Language Models are Few-Shot Learners
Overview
GPT-3 is a 175 billion parameter autoregressive language model that demonstrated a remarkable emergent capability: in-context learning, where the model performs new tasks by conditioning on a few examples provided in the prompt, without any gradient updates or fine-tuning. The paper systematically evaluates this few-shot learning ability across dozens of NLP benchmarks and shows that task performance scales smoothly with model size, with the largest models achieving competitive or state-of-the-art results on many tasks using only natural language task descriptions and a handful of examples.
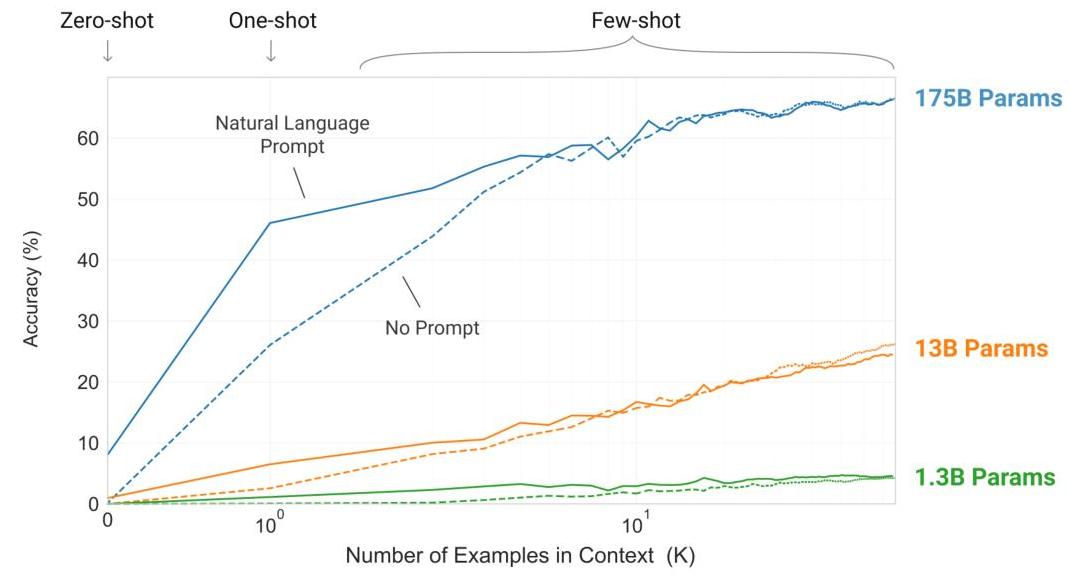
The paper's central finding is that sufficiently large language models can function as general-purpose few-shot learners. Rather than the traditional paradigm of pretraining followed by task-specific fine-tuning, GPT-3 can be "programmed" at inference time through carefully constructed prompts. This in-context learning capability emerges at scale -- smaller models show weak few-shot ability, while the 175B parameter model demonstrates strong performance across translation, question answering, arithmetic, and many other tasks.
GPT-3 made in-context learning a first-class systems primitive and catalyzed the field of prompt engineering. It is directly ancestral to the chain-of-thought reasoning paradigm, tool use in language models, and language-conditioned autonomy. The demonstration that a single model could perform diverse tasks without fine-tuning shifted the field's focus from task-specific architectures to general-purpose foundation models, fundamentally changing how the AI community thinks about building capable systems.
Key Contributions
- In-context learning at scale: Demonstrated that 175B parameter language models can perform new tasks by conditioning on examples in the prompt, without any parameter updates -- a qualitatively new capability that emerges at scale
- Systematic scaling analysis: Evaluated zero-shot, one-shot, and few-shot performance across model sizes from 125M to 175B parameters, showing smooth performance scaling with model size across dozens of tasks
- 175B parameter model training: Trained the largest dense language model of its time on 300B tokens of filtered internet text, establishing new scale frontiers for both model size and training data
- Broad task evaluation: Comprehensive evaluation across translation, question answering, cloze tasks, arithmetic, word unscrambling, and novel tasks, demonstrating generality of the in-context learning ability
- Analysis of societal implications: Extensive discussion of bias, fairness, energy consumption, and potential for misuse, setting a template for responsible AI research reporting
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ GPT-3 Architecture │
│ │
│ Input: "Translate English to French: cheese =>" │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Token Embedding │ vocab = 50257 (BPE) │
│ │ + Position Embed │ ctx_len = 2048 │
│ └────────┬────────┘ │
│ ▼ │
│ ┌─────────────────────────────────┐ │
│ │ Transformer Decoder Block x96 │ │
│ │ ┌───────────────────────────┐ │ │
│ │ │ Layer Norm (pre-norm) │ │ │
│ │ │ Masked Multi-Head Attn │ │ 96 heads │
│ │ │ (d_model=12288) │ │ d_head=128 │
│ │ │ + Residual │ │ │
│ │ ├───────────────────────────┤ │ │
│ │ │ Layer Norm (pre-norm) │ │ │
│ │ │ FFN (4 * 12288 = 49152) │ │ │
│ │ │ + Residual │ │ │
│ │ └───────────────────────────┘ │ │
│ └────────────┬────────────────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Layer Norm │ │
│ │ Linear ─► Vocab │ 175B parameters total │
│ │ Softmax │ ~3.14 x 10²³ FLOPs training │
│ └────────┬────────┘ │
│ ▼ │
│ Output: "fromage" │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ In-Context Learning (no gradient updates) │
│ │
│ Zero-shot: "Translate English to French: cheese =>" │
│ One-shot: "sea => mer, cheese =>" │
│ Few-shot: "sea => mer, hello => bonjour, cheese =>" │
│ │
│ Same frozen weights for all tasks │
└─────────────────────────────────────────────────────────┘
GPT-3 uses the same basic architecture as GPT-2: a decoder-only transformer with learned positional embeddings, alternating layers of masked multi-head self-attention and position-wise feed-forward networks, with pre-layer normalization (layer norm before attention and FFN, following the pre-activation pattern from residual network research).
The model comes in several sizes, with the largest (GPT-3 175B) having 96 transformer layers, 96 attention heads per layer, and a hidden dimension of 12288. The context window is 2048 tokens. Training uses a mixture of model parallelism across GPUs and data parallelism across nodes.
The training dataset is a filtered version of Common Crawl (approximately 410B tokens before filtering, reduced to approximately 300B tokens after quality filtering), supplemented with WebText2, Books1, Books2, and Wikipedia. Quality filtering uses a classifier trained to distinguish high-quality reference corpora from raw Common Crawl text. The data is weighted during training such that higher-quality sources are sampled more frequently.
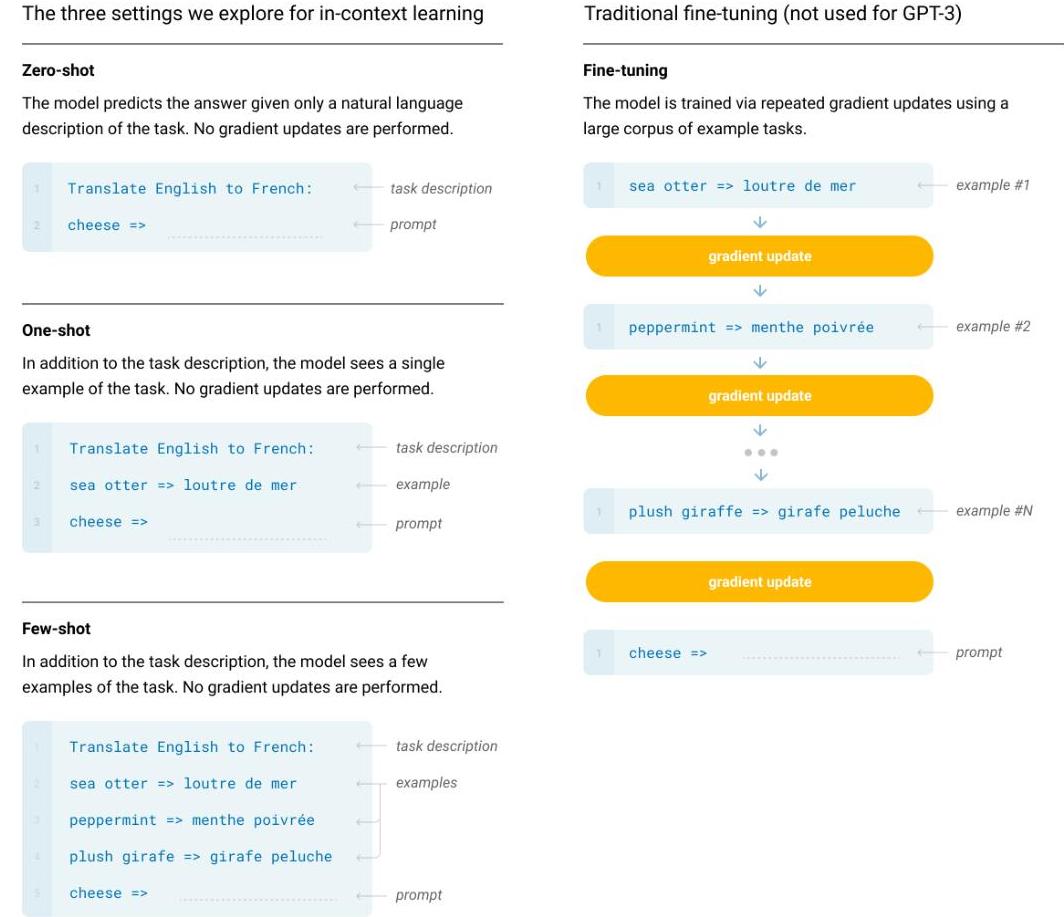
The key evaluation methodology introduces three regimes: (1) Zero-shot: the model receives only a natural language task description, (2) One-shot: the model receives one example of the task alongside the description, (3) Few-shot: the model receives K examples (typically 10-100, limited by context window). In all cases, no gradient updates are performed -- the model uses the same weights for all tasks. This contrasts with fine-tuning, where task-specific gradient updates adapt the model parameters.
Training uses Adam optimizer with a cosine learning rate schedule, batch size ramping from 32K to 3.2M tokens, and sequence length 2048. The total training compute is approximately 3.14 x 10^23 FLOPs.
Results
| Benchmark | GPT-3 Few-Shot | Previous SOTA | Notes |
|---|---|---|---|
| LAMBADA (accuracy) | 86.4% | 68.4% | +18% over prior SOTA |
| TriviaQA (accuracy) | 71.2% | 57.0% | Outperforms fine-tuned T5-11B |
| 2-digit arithmetic | 100% | - | Perfect accuracy |
| SAT Analogies | 65.2% | 57% (avg. applicant) | Exceeds average human |
- On many NLP benchmarks, GPT-3 few-shot matches or approaches the performance of fine-tuned BERT-large and other task-specific models, despite using no gradient updates
- Performance scales smoothly and predictably with model size across most tasks, with the gap between few-shot and fine-tuned baselines narrowing as model size increases
- On SuperGLUE, few-shot GPT-3 approaches the fine-tuned BERT-large baseline (71.8 vs 69.0), though it falls short of state-of-the-art fine-tuned models
- Strong performance on translation tasks (especially into English), competitive with unsupervised NMT systems and approaching supervised baselines for some language pairs
- Demonstrates basic arithmetic ability (two-digit addition and subtraction) that improves with model scale, suggesting emergent reasoning capabilities
- On novel tasks like word unscrambling and using new words in sentences, GPT-3 shows flexible in-context adaptation that would be difficult to achieve through fine-tuning alone
Limitations & Open Questions
- In-context learning is fundamentally limited by the context window (2048 tokens), restricting the number and complexity of examples that can be provided
- The model struggles with tasks requiring multi-step reasoning, mathematical precision, or factual consistency -- limitations that motivated later work on chain-of-thought prompting and retrieval augmentation
- The relationship between in-context learning and actual learning (gradient-based parameter updates) remains poorly understood -- whether the model is truly "learning" from examples or merely retrieving learned patterns is debated