Overview
DiMA addresses the core tension in autonomous driving between vision-based planners (efficient but fragile on rare scenarios) and LLM-based approaches (strong reasoning but prohibitively expensive at inference). Rather than choosing one paradigm, DiMA bridges them through knowledge distillation: it jointly trains a vision-based planner alongside a multi-modal LLM, then discards the LLM at inference time, retaining only the efficient planner that has absorbed the LLM's reasoning capabilities.
The key innovation is joint training rather than post-hoc distillation. The vision-based scene encoder is trained simultaneously with the MLLM through four tasks: visual question answering, trajectory estimation, KL-divergence-based knowledge distillation, and three surrogate tasks (masked token reconstruction, future token prediction, and scene editing). The BEAM token representation structures the scene into BEV, ego-vehicle, agent, and map components, providing explicit modeling of driving scene elements.
DiMA achieves 37% reduction in L2 trajectory error, 80% reduction in collision rate, and 44% improvement in long-tail scenarios compared to vision-only baselines on nuScenes. Critically, at inference the system runs as a lightweight vision planner with no LLM overhead.
Key Contributions
- Joint training framework that distills MLLM reasoning into a vision planner during training, discarding the LLM at inference for zero additional cost
- BEAM token structured representation (BEV + Ego + Agent + Map) providing explicit scene decomposition for distillation
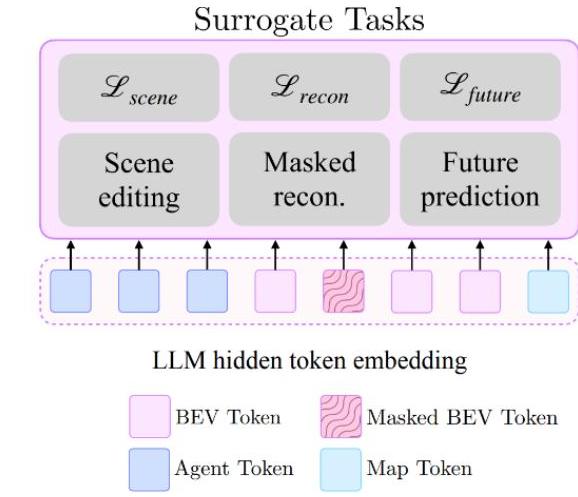
- Three surrogate tasks that enhance representation learning: masked token reconstruction, future token prediction, and counterfactual scene editing
- 80% collision rate reduction and 44% improvement on long-tail scenarios (overtaking, three-point turns) vs vision-only baselines
- Demonstrates that the efficiency-vs-reasoning tradeoff can be resolved through distillation rather than architectural compromise
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ DiMA Training Framework │
│ │
│ Multi-view ┌─────────────────────────────────┐ │
│ Cameras ───────►│ Vision Scene Encoder │ │
│ │ (produces BEAM tokens) │ │
│ │ B=BEV E=Ego A=Agent M=Map │ │
│ └──────────┬──────────────┬────────┘ │
│ │ │ │
│ ┌────────────────┘ └──────────────┐ │
│ ▼ ▼ │
│ ┌─────────────────────┐ KL divergence ┌──────────────────┐ │
│ │ Planning Transformer│◄──────────────►│ LLaMA-v1.5 7B │ │
│ │ (lightweight) │ distillation │ (MLLM Teacher) │ │
│ │ │ │ │ │
│ │ Task: trajectory │ │ Tasks: │ │
│ │ estimation │ │ - VQA │ │
│ │ │ │ - Trajectory est.│ │
│ │ │ │ - Surrogate: │ │
│ │ │ │ · Masked recon │ │
│ │ │ │ · Future pred │ │
│ │ │ │ · Scene edit │ │
│ └──────────┬───────────┘ └──────────────────┘ │
│ │ ✕ │
│ ▼ (discarded at │
│ Planned Trajectory inference) │
│ ┌─────────────────────┐ │
│ │ INFERENCE ONLY: │ │
│ │ Encoder + Planner │ ◄── No LLM overhead at deploy time │
│ └─────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
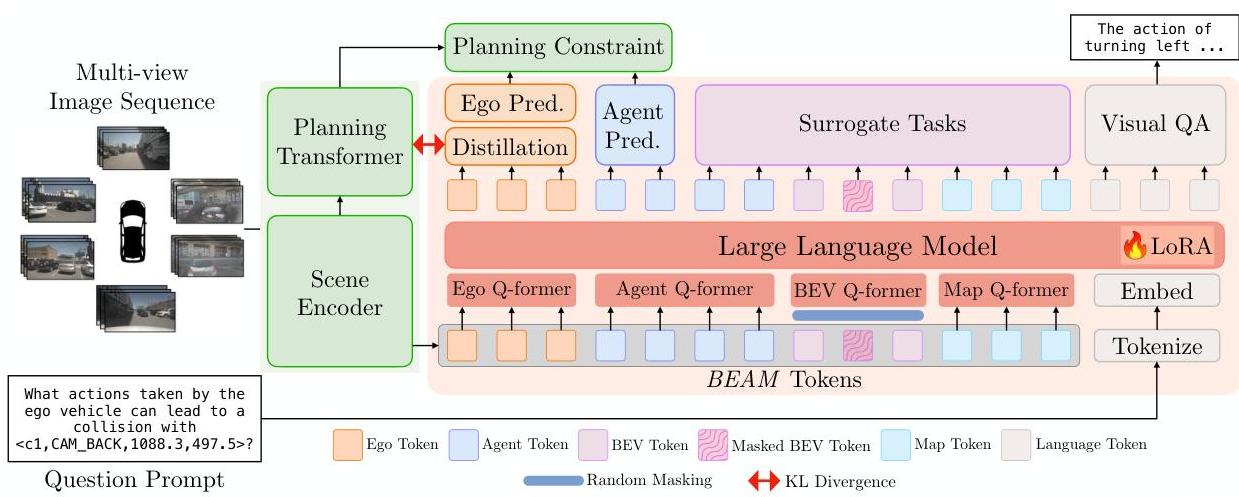
The framework has two components during training:
Vision-Based Planner (retained at inference): - Scene encoder producing structured BEAM tokens - Planning transformer for trajectory generation
Multi-Modal LLM (discarded at inference): - LLAMA-v1.5-7B processing structured BEAM representations - Handles four training objectives:
- Visual Question Answering: Scene understanding through language
- Trajectory Estimation: Direct planning supervision
- Knowledge Distillation: KL divergence minimization between MLLM and planner hidden features, aligning internal representations
- Surrogate Tasks: - Masked token reconstruction: Reconstruct randomly masked BEAM tokens (forces robust encoding) - Future token prediction: Forecast future scene states (temporal reasoning) - Scene editing: Add/remove agents to teach counterfactual reasoning about hypothetical scenarios
BEAM Token Structure: - BEV tokens: map and spatial layout - Ego tokens: autonomous vehicle state - Agent tokens: surrounding dynamic objects - Map tokens: additional road elements
Training uses AdamW optimizer on 8x NVIDIA A100 GPUs with nuScenes and DriveLM datasets.
Results
nuScenes Planning Benchmark
| Model | Type | L2 Error (m) | Collision Rate (%) |
|---|---|---|---|
| UniAD | Vision E2E | -- | -- |
| VAD | Vision E2E | baseline | baseline |
| PARA-Drive | LLM-based | -- | -- |
| TOKEN-Drive | LLM-based | -- | -- |
| DiMA | Distilled | -37% vs VAD | -80% vs VAD |
Long-Tail Scenarios
| Scenario | DiMA L2 (m) | VAD L2 (m) | Improvement |
|---|---|---|---|
| Overtaking | 0.66 | 1.06 | -37.7% |
| Three-point turn | 1.05 | 1.57 | -33.1% |
| Overall long-tail | -- | -- | -44% |
DiMA also demonstrates VQA capabilities enabling language-guided scene reasoning, improving interpretability and allowing users to query system decisions -- though this requires the MLLM to be present (inference-time option for debugging).
Limitations & Open Questions
- The distillation framework requires training with a full 7B MLLM, increasing training cost even though inference is cheap -- this limits rapid iteration
- Evaluated on nuScenes open-loop metrics only; closed-loop evaluation would better validate the long-tail improvements
- Whether the BEAM token decomposition generalizes beyond nuScenes-style urban driving (e.g., highway, rural, construction zones) is untested
Connections
- Vad Vectorized Scene Representation For Efficient Autonomous Driving -- VAD baseline; DiMA achieves 37% L2 reduction and 80% collision reduction
- Planning Oriented Autonomous Driving -- UniAD baseline for E2E planning comparison
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving -- Alternative LLM-planner coupling: Senna decouples at inference, DiMA distills and discards
- Drivelm Driving With Graph Visual Question Answering -- DriveLM dataset used for VQA training; similar structured reasoning philosophy
- Drivevlm The Convergence Of Autonomous Driving And Large Vision Language Models -- DriveVLM keeps the VLM at inference; DiMA shows distillation can avoid this cost
- Learning By Cheating -- Conceptual ancestor: privileged distillation (expert with GT access distilled to student); DiMA extends this to LLM-to-planner distillation