VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Overview
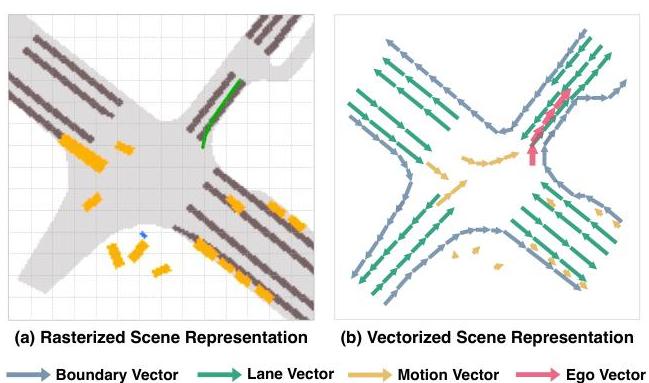
VAD (Vectorized Scene Representation for Efficient Autonomous Driving) by Jiang et al. (ICCV 2023) is a pivotal paper in the shift from dense rasterized scene representations to vectorized representations for end-to-end autonomous driving. Traditional approaches encode the driving scene as dense BEV occupancy grids or rasterized maps, which are computationally expensive and contain redundant information. VAD instead represents the scene as a set of vectorized elements -- map polylines, agent trajectories, and ego planning queries -- and uses attention mechanisms to reason over these structured representations.
The core argument is that vectorized representations are both more efficient and more informative for planning than dense grids. Map elements (lane boundaries, crosswalks) are naturally polylines, not pixel grids. Agent motions are trajectories, not occupancy maps. By representing them in their natural form and using transformer attention to model interactions, VAD achieves better planning performance with significantly lower computational cost than dense alternatives.
VAD became a strong baseline and reference point for the vectorized end-to-end driving paradigm, demonstrating that the field could move beyond the "rasterize everything" approach that dominated early BEV-based driving systems. VAD explicitly improves upon UniAD (CVPR 2023), which was the prior state-of-the-art, rather than influencing it. The paper represents an important counterpoint to occupancy-heavy approaches and showed that structured, sparse representations can outperform dense ones for planning.
Key Contributions
- Fully vectorized scene representation for planning: Represents map elements as ordered polyline vectors, agent states as trajectory vectors, and ego planning as learnable query vectors, eliminating the need for dense rasterized BEV grids
- Vectorized map and agent encoding: Map elements (lane boundaries, crosswalks, road edges) are encoded as sequences of 2D points forming polylines; agent histories and futures are encoded as trajectory point sequences
- Query-based planning with vectorized scene context: Ego planning queries attend to vectorized map and agent representations via cross-attention, enabling structured reasoning about lane following, obstacle avoidance, and traffic rule compliance
- Vectorized scene constraints: Introduces three instance-level planning constraints: (1) ego-agent collision constraint with longitudinal and lateral safety thresholds, (2) ego-boundary overstepping constraint that keeps the ego within drivable areas using predicted road boundary vectors, and (3) ego-lane directional constraint that encourages alignment between planned trajectory segments and lane vector directions
- Computational efficiency: Achieves better performance than dense BEV approaches while being significantly faster, since vectorized representations scale with the number of scene elements rather than spatial resolution
Architecture
┌──────────────────────────────────────────────────────────┐
│ VAD Pipeline │
│ │
│ Multi-camera Images (6 views) │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ Image Backbone│ (ResNet-50) │
│ └──────┬───────┘ │
│ ▼ │
│ ┌──────────────┐ │
│ │ BEV Encoder │ (LSS / BEVFormer) │
│ │ Dense BEV Map│ │
│ └──────┬───────┘ │
│ │ │
│ ┌────┴────────────────────────┐ │
│ │ Cross-Attention │ │
│ ▼ ▼ ▼ │
│ ┌──────┐ ┌──────────┐ ┌──────────┐ │
│ │ Map │ │ Agent │ │ Ego │ │
│ │Queries│ │ Queries │ │ Planning │ │
│ └──┬───┘ └────┬─────┘ │ Queries │ │
│ │ │ └────┬─────┘ │
│ ▼ ▼ │ │
│ Polylines Agent Traj. │ Cross-Attn to │
│ (lanes, (future │ map & agent vectors │
│ edges) positions) ▼ │
│ │ │ ┌──────────┐ │
│ │ └────────►│ Planning │ │
│ └─────────────────────►│ Head │ │
│ └────┬─────┘ │
│ Constraint Losses: ▼ │
│ ├─ Collision avoidance Ego Trajectory │
│ ├─ Road boundary (2D waypoints) │
│ └─ Lane direction │
└──────────────────────────────────────────────────────────┘
Architecture / Method
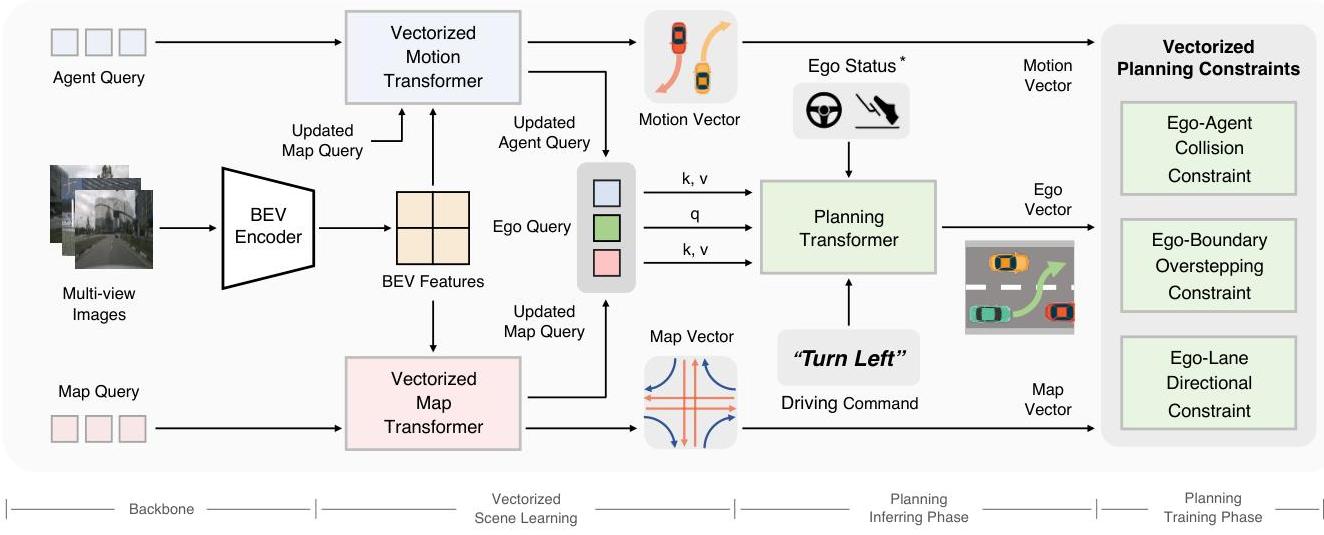
VAD's architecture consists of three main stages. Stage 1 -- BEV Feature Extraction: Multi-camera images are encoded by a backbone (ResNet-50 or similar) and lifted to BEV space using a standard BEV encoder (LSS or BEVFormer-style). This produces a dense BEV feature map as an intermediate representation.
Stage 2 -- Vectorized Scene Encoding: Instead of using the dense BEV features directly for planning, VAD extracts vectorized representations. Map elements are detected as polylines using a set of learnable map queries that attend to the BEV features via cross-attention. Each map query predicts a polyline (ordered sequence of 2D BEV points) and a semantic class (lane boundary, crosswalk, road edge). Similarly, agent queries attend to BEV features and predict agent trajectories (position sequences over future timesteps).
Stage 3 -- Vectorized Planning: A set of ego planning queries attend to the vectorized map and agent representations via cross-attention. The planning module produces a future ego trajectory (sequence of 2D waypoints). Two key constraint losses are applied: (1) a map-aware loss that penalizes the planned trajectory for deviating from detected lane polylines, and (2) an agent-aware loss that penalizes the planned trajectory for coming too close to predicted agent trajectories. These constraints inject structured driving knowledge without hardcoding rules.
The entire pipeline is trained end-to-end with losses on map detection (polyline regression + classification), agent prediction (trajectory regression), and ego planning (waypoint L2 + constraint losses).
Results
Open-Loop nuScenes Performance
| Method | Planning L2 (m) | Collision Rate | Inference Speed |
|---|---|---|---|
| UniAD | 1.03 | 0.31% | 1.8 FPS |
| VAD-Base | 0.72 | 0.22% | 4.5 FPS |
| VAD-Tiny | ~0.75 | ~0.25% | 16.8 FPS |
- State-of-the-art on nuScenes planning benchmark at the time of publication: 30.1% improvement in planning displacement error (1.03m down to 0.72m) and 29.0% reduction in collision rate (0.31% down to 0.22%) over prior best methods
- Significant efficiency gains: 2.5x faster inference than UniAD (4.5 FPS vs 1.8 FPS) due to the sparse vectorized representation. VAD-Tiny variant achieves 9.3x speedup while maintaining comparable performance. The planning module itself requires only 5.7% of total inference time
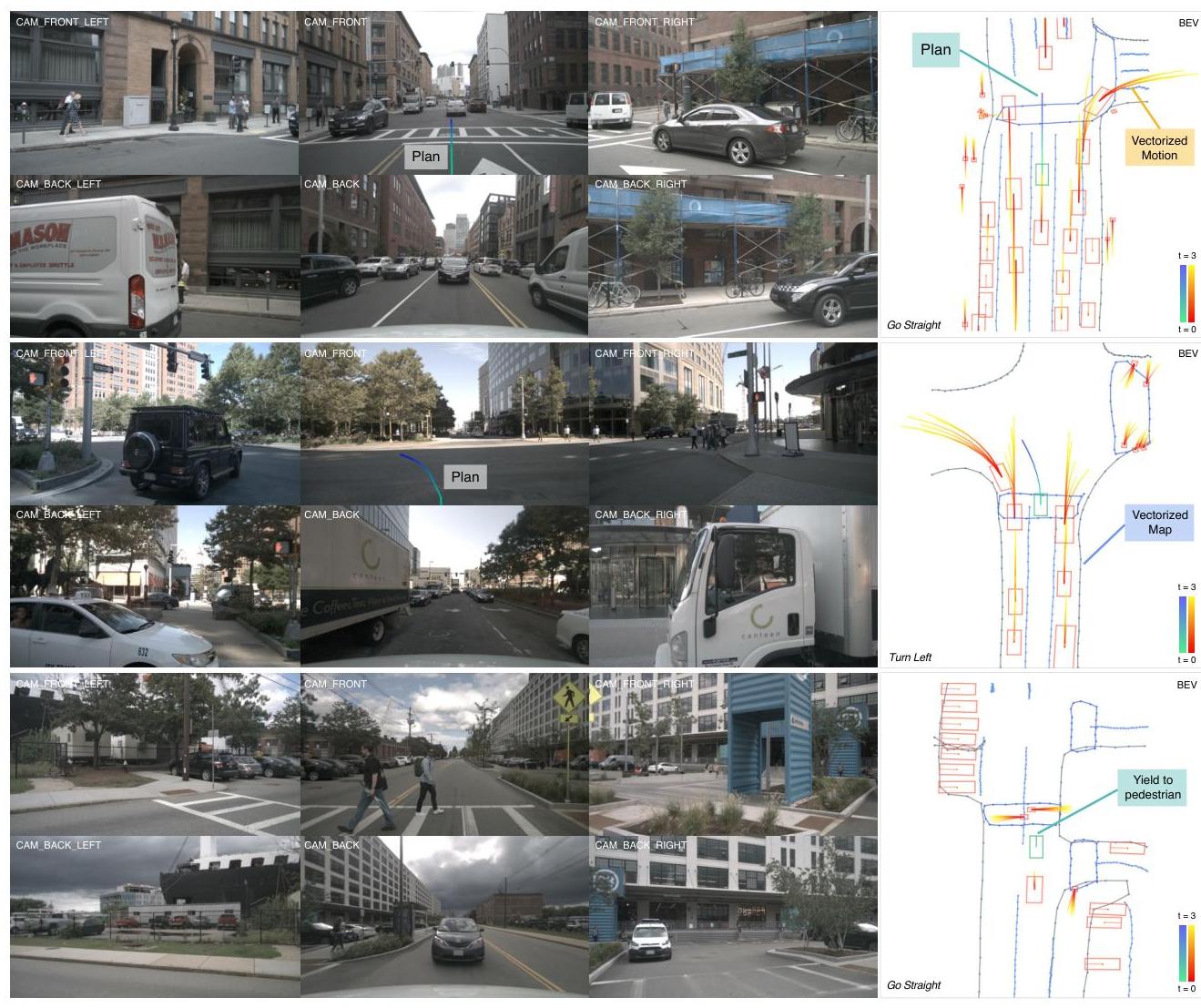
- Closed-loop CARLA performance: On Town05 Long benchmark, achieves Driving Score of 30.31 with 75.20% route completion, demonstrating robust closed-loop behavior for a vision-only method
- Vectorized constraints improve safety: Adding map-aware and agent-aware planning losses reduces collision rate by 20-30% compared to unconstrained planning, demonstrating the value of structured scene knowledge
- Strong map detection performance: The vectorized map prediction achieves competitive mAP with dedicated map detection methods, showing that the representation is not just efficient but accurate
- Ablation validates vectorized over dense: Replacing the vectorized planning module with a dense BEV planning head degrades performance, confirming that vectorized representations provide a better inductive bias for driving
- Generalizes to different backbones and BEV encoders: The vectorized planning framework works with multiple choices of image backbone and BEV lifting strategy
Limitations & Open Questions
- Open-loop evaluation on nuScenes does not capture closed-loop driving challenges (compounding errors, reactive agents), limiting the conclusions that can be drawn about real driving performance
- Vectorized map detection depends on the quality of the BEV feature extraction stage; errors in BEV encoding propagate to map polylines and then to planning
- The approach assumes that scene elements can be cleanly decomposed into polylines and trajectories, which may not capture complex scenarios like construction zones, unusual road geometries, or non-standard traffic participants
- No language or reasoning component -- the planner operates purely on geometric and dynamic scene structure
Connections
- Vadv2 End To End Vectorized Autonomous Driving Via Probabilistic Planning -- direct successor, replaces deterministic planner with probabilistic action vocabulary
- Planning
- End To End Architectures
- Autonomous Driving
- Vectornet Encoding Hd Maps And Agent Dynamics From Vectorized Representation
- Wote End To End Driving With Online Trajectory Evaluation Via Bev World Model
- Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving