TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
Overview
TransFuser (Chitta et al., 2022) is a foundational paper for transformer-based sensor fusion in end-to-end autonomous driving. The key problem it addresses is how to effectively combine information from cameras and LiDAR for driving: prior approaches either processed each modality independently and fused late (losing cross-modal interactions) or used simple concatenation (ignoring the geometric relationship between modalities). TransFuser uses transformer self-attention to fuse image and LiDAR features at multiple resolutions within the encoder, enabling rich cross-modal reasoning.
The architecture demonstrates that attention-based fusion substantially outperforms both late fusion and simple concatenation approaches on the CARLA closed-loop driving benchmark. By applying transformers at intermediate layers of the ResNet backbone (not just at the output), TransFuser captures fine-grained cross-modal correspondences -- for example, relating the visual appearance of a distant vehicle to its precise 3D position in the LiDAR point cloud. This multi-scale fusion is critical for driving, where both local details (traffic light color) and global context (intersection layout) matter.
TransFuser became one of the most referenced baselines for CARLA-based end-to-end driving research. Its design philosophy -- that cross-modal attention at multiple scales is essential for driving -- influenced subsequent work including InterFuser, TCP, and the broader shift toward attention-based perception-planning architectures in autonomous driving.
Key Contributions
- Multi-scale transformer fusion: Applies transformer self-attention to fuse image and LiDAR features at multiple intermediate resolutions of the encoder backbone, not just at the final feature level
- Cross-modal attention for driving: Demonstrates that attention-based fusion outperforms late fusion and concatenation by learning which cross-modal correspondences are relevant for driving decisions
- Strong CARLA closed-loop baseline: Establishes a competitive and reproducible baseline on the CARLA Leaderboard that subsequent papers consistently compare against
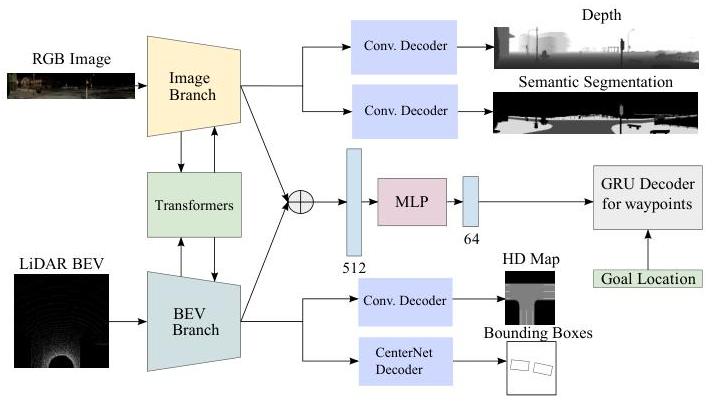
- Multi-task learning framework: Uses auxiliary supervision including depth estimation, BEV semantic segmentation, HD map prediction, and vehicle detection (2D bounding boxes) to regularize the learned representations and improve driving performance
- Latent TransFuser variant: Provides a strong image-only baseline that surpasses reinforcement learning-based image-only methods, establishing new performance standards for camera-only driving
- Imitation learning with geometric reasoning: Shows that transformer attention can implicitly learn geometric correspondences between 2D image features and 3D LiDAR features without explicit geometric projection
Architecture
┌─────────────────────────────────────────────────────────────────┐
│ TransFuser Pipeline │
│ │
│ RGB Image LiDAR BEV │
│ │ │ │
│ ┌──▼──┐ ┌──▼──┐ │
│ │RegNet│ │RegNet│ │
│ │Blk 1 │ │Blk 1 │ │
│ └──┬──┘ └──┬──┘ │
│ │ ┌────────────┐ │ │
│ └───►│ Transformer ◄──┘ (Scale 1: high res) │
│ ┌────┤ Fusion ├───┐ │
│ ┌──▼──┐ └────────────┘┌──▼──┐ │
│ │RegNet│ │RegNet│ │
│ │Blk 2 │ │Blk 2 │ │
│ └──┬──┘ └──┬──┘ │
│ │ ┌────────────┐ │ │
│ └───►│ Transformer ◄──┘ (Scale 2: mid res) │
│ ┌────┤ Fusion ├───┐ │
│ ┌──▼──┐ └────────────┘┌──▼──┐ │
│ │RegNet│ │RegNet│ │
│ │Blk 3 │ │Blk 3 │ │
│ └──┬──┘ └──┬──┘ │
│ │ ┌────────────┐ │ │
│ └───►│ Transformer ◄──┘ (Scale 3: low res) │
│ │ Fusion │ │
│ └─────┬───────┘ │
│ │ Fused features │
│ ┌─────▼───────┐ │
│ │ GRU Waypoint│ │
│ │ Predictor │──► Waypoints ──► PID ──► Steer/Accel │
│ └─────────────┘ │
│ │
│ Auxiliary: BEV Seg │ Depth Est │ HD Map │ Vehicle Det │
└─────────────────────────────────────────────────────────────────┘
Architecture / Method
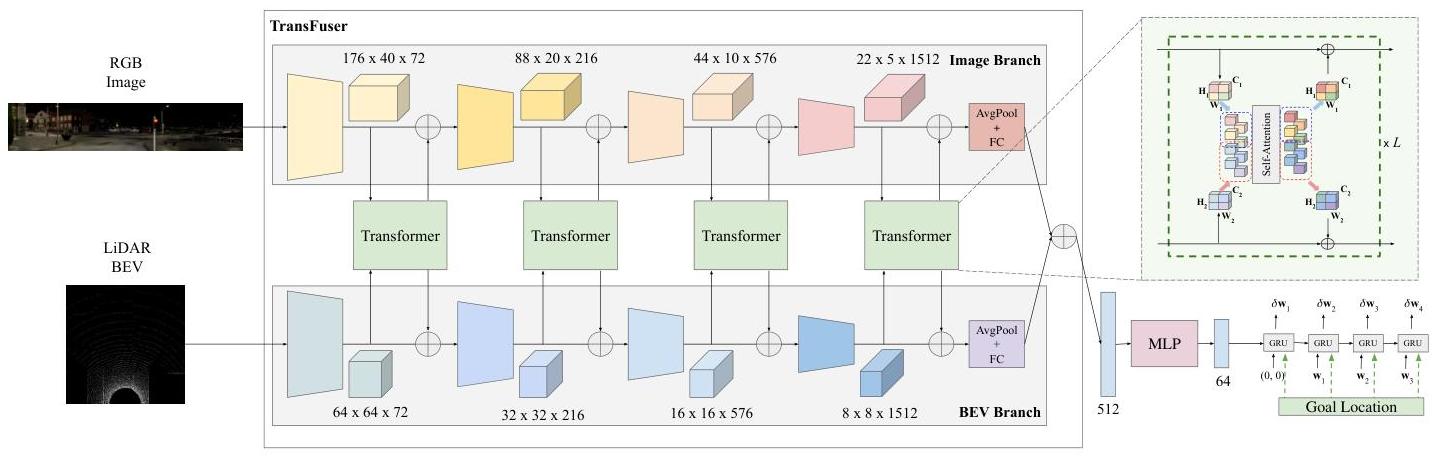
TransFuser processes two input streams: front-facing RGB camera images and LiDAR BEV (bird's eye view) representations. Both are encoded by separate RegNetY-3.2GF backbones (the image branch is pretrained on ImageNet; the LiDAR BEV branch is trained from scratch). At multiple intermediate stages of the backbone (after each ResNet block), the spatial features from both modalities are flattened into token sequences and fed into a transformer module that performs cross-attention between image tokens and LiDAR tokens.
Specifically, at each scale s, the image features F_img^s (shape H_s x W_s x C_s) and LiDAR features F_lid^s (shape H_s' x W_s' x C_s) are projected to a common dimension, flattened into token sequences, and concatenated. A transformer encoder (2-4 layers, multi-head self-attention) processes this combined sequence, allowing image tokens to attend to LiDAR tokens and vice versa. The output tokens are split back into their respective modalities and reshaped to spatial feature maps, which are passed to the next backbone stage.
The fused features from the final backbone stage are passed through a GRU-based waypoint prediction head that autoregressively generates a sequence of future waypoints. These waypoints are converted to steering, throttle, and brake commands via a PID controller. Auxiliary losses on BEV semantic segmentation and depth prediction from the intermediate features regularize the learned representations.
Training uses expert demonstrations collected from a privileged CARLA autopilot. The primary loss is L2 on predicted waypoints, combined with cross-entropy for semantic segmentation and L1 for depth estimation.
Results


- State-of-the-art on CARLA Leaderboard (at time of publication): Significantly outperforms prior methods including CILRS, LBC, and single-modality baselines on both driving score and route completion metrics. Outperforms on both the Longest6 benchmark and the official CARLA leaderboard
- Multi-scale fusion outperforms single-scale: Ablations show that applying transformer fusion at multiple backbone stages (early + middle + late) outperforms fusion at only the final stage, confirming the importance of multi-resolution cross-modal reasoning
- Cross-modal attention outperforms concatenation: Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%. Transformer-based fusion achieves 15-20% higher driving scores than simple feature concatenation or late fusion approaches
- Auxiliary tasks improve driving: Adding BEV segmentation and depth prediction losses improves driving performance by 10-15%, acting as useful regularizers that encourage geometrically meaningful feature representations
- Robust closed-loop performance: The model handles complex scenarios including intersections, lane changes, and yielding to pedestrians in the CARLA simulator
- Reproducible baseline: The codebase became widely used by the CARLA research community
Limitations & Open Questions
- LiDAR dependency limits deployment on camera-only platforms, and the model does not gracefully degrade when LiDAR is unavailable
- CARLA-based evaluation does not guarantee real-world performance due to the sim-to-real gap in visual fidelity, traffic behavior, and sensor characteristics
- The PID controller for waypoint-to-control conversion introduces a non-learned bottleneck that can cause jerky driving at high speeds or in tight maneuvers
- No language or reasoning component -- purely a perception-to-action pipeline without any semantic understanding or explainability