Overview
AsyncDriver addresses the practical deployment problem of LLM-enhanced driving planners: LLMs are too slow for frame-by-frame planning. The key insight is that high-level driving guidance (lane intentions, route following, behavioral modes) changes slowly relative to frame-rate trajectory planning, so the LLM can operate asynchronously at a lower frequency while the real-time planner processes every frame. A fine-tuned Llama2-13B generates scene-associated instruction features from vectorized scene data and routing instructions, which are injected into a transformer-based planner via a model-agnostic adaptive injection block using cross-attention and learnable gating. Operating the LLM every 3 frames reduces inference time by ~40% with only ~1% accuracy loss, and the system remains performant even with LLM inference every 149 frames.
Key Contributions
- Asynchronous LLM-planner decoupling: LLM operates at a lower frequency than the real-time planner, reducing computational cost by ~40% with minimal accuracy loss
- Scene-associated instruction feature extraction: Multimodal processing of vectorized scene data and linguistic routing instructions via fine-tuned Llama2-13B (LoRA) to produce high-level guidance features
- Adaptive injection block: Model-agnostic integration mechanism using cross-attention and learnable gating to merge LLM guidance into any transformer-based planner
- Alignment Assistance Module: Five prediction heads for multi-modal alignment training (discarded at inference)
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ AsyncDriver Architecture │
├──────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────┐ │
│ │ LLM Branch (Async, every N frames) │ │
│ │ │ │
│ │ Vector Map Routing │ │
│ │ Encoder Instructions │ │
│ │ │ │ │ │
│ │ └─────┬───────┘ │ │
│ │ ▼ │ │
│ │ ┌──────────────────┐ ┌─────────────────┐ │ │
│ │ │ Llama2-13B │ │ Alignment Assist │ │ │
│ │ │ (LoRA fine-tuned)│ │ Module (5 heads) │ │ │
│ │ └────────┬─────────┘ │ [train only] │ │ │
│ │ │ └─────────────────┘ │ │
│ │ ▼ │ │
│ │ Instruction Features ──── cached ────────┐ │ │
│ └─────────────────────────────────────────┐ │ │ │
│ │ │ │
│ ┌──────────────────────────────────────┐ │ │ │
│ │ Planner Branch (every frame) │ │ │ │
│ │ │ │ │ │
│ │ Scene Data ──► Transformer Planner ◄─┘ │ │
│ │ ┌──────────────────┐ │ │
│ │ │ Adaptive Inject │◄──┘ │
│ │ │ Block (cross-attn │ │
│ │ │ + learnable gate) │ │
│ │ └────────┬─────────┘ │
│ │ ▼ │
│ │ Trajectory Output │
│ └──────────────────────────────────────────────────────────────┘
└──────────────────────────────────────────────────────────────────┘
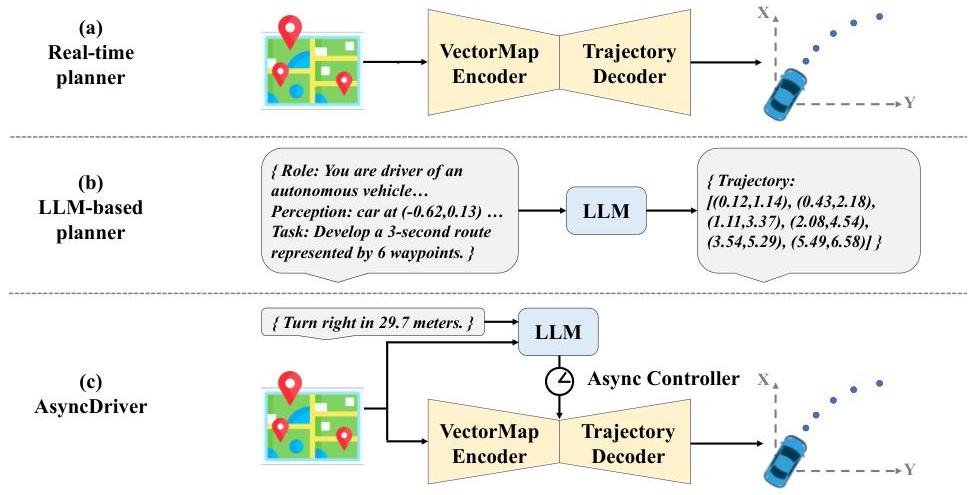
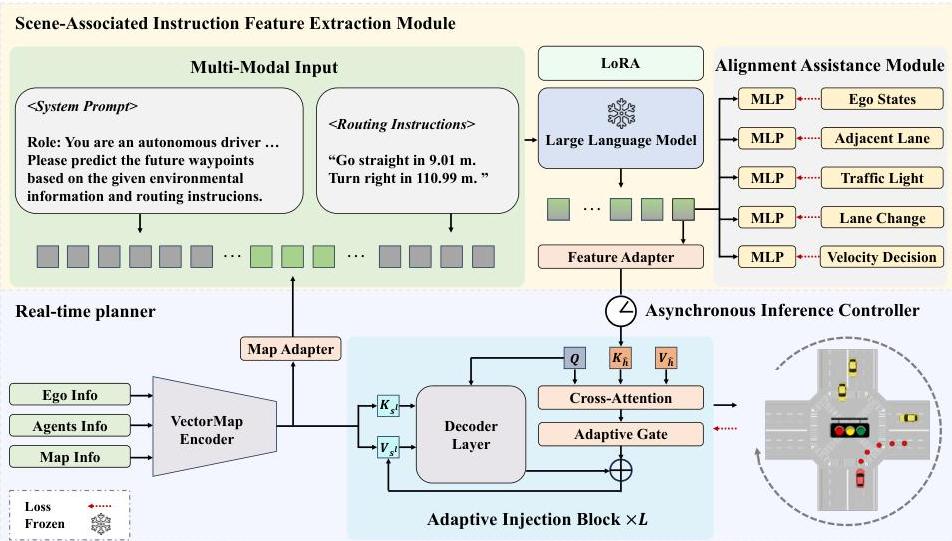
The system has three components:
Scene-Associated Instruction Feature Extraction: - Vector Map Encoder processes scene data (ego state, agent states, map elements) - Llama2-13B (fine-tuned with LoRA) processes combined embeddings to produce instruction features capturing scene understanding and routing guidance - Alignment Assistance Module with 5 prediction heads guides training; discarded at inference
Adaptive Injection Block: - Cross-attention mechanism integrates instruction features into the planner - Learnable adaptive gate balances guidance influence between LLM instruction features and direct scene processing - Compatible with any transformer-based planner backbone
Asynchronous Strategy: - LLM computes instruction features at longer intervals (every N frames) - Real-time planner processes every frame, reusing cached instruction features - High-level driving instructions remain consistent over short periods, validating sparse updates
Results
| Method | nuPlan Hard20 Score | vs. Baseline |
|---|---|---|
| GameFormer | 62.05 | -- |
| AsyncDriver | 65.00 | +4.6% |
| PDM-Hybrid | 64.05 | -- |
| AsyncDriver* (w/ PDM scorer) | 67.48 | +5.3% |
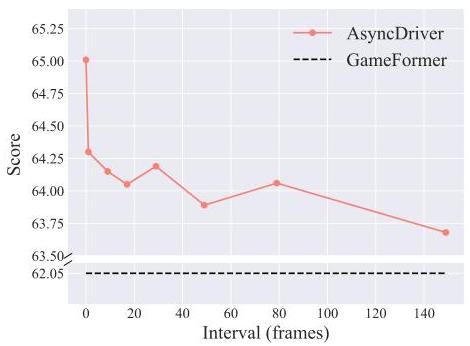
| LLM Frequency | Score | Time Reduction |
|---|---|---|
| Every frame | 65.00 | 0% |
| Every 3 frames | ~64.0 | ~40% |
| Every 149 frames | >63.1 | ~99% |
Instruction following demonstrated: vehicle responds to "stop" command by reducing speed from 10.65 m/s to 1.06 m/s within 6 seconds. Drivable area compliance improved by 3.23 points over GameFormer.
Limitations
- Evaluated only on nuPlan closed-loop; generalization to CARLA or real-world settings untested
- Llama2-13B is still large for deployment; distillation to smaller LLMs not explored
- Asynchronous caching assumes instruction features remain valid across frames -- may fail in rapidly changing scenarios (sudden obstacles, emergency situations)
- Vectorized scene input requires a perception pipeline; not end-to-end from raw sensors
Connections
- Related to Senna Bridging Large Vision Language Models And End To End Autonomous Driving in decoupling LLM reasoning from trajectory generation, but AsyncDriver also decouples temporally
- Addresses the latency problem identified in Foundation Models as a key open problem for deploying large models in driving
- Complements Dima Distilling Multi Modal Large Language Models For Autonomous Driving which solves the efficiency problem by distilling the LLM away entirely, while AsyncDriver keeps the LLM but runs it asynchronously
- Evaluated on nuPlan closed-loop, connecting to the evaluation standards discussed in Planning
- Autonomous Driving -- practical LLM deployment for driving