Llama 2: Open Foundation and Fine-Tuned Chat Models
Overview
Llama 2 (Touvron et al., Meta AI, 2023) addresses the gap between open-source pretrained language models and polished, closed-source "product" LLMs like ChatGPT. While the original LLaMA showed that strong pretrained models could be released openly, Llama 2 extends this to the full product pipeline: pretraining at scale, supervised fine-tuning for dialogue, and iterative reinforcement learning from human feedback (RLHF) to produce chat-optimized models. The collection spans 7B, 13B, and 70B parameter variants, with Llama 2-Chat models specifically optimized for dialogue use cases.
The core approach combines three advances over LLaMA 1: (1) training on 2 trillion tokens (40% more data), (2) doubling the context length to 4,096 tokens, and (3) adopting grouped-query attention (GQA) for the larger models to improve inference efficiency. The fine-tuning pipeline is a multi-stage process that begins with supervised fine-tuning on 27,540 high-quality dialogue annotations, then applies iterative RLHF using dual reward models (helpfulness and safety) trained on over 1 million binary human preference comparisons, alternating between rejection sampling and proximal policy optimization (PPO).
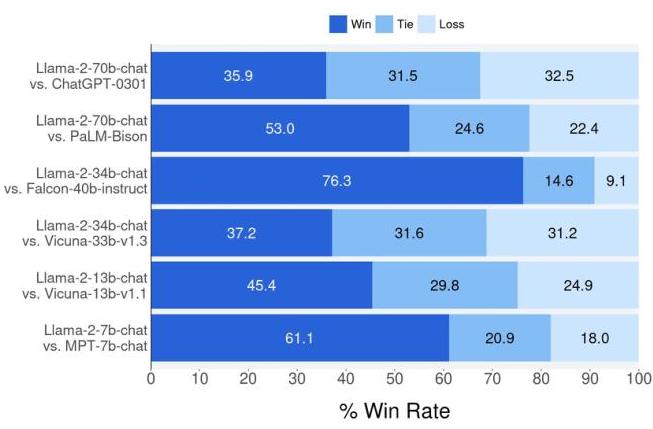
Llama 2 is one of the most impactful papers in the open-source LLM movement. The 70B Chat model achieves a 36% win rate against ChatGPT on human evaluations -- not parity, but remarkably competitive for an openly available model. More importantly, the paper's detailed documentation of the RLHF pipeline, safety fine-tuning methodology, and Ghost Attention (GAtt) technique for multi-turn consistency provided the research community with a reproducible blueprint for alignment that had previously been available only behind closed doors. Llama 2 became the backbone for an enormous ecosystem of fine-tuned models, and its descendants (Llama 3, Code Llama) continued the lineage. In the autonomy context, Llama 2 is directly used in systems like AsyncDriver (which uses Llama2-13B as an asynchronous LLM planner for driving) and serves as the architectural template for many VLA backbones.
Key Contributions
- Open-source RLHF pipeline: First detailed public documentation of a full RLHF process competitive with closed-source systems, including dual reward models, rejection sampling, and iterative PPO rounds
- Grouped-query attention (GQA) at scale: Adopted GQA for the 34B and 70B models, reducing KV cache size and improving inference throughput without meaningful quality loss
- Ghost Attention (GAtt): Novel technique for maintaining adherence to system-level instructions across extended multi-turn conversations by concatenating persistent instructions while zeroing loss on previous turn tokens
- Safety-first alignment: Comprehensive safety pipeline including adversarial red teaming by 350+ experts, separate safety reward model, context distillation for safe responses, and quantified reduction in violation rates (from 1.8 to 0.45 per person-hour)
- Scaling the pretraining recipe: 2T tokens, 4K context, demonstrating that the Chinchilla-optimal training philosophy (more data, appropriately-sized model) extends to the open-source regime
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ Llama 2 Training Pipeline │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Pretraining │───►│ SFT │───►│ RLHF │ │
│ │ 2T tokens │ │ 27.5K demos │ │ (iterative) │ │
│ │ 4K context │ │ high-quality│ │ x5 rounds │ │
│ └───────────────┘ └──────────────┘ └──────┬───────┘ │
│ │ │
│ ┌─────────────┴────────┐ │
│ │ RLHF Inner Loop │ │
│ │ │ │
│ ┌──────────────┐ │ 1. Rejection Sample │ │
│ │ Reward Models│◄─── 1M+ human ──►│ 2. PPO w/ KL pen. │ │
│ │ ┌──────────┐ │ preferences │ 3. Update policy │ │
│ │ │Helpfulness│ │ │ 4. Repeat │ │
│ │ └──────────┘ │ └──────────────────────┘ │
│ │ ┌──────────┐ │ │
│ │ │ Safety │ │ │
│ │ └──────────┘ │ │
│ └──────────────┘ │
│ │
│ Transformer Block (70B): │
│ ┌──────────────────────────────────────┐ │
│ │ Input ──► RMSNorm ──► GQA (8 KV, 64Q)──► + ──► │
│ │ ──► RMSNorm ──► SwiGLU FFN ──► + │
│ └──────────────────────────────────────┘ │
│ + RoPE positional embeddings │
└─────────────────────────────────────────────────────────────┘
Pretraining
Llama 2 uses a standard autoregressive transformer architecture building on LLaMA 1, with the following modifications:
- Pre-normalization using RMSNorm (Zhang & Sennrich, 2019)
- SwiGLU activation (Shazeer, 2020) in the feed-forward layers
- Rotary positional embeddings (RoPE) (Su et al., 2021)
- Grouped-query attention (GQA) for the 34B and 70B models: on 70B, 8 KV heads shared across 64 query heads, reducing KV cache by 8x versus standard multi-head attention while preserving quality
| Model | Parameters | Layers | Hidden dim | Heads | KV Heads | Context | Training tokens |
|---|---|---|---|---|---|---|---|
| Llama 2-7B | 6.7B | 32 | 4,096 | 32 | 32 (MHA) | 4,096 | 2.0T |
| Llama 2-13B | 13.0B | 40 | 5,120 | 40 | 40 (MHA) | 4,096 | 2.0T |
| Llama 2-70B | 69.8B | 80 | 8,192 | 64 | 8 (GQA) | 4,096 | 2.0T |
Training was conducted on Meta's Research Super Cluster and internal production cluster using NVIDIA A100-80GB GPUs. The training data is a mix of publicly available online data (no Meta user data), with upsampling of the most factual sources.
Fine-Tuning Pipeline
The fine-tuning process follows a staged approach:
-
Supervised Fine-Tuning (SFT): Fine-tuned on 27,540 high-quality vendor-annotated dialogue examples. The authors found that a small but high-quality dataset outperformed a larger but noisier one -- quality over quantity for SFT.
-
Reward Modeling: Two separate reward models (both initialized from pretrained Llama 2 checkpoints): - Helpfulness reward model -- trained on preference data where annotators chose the more helpful response - Safety reward model -- trained on preference data emphasizing safe, non-harmful responses - Over 1 million binary human preference comparisons collected across both models - Margin-aware loss: examples with larger annotator agreement margins receive higher weight
-
Iterative RLHF: Alternates between two complementary RL strategies: - Rejection sampling: Generate K responses per prompt, score with the reward model, keep the best. This produces better-than-average training data. - Proximal Policy Optimization (PPO): Standard PPO against the reward model, with KL penalty to prevent reward hacking - Multiple rounds of RLHF (the paper reports 5 rounds), each building on the previous checkpoint
Ghost Attention (GAtt)
GAtt addresses multi-turn consistency: LLMs often "forget" system instructions (e.g., "act as a pirate") after several turns of conversation. The technique: 1. Concatenates the system-level instruction to every user message in the training data 2. Zeros out the loss for all tokens in previous turns (only the latest assistant turn contributes to the loss) 3. This trains the model to condition on system instructions at every turn while keeping the actual context window manageable
Results
Llama 2 pretrained models outperform all existing open-source LLMs on most benchmarks:
| Model | Size | MMLU (5-shot) | TriviaQA (1-shot) | NQ (1-shot) | GSM8K (8-shot) | HumanEval (0-shot) |
|---|---|---|---|---|---|---|
| LLaMA 1 | 65B | 63.4 | 84.5 | 31.0 | 50.9 | 23.7 |
| Llama 2 | 70B | 68.9 | 85.0 | 33.0 | 56.8 | 29.9 |
| Falcon | 40B | 55.4 | -- | -- | 19.6 | -- |
| MPT | 30B | 46.9 | -- | -- | 15.2 | -- |
For Llama 2-Chat, human evaluation against competing chat models:
| Comparison | Win rate (Llama 2-Chat 70B) |
|---|---|
| vs. ChatGPT (GPT-3.5 Turbo) | 36% |
| vs. Falcon-40B-Instruct | 72% |
| vs. MPT-30B-Chat | 75% |
| vs. Vicuna-33B | 70% |
Safety improvements were dramatic: toxicity reduced to effectively 0% on ToxiGen, and truthfulness improved from 50.18% (pretrained) to 64.14% (Chat, via TruthfulQA). Red teaming violation rates dropped from 1.8 to 0.45 per person-hour across RLHF iterations for the Llama 2-Chat 7B model specifically (§4.3).
Limitations & Open Questions
- Gap to GPT-4: The 36% win rate against ChatGPT (GPT-3.5) highlights that open-source models still lagged behind the frontier at publication time; comparison with GPT-4 would show a larger gap
- Coding and math: Llama 2 underperforms on code generation and mathematical reasoning compared to models with code-heavy training mixes
- Reward model limitations: Dual reward model approach (helpfulness vs. safety) can create tension -- overly safe models sacrifice helpfulness, and the balance is hand-tuned
- Multi-turn degradation: While GAtt improves consistency, long multi-turn conversations still degrade in coherence
- English-centric: Training data is predominantly English, limiting multilingual capability
- Safety as alignment tax: Safety fine-tuning measurably reduces performance on some helpfulness benchmarks, raising the question of whether alignment and capability are fundamentally in tension or just require better methods
Connections
Related papers in the wiki: - Attention Is All You Need -- Transformer architecture that Llama 2 builds on - Language Models Are Few Shot Learners -- GPT-3 established the large autoregressive LLM paradigm that Llama 2 follows - Training Compute Optimal Large Language Models -- Chinchilla scaling laws directly influenced Llama 2's decision to train on 2T tokens with appropriately-sized models - Scaling Laws For Neural Language Models -- Kaplan et al. scaling laws that motivated the foundation model approach - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT established pretrain-then-adapt; Llama 2 extends this to pretrain-then-align - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- CoT reasoning capabilities that Llama 2-Chat can exhibit - Asyncdriver Asynchronous Large Language Model Enhanced Planner For Autonomous Driving -- Uses Llama2-13B as asynchronous LLM planner for driving - Foundation Models -- Llama 2 as a key open foundation model in the LLM lineage