.3% |
| Chain-of-Thought | 4.0% |
| CoT Self-Consistency (k=100) | 9.0% |
| CoT best-of-100 | 49.0% |
| ToT (BFS, b=5) | 74.0% |
Creative Writing (Coherence)
| Method | Coherence Score |
|---|---|
| IO prompting | 6.19 |
| Chain-of-Thought | 6.93 |
| ToT (BFS, b=5) | 7.56 |
ToT outputs were preferred by GPT-4 judges in 41 out of 100 pairwise comparisons against CoT (vs. 21 wins for CoT).
Mini Crosswords (5x5)
| Method | Word Success | Letter Success | Game Success |
|---|---|---|---|
| IO prompting | 16.0% | 38.7% | 0% |
| Chain-of-Thought | 15.6% | 40.6% | 1% |
| ToT (DFS) | 60.0% | 78.0% | 20% |
Limitations & Open Questions
- Computational cost: ToT requires substantially more LM calls than CoT (approximately 3-5x more calls than simpler approaches), making it expensive for routine tasks. The benefit is most justified for genuinely hard problems where single-pass reasoning fails.
- Task-specific prompt engineering: The thought decomposition granularity, generation strategy (sample vs. propose), evaluation strategy (value vs. vote), and search algorithm must be configured per task. There is no automatic way to select these.
- Evaluation reliability: Using the LM as its own evaluator inherits the LM's biases and failure modes. The heuristic quality depends on the base model's capabilities.
- Limited depth: BFS becomes intractable for deep trees; DFS with LM-based pruning can miss correct branches if the evaluator is unreliable at early stages.
- Comparison to fine-tuned approaches: ToT is purely inference-time -- it does not learn from experience. Whether search at inference time or learning from search traces (as in later work like STaR, MCTS-based methods) is more effective remains an open question.
- Scaling behavior: How ToT performance scales with model size, branching factor, and search budget is not thoroughly characterized.
Connections
Related papers in the wiki: - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- ToT directly generalizes CoT; CoT is a special case of ToT with a single chain (branching factor 1, depth T) - React Synergizing Reasoning And Acting In Language Models -- ReAct interleaves reasoning and acting; ToT provides a complementary framework for deliberate multi-path reasoning without environment interaction - Llms Cant Plan But Can Help Planning In Llm Modulo Frameworks -- Argues LLMs cannot plan on their own but can assist planning; ToT is a concrete instance of wrapping search around LM generation to achieve planning-like behavior - Language Models Are Few Shot Learners -- GPT-3 established few-shot prompting; ToT extends the paradigm from single-pass to search-based inference - Toolformer Language Models Can Teach Themselves To Use Tools -- Tool use as an alternative to pure reasoning; ToT instead augments reasoning through search structure - Planning -- ToT connects LLM reasoning to classical AI search and planning - Foundation Models -- Demonstrates inference-time compute scaling for foundation models