LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Overview
This paper by Subbarao Kambhampati and colleagues at Arizona State University addresses one of the most important questions in modern AI: can large language models autonomously plan and reason, or are they fundamentally limited to sophisticated pattern matching? The authors present a thorough empirical and conceptual analysis showing that LLMs cannot plan autonomously — even GPT-4 generates executable, goal-reaching plans only about 12% of the time on standard planning benchmarks — but they can serve as powerful approximate knowledge sources within structured verification frameworks.
The core contribution is the LLM-Modulo Framework, a neuro-symbolic architecture that treats LLMs as idea generators rather than autonomous planners. The framework operates through a generate-test-critique loop: the LLM proposes candidate plans, a bank of external critics (both hard/formal and soft/subjective) evaluates them, and a meta-controller feeds structured critiques back to the LLM for iterative refinement. This architecture preserves the LLM's strength in knowledge synthesis and candidate generation while offloading correctness verification to sound external systems.
The paper also debunks claims about LLM self-verification: experiments show that LLMs are no better at critiquing plans than generating them, sometimes rejecting correct solutions they previously produced. This finding is critical because it undermines "self-improving" LLM architectures that rely on the model to judge its own outputs. The LLM-Modulo framework addresses this by requiring external verification, providing correctness guarantees that autonomous LLM planning cannot.
Key Contributions
- Empirical evidence that LLMs cannot plan autonomously: Systematic benchmarking showing ~12% success rate on standard planning tasks, with performance collapsing further when action names are obfuscated (a change that does not affect traditional planners)
- Debunking LLM self-verification: Demonstrating that LLMs are unreliable critics of their own plans, undermining self-refinement approaches
- The LLM-Modulo Framework: A principled neuro-symbolic architecture combining LLM generation with external sound verification through generate-test-critique cycles
- Taxonomy of human roles: Careful delineation of domain expert, end user, and system roles to minimize human burden while maintaining correctness
- Reframing LLMs as "cognitive orthotics": Positioning LLMs as tools that augment robust planning systems rather than replace them
Architecture / Method
┌───────────────────────────────────────────────────────┐
│ LLM-Modulo Framework │
│ (Generate-Test-Critique Loop) │
│ │
│ ┌─────────────┐ candidate ┌────────────────┐ │
│ │ │────────────────►│ │ │
│ │ LLM │ plan │ Critics Bank │ │
│ │ (Generator) │ │ ┌──────────┐ │ │
│ │ │◄────────────────│ │Hard: │ │ │
│ │ │ structured │ │ Causal │ │ │
│ └──────┬──────┘ critique │ │ Resource │ │ │
│ │ │ │ Temporal │ │ │
│ │ │ │ Goal │ │ │
│ ┌──────┴──────┐ │ ├──────────┤ │ │
│ │ Meta- │◄────────────────│ │Soft: │ │ │
│ │ Controller │ pass/fail + │ │ Style │ │ │
│ │ │ diagnostics │ │ Prefs │ │ │
│ └─────────────┘ │ └──────────┘ │ │
│ └────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ Verified │ (sound: if accepted, plan is │
│ │ Plan Output │ correct w.r.t. checked props) │
│ └─────────────┘ │
└───────────────────────────────────────────────────────┘
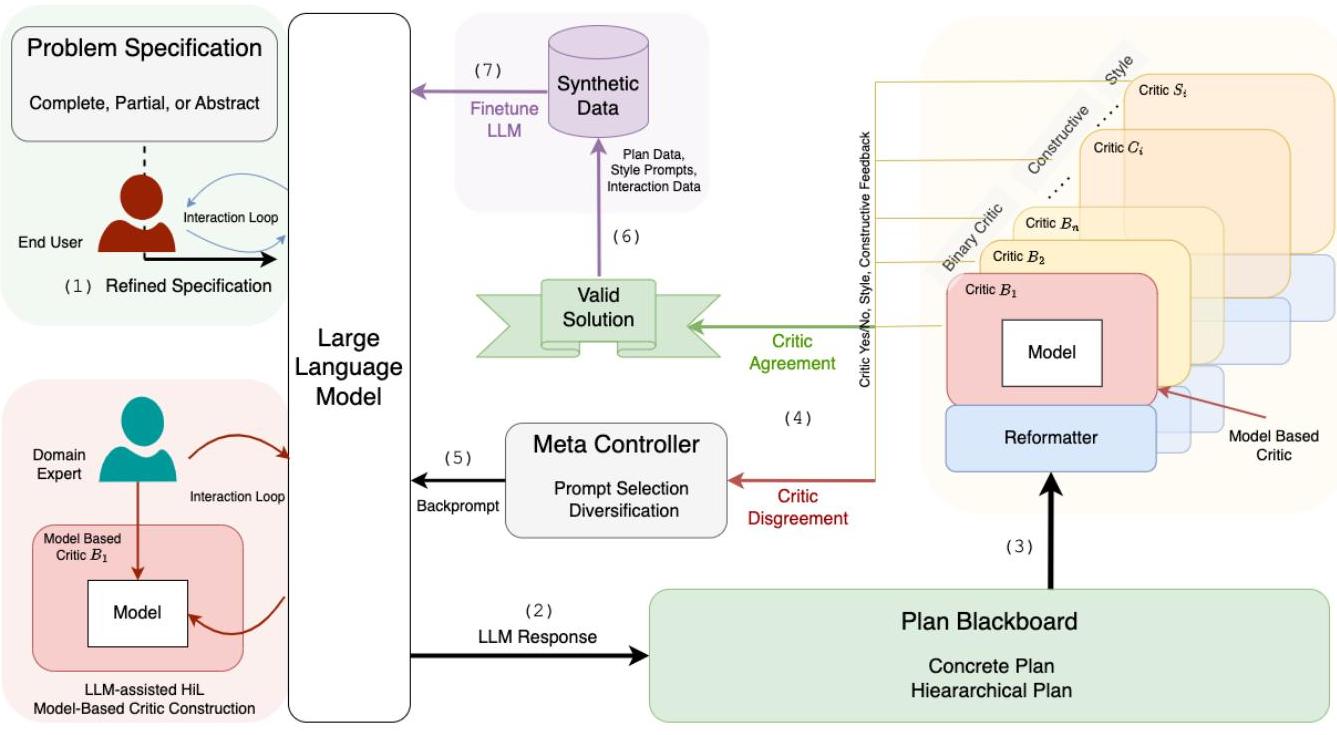
The LLM-Modulo Framework is built around a generate-test-critique loop with three core components:
Generator (LLM)
The LLM receives a problem specification and generates candidate plans. It acts as a "universal approximate knowledge source," leveraging its training data to propose plausible solutions. The key insight is that LLMs are treated as idea generators — their outputs are hypotheses to be verified, not final answers.
Critics (External Verifiers)
A bank of external critics evaluates each candidate: - Hard Critics ensure formal correctness: causal relationship validity, resource constraint satisfaction, temporal consistency, and goal reachability. These are sound verifiers — if they accept a plan, it is guaranteed correct with respect to the checked properties. - Soft Critics evaluate subjective qualities: style, explainability, user preferences, and domain-specific heuristics. These provide guidance without formal guarantees.
Meta-Controller
Processes feedback from all critics and formulates it into structured iterative prompts that guide the LLM's next generation step. This closes the loop, allowing the LLM to refine candidates based on specific failure modes identified by the critics.
Why LLMs Fail at Autonomous Planning
The paper identifies several root causes:
- Approximate retrieval, not model-based reasoning: LLMs predict the next token based on training distribution, not by simulating world states. Planning requires maintaining and updating a world model, which autoregressive generation does not support.
- Obfuscation sensitivity: When action names are replaced with meaningless tokens (e.g., "stack" → "X7Q"), LLM performance drops to near zero while traditional planners are unaffected. This confirms that LLMs rely on surface-level pattern matching from training data.
- Self-verification failure: LLMs asked to verify plans exhibit similar error rates to generation, and sometimes reject correct plans. This rules out the "generate then self-critique" paradigm as a path to reliable planning.
Human Role Taxonomy
The framework carefully separates human involvement: - Domain experts collaborate with LLMs to acquire formal domain models (one-time per domain) - End users work with LLMs to refine problem specifications (one-time per problem) - No direct human involvement in the iterative planning loop itself
Results
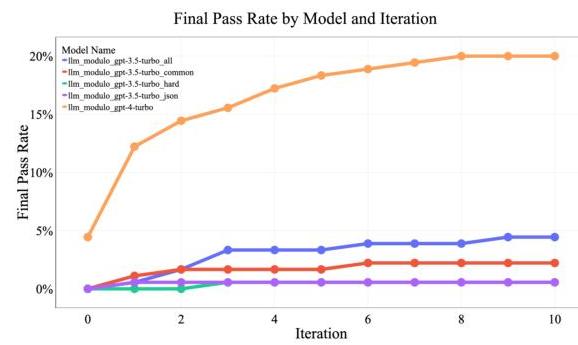
The framework is validated through two case studies demonstrating substantial improvements over autonomous LLM performance:
Classical Planning (VAL Validator)
| Domain | Autonomous LLM | LLM-Modulo | Improvement |
|---|---|---|---|
| Blocks World | ~30-40% | 82% | ~2x |
| Logistics | ~25-35% | 70% | ~2x |
Travel Planning (Natural Language Constraints)
| Method | Accuracy |
|---|---|
| Baseline LLM (autonomous) | 0.7% |
| LLM-Modulo | ~4.2% (6x improvement) |
While the absolute numbers in travel planning remain modest, the relative improvement demonstrates the framework's value. The low absolute accuracy reflects the genuine difficulty of planning with many interacting constraints, which is precisely the paper's point — these problems require systematic reasoning, not pattern matching.
Limitations & Open Questions
- Completeness not guaranteed: The framework guarantees soundness (returned plans are correct) but not completeness (it may fail to find a plan that exists). The LLM may not generate the right candidate within the iteration budget.
- Critic availability: The framework requires domain-specific external critics. For novel domains where no sound verifier exists, the framework degrades to autonomous LLM performance.
- Iteration cost: The generate-test-critique loop may require many iterations, making it slower and more expensive than a single LLM call. The paper does not provide detailed cost analysis.
- Domain model acquisition: While LLMs can assist domain experts in building formal models, this process still requires significant human expertise and effort.
- Scalability to complex domains: The case studies use relatively well-structured domains. How the framework performs on open-ended, partially observable planning problems (like real-world driving) remains an open question.
- Interaction with agentic systems: The paper warns that "acting without the ability to plan is surely a recipe for unpleasant consequences," raising important safety questions for LLM-based agents deployed in the real world.
Connections
Related papers in the wiki: - Chain Of Thought Prompting Elicits Reasoning In Large Language Models — CoT prompting is one of the techniques this paper critiques as insufficient for genuine planning; LLMs with CoT still fail on planning benchmarks - A Language Agent For Autonomous Driving — Agent-Driver uses LLMs as cognitive agents with tool use and memory for driving, exemplifying the "LLM as reasoning engine" paradigm that this paper argues needs external verification - Asyncdriver Asynchronous Large Language Model Enhanced Planner For Autonomous Driving — AsyncDriver decouples LLM guidance from real-time planning, a practical instantiation of the principle that LLMs should inform rather than replace planners - Driving With Llms Fusing Object Level Vector Modality For Explainable Autonomous Driving — Wayve's approach to LLM-for-driving with explainability, relevant to the paper's discussion of LLMs as knowledge sources - Language Models Are Few Shot Learners — GPT-3, the foundation for the class of models whose planning capabilities this paper evaluates - Planning — broader context on planning in autonomous systems - Foundation Models — the role of foundation models as components in larger systems