Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving
Overview
Think Twice (Jia et al., 2023) addresses a fundamental imbalance in end-to-end autonomous driving: while the community has invested heavily in sophisticated encoders for sensor processing, the decoder side -- which actually produces driving plans -- has remained surprisingly simple. Most prior E2E systems use a lightweight MLP or single-step GRU to convert learned features into waypoints, leaving significant room for improvement. The paper argues that "thinking twice" -- iteratively refining predictions through a cascaded decoder -- is key to robust planning, drawing an analogy to how human drivers mentally simulate and revise their intended trajectory before acting.
The core contribution is a scalable, cascaded decoder architecture with two novel modules: a Look Module that retrieves spatial-conditioned features from the BEV representation based on a coarse initial prediction, and a Prediction Module that anticipates future scene evolution conditioned on the current action plan using a spatial-GRU. These two modules are stacked into decoder layers that iteratively refine the trajectory, similar in spirit to how DETR-style decoders refine object detections through cascaded cross-attention. Dense intermediate supervision at every decoder layer (including expert feature distillation and teacher-forcing on future predictions) ensures that each refinement step is well-grounded.
The framework achieved state-of-the-art results on the CARLA Town05 Long benchmark with a Driving Score of 65.0% (standard setting) and 70.9% (with extra data), substantially outperforming prior methods including TransFuser, TCP, and MILE. Critically, the paper demonstrates clear scalability: stacking more decoder layers improves performance from a TCP-Head baseline of 59.3 DS to 61.6 DS with 1 decoder layer and 65.0 DS with 5 decoder layers, establishing that decoder depth is a meaningful scaling axis for E2E driving -- a finding that challenges the prevailing "encoder-heavy, decoder-light" design paradigm.
Key Contributions
- Cascaded decoder architecture for E2E driving: Proposes iterative trajectory refinement through stacked decoder layers, demonstrating that decoder sophistication matters as much as encoder design
- Look Module: A spatial-conditioned feature retrieval mechanism that uses coarse waypoint predictions to index relevant BEV features, providing trajectory-aware context for refinement
- Prediction Module: An action-conditioned future scene anticipation module using spatial-GRU that predicts how the scene will evolve given the current plan, enabling the decoder to reason about consequences of actions
- Dense decoder supervision: Each decoder layer receives independent supervision including waypoint loss, expert feature distillation, and teacher-forced future prediction, ensuring stable training of deep cascaded decoders
- Scalability evidence: Clear empirical demonstration that stacking decoder layers monotonically improves driving performance, establishing decoder depth as a viable scaling axis
Architecture / Method
ThinkTwice: Cascaded Decoder for E2E Driving
Multi-Camera + LiDAR
│
▼
┌──────────────────┐
│ BEV Encoder │ (ResNet+LSS for camera; SECOND for LiDAR)
└────────┬─────────┘
│
▼ BEV Features
┌──────────────────┐
│ Coarse Prediction │ ──► Waypoints_0 (initial rough trajectory)
└────────┬─────────┘
│
┌───────▼────────────────────────────────────────┐
│ Decoder Layer (x5) │
│ │
│ Waypoints_i ──► ┌─────────────┐ │
│ │ Look Module │ Deformable attn│
│ │ (multi-scale │ around traj │
│ │ deformable │ reference pts │
│ │ attention) │ │
│ └──────┬──────┘ │
│ │ │
│ Waypoints_i ──► ┌──────▼──────┐ │
│ │ Prediction │ Anticipate │
│ │ Module │ future scene │
│ │ (Spatial-GRU)│ evolution │
│ └──────┬──────┘ │
│ │ │
│ ┌──────▼──────┐ │
│ │ Refined │ │
│ │ Prediction │ ──► Waypoints_{i+1}
│ └─────────────┘ │
│ Dense supervision at each layer (L1/L2 + distill) │
└─────────────────────────────────────────────────┘
│
▼
Final Trajectory (Waypoints_5)
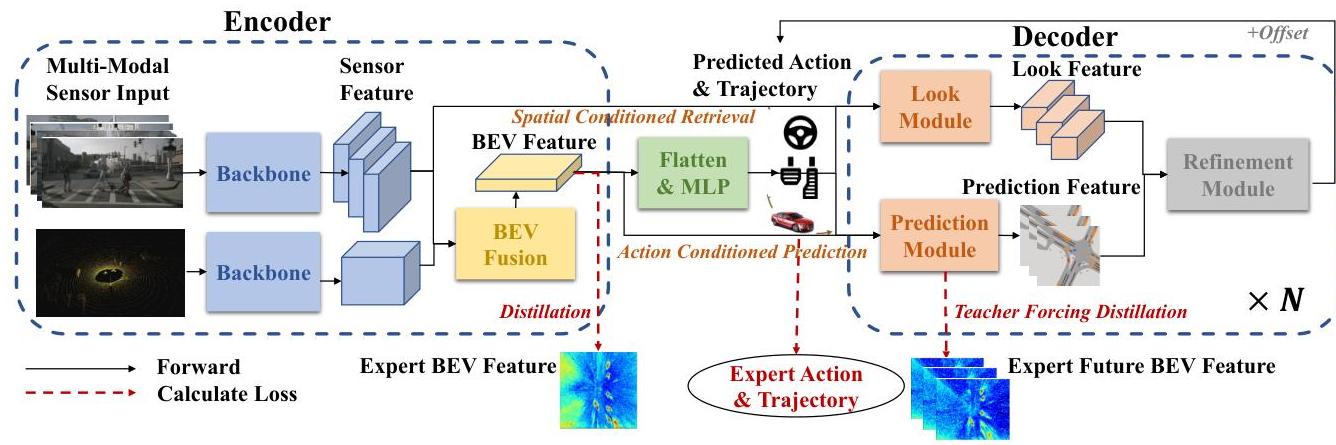
The Think Twice architecture follows a standard encoder-decoder paradigm but with a substantially redesigned decoder. The encoder processes multi-camera images and LiDAR to produce a BEV feature representation: camera features are extracted via a ResNet backbone and projected to BEV using the Lift-Splat-Shoot (LSS) method; LiDAR features are generated by the SECOND network. The key innovation is entirely in the decoder.
Cascaded Decoder Pipeline:
- Coarse Prediction: An initial lightweight head produces a rough trajectory estimate from the BEV features
- Look Module: Given the coarse waypoints, the module projects the predicted trajectory coordinates back to the image planes and uses multi-scale deformable attention to aggregate visual information around those reference points (and retrieves surrounding voxel features for LiDAR). This provides spatially-relevant context -- the decoder "looks" at where it plans to drive
- Prediction Module: A spatial-GRU takes the current plan and BEV features to predict future BEV states, simulating how the scene will evolve if the ego vehicle follows the proposed trajectory. This enables the model to anticipate collisions or unsafe situations before committing to the plan
- Refined Prediction: The retrieved spatial features and predicted future features are combined to produce an updated trajectory
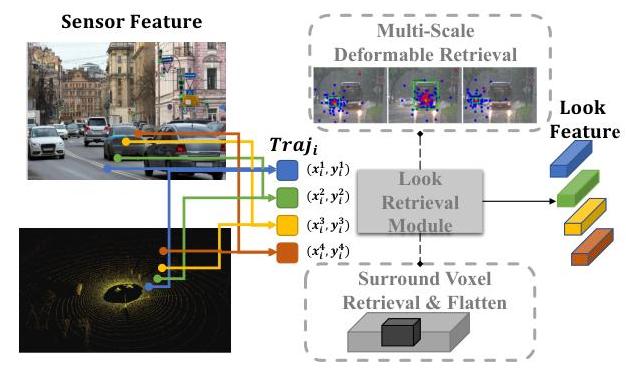
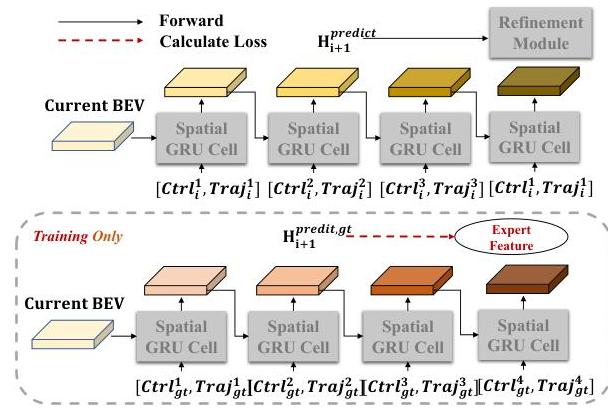
Steps 2-4 form one decoder layer, and multiple such layers are stacked (typically 5). Each layer refines the trajectory from the previous layer, with the Look Module re-sampling BEV features based on the updated trajectory and the Prediction Module re-simulating future consequences. Dense supervision is applied at every layer: each layer's trajectory prediction is independently supervised with L1/L2 waypoint loss, and the Prediction Module receives teacher-forcing supervision by comparing its predicted future BEV to actual future BEV features from an expert model.
Training Details: - Expert feature distillation from a privileged agent provides BEV feature targets - Teacher-forcing on the Prediction Module ensures it learns accurate future scene prediction - All decoder layers share weights (parameter efficient) or use independent weights (higher capacity) - The system is trained end-to-end with combined losses across all decoder layers
Results

The primary evaluation is on the CARLA Town05 Long benchmark under closed-loop driving conditions:
| Method | Driving Score | Route Completion | Infraction Score |
|---|---|---|---|
| ThinkTwice (extra data) | 70.9 | 95.5 | 74.3 |
| ThinkTwice (standard) | 65.0 | 95.5 | -- |
| Interfuser* | 68.3 | -- | -- |
| MILE* | 61.1 | -- | -- |
| TCP | 57.2 | 84.5 | 67.7 |
| TransFuser | 54.5 | 78.4 | 73.1 |
| LAV | 46.0 | 64.9 | 71.3 |
| LBC | 30.1 | 55.0 | 57.5 |
Scalability ablation (decoder layers):
| Decoder Layers | Driving Score |
|---|---|
| 0 (TCP-Head baseline) | 59.3 |
| 1 | 61.6 |
| 5 | 65.0 |
Key findings: - Monotonic improvement with decoder depth confirms scalability of the cascaded approach - The Look Module alone contributes roughly +5 DS by providing trajectory-conditioned spatial features - The Prediction Module adds another +3-4 DS by enabling future consequence reasoning - Dense per-layer supervision is critical -- removing it causes training instability with deeper decoders - The model shows particularly strong safety metrics (low infraction rate), suggesting that the "think twice" mechanism effectively avoids collisions
Limitations & Open Questions
- Evaluation is exclusively on CARLA simulation -- no real-world driving results are provided
- The expert distillation requirement means a privileged agent must be available during training, limiting applicability to simulation settings where such an oracle exists
- Computational cost scales linearly with decoder depth; inference latency for 5 decoder layers may be challenging for real-time deployment
- The BEV encoder is largely inherited from prior work -- the paper does not explore how encoder-decoder co-design might yield further gains
- Open question: does the iterative refinement paradigm transfer to real-world driving where BEV features are noisier and expert distillation is unavailable?
Connections
Related papers in the wiki: - Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving -- ThinkTwice builds on TransFuser's BEV encoder and substantially outperforms it - Planning Oriented Autonomous Driving -- UniAD similarly proposes a structured planning pipeline; ThinkTwice focuses specifically on decoder refinement - Learning By Cheating -- The expert distillation paradigm used for training the Prediction Module - Vad Vectorized Scene Representation For Efficient Autonomous Driving -- Another jointly-trained E2E system; ThinkTwice's cascaded decoder is a complementary architectural direction - End To End Driving Via Conditional Imitation Learning -- Foundational conditional IL that ThinkTwice extends - Carla An Open Urban Driving Simulator -- Primary evaluation benchmark - Genad Generative End To End Autonomous Driving -- Related decoder-focused approach using generative trajectory modeling - Diffusiondrive Truncated Diffusion Model For End To End Autonomous Driving -- Alternative iterative refinement via diffusion denoising - Planning -- Cascaded trajectory refinement as a planning paradigm - End To End Architectures -- Type 3 jointly trained modular E2E system - Autonomous Driving -- Broader driving context