GenAD: Generative End-to-End Autonomous Driving
Overview
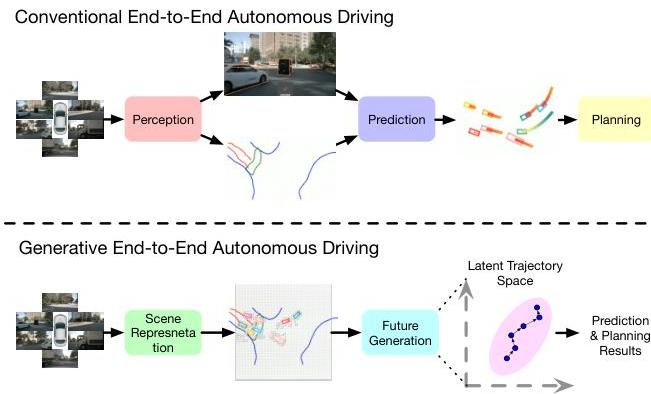
GenAD (ECCV 2024) reframes end-to-end autonomous driving as a generative modeling problem, simultaneously generating future trajectories for all traffic participants rather than following the traditional sequential perception-prediction-planning pipeline. The core insight is that jointly modeling ego and agent trajectories in a shared latent space captures interactions more naturally than cascaded modules.
The framework uses instance-centric scene representations with map-aware tokens, a VAE-based trajectory prior model that captures the structural properties of realistic vehicle trajectories, and a GRU-based temporal decoder for progressive waypoint generation. GenAD achieves state-of-the-art L2 displacement error of 0.91m, collision rate of 0.43%, and runs at 6.7 FPS on an RTX 3090.
Key Contributions
- Generative driving paradigm: Recasts E2E driving as joint generative modeling of all agent trajectories rather than sequential perception-then-planning
- Instance-centric scene representation: Map-aware instance tokens with self-attention for ego-agent interaction modeling, replacing dense BEV grid representations
- Trajectory prior via VAE: Learns a latent prior that captures structural properties of realistic vehicle trajectories (smoothness, kinematic feasibility), providing strong inductive bias for generation
- Progressive waypoint decoding: GRU-based temporal model generates trajectories step-by-step, enabling autoregressive refinement at each timestep
- State-of-the-art planning: 0.91m L2 (best), 0.43% collision rate on nuScenes at time of publication
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ GenAD: Generative E2E Autonomous Driving │
│ │
│ Multi-Camera Images │
│ │ │
│ ▼ │
│ ┌──────────────┐ ┌──────────────────────────────┐ │
│ │ Backbone + │ │ Instance-Centric Tokens │ │
│ │ BEV Encoder │──►│ ┌─────┐ ┌───────┐ ┌──────┐ │ │
│ └──────────────┘ │ │ Map │ │ Agent │ │ Ego │ │ │
│ │ │Tokens│ │Tokens │ │Token │ │ │
│ │ └──┬──┘ └───┬───┘ └──┬───┘ │ │
│ │ └────┬───┘────────┘ │ │
│ │ ▼ │ │
│ │ Self-Attention │ │
│ │ (ego-agent-map interaction)│ │
│ └──────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Trajectory VAE │ │
│ │ ┌────────┐ ┌──────┐ │ │
│ │ │Encoder │ │Prior │ │ │
│ │ │(train) │ │Net │ │ │
│ │ └───┬────┘ └──┬───┘ │ │
│ │ └──► z ◄──┘ │ │
│ └──────────┬───────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GRU Temporal Decoder │ │
│ │ z + scene features │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ wp1 ──► wp2 ──► wp3 │ (ego + all │
│ │ (autoregressive) │ agents) │
│ └──────────────────────┘ │
│ │
│ Output: Joint ego + agent trajectories │
└─────────────────────────────────────────────────────────────┘
GenAD consists of three primary components:
1. Instance-Centric Scene Representation
Multi-camera images are processed through a backbone and BEV encoder. Rather than using the full BEV grid directly, GenAD extracts instance-level tokens: - Map tokens: Encode road topology, lane boundaries, and traffic elements - Agent tokens: Represent each detected traffic participant - Ego token: Represents the ego vehicle
These tokens interact through self-attention layers that model ego-agent and agent-agent relationships, with map tokens providing contextual grounding.
2. Trajectory Prior Modeling (VAE)
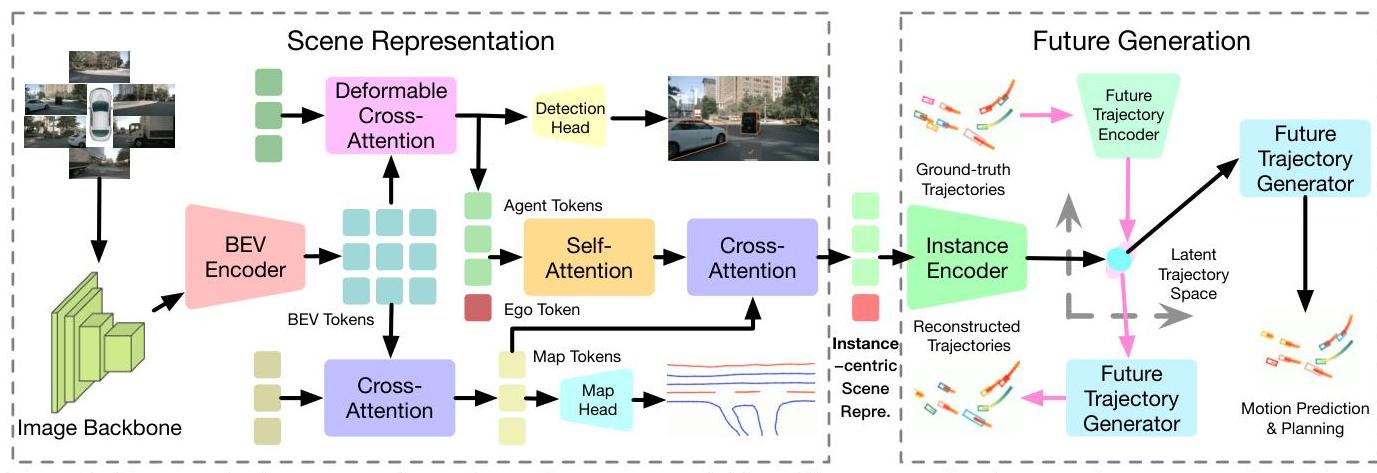
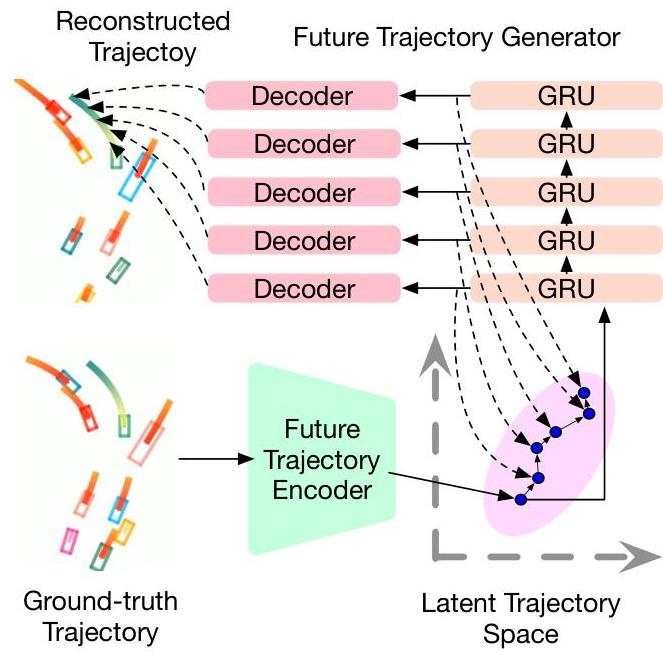
A Variational Autoencoder learns a structured latent space of realistic trajectories: - Encoder: Maps ground-truth trajectories to a latent distribution during training - Decoder: Reconstructs trajectories from latent samples - Prior network: Learns to predict the latent distribution from scene features alone (used at inference)
The VAE prior ensures generated trajectories satisfy physical constraints (smooth curvature, feasible velocities) without explicit kinematic modeling.
3. Latent Future Trajectory Generation
A GRU-based temporal decoder progressively generates waypoints: - Takes the sampled latent code and scene features as input - Generates waypoints autoregressively, conditioning each step on previously generated points - Produces trajectories for both ego and surrounding agents simultaneously - The joint generation captures interaction effects (e.g., yielding, following)
Training uses a multi-objective loss combining: - VAE reconstruction and KL divergence losses for the trajectory prior - Planning loss (L2 to ground truth ego trajectory) - Auxiliary losses for perception (detection, map segmentation) to regularize the BEV features
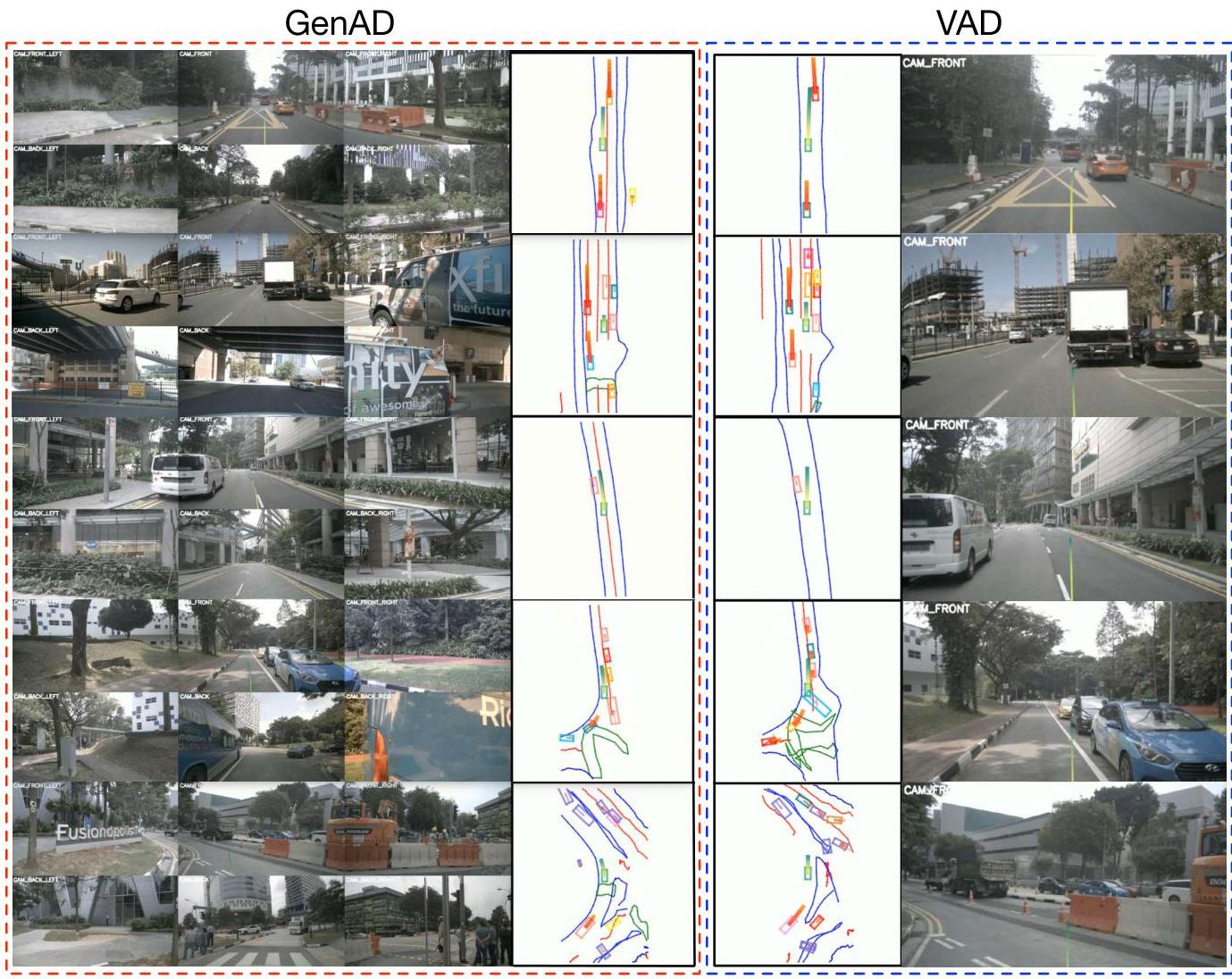
Results
| Method | L2 1s (m) | L2 3s (m) | Avg L2 (m) | Col. Rate (%) | FPS |
|---|---|---|---|---|---|
| GenAD | 0.36 | 1.55 | 0.91 | 0.43 | 6.7 |
| UniAD | 0.48 | 1.65 | 1.03 | 0.31 | ~2 |
| VAD-Tiny | 0.60 | 2.06 | 1.30 | 0.72 | ~8 |
| ST-P3 | 1.33 | 2.90 | 2.11 | 0.71 | - |
- 0.91m average L2 displacement error -- SOTA on nuScenes planning at time of publication
- 0.43% collision rate -- competitive among E2E methods (UniAD achieves 0.31% using additional supervision)
- 6.7 FPS on RTX 3090 -- faster than UniAD (~2 FPS) due to efficient instance-centric design
- Ablations confirm that ego-agent interaction modeling and the VAE trajectory prior each provide significant improvements
- Removing the generative prior degrades collision rate substantially, confirming the value of learned trajectory structure
Limitations & Open Questions
- Open-loop evaluation on nuScenes; the generative approach may particularly benefit from closed-loop validation where trajectory diversity matters
- The VAE prior assumes unimodal posterior per scenario; a more expressive generative model (e.g., diffusion) could better capture multimodal futures
- GRU-based decoding may struggle with very long-horizon predictions
- Runtime (6.7 FPS) is improved over UniAD but not yet real-time
- The instance-centric representation may lose fine-grained spatial information compared to dense BEV features
Connections
- Autonomous Driving -- generative E2E driving paradigm
- End To End Architectures -- generative vs. discriminative E2E approaches
- Planning -- trajectory generation as planning
- Prediction -- joint ego-agent trajectory prediction
- Planning Oriented Autonomous Driving -- UniAD, primary sequential baseline
- Vad Vectorized Scene Representation For Efficient Autonomous Driving -- VAD comparison
- Diffusiondrive Truncated Diffusion Model For End To End Autonomous Driving -- later diffusion-based generative planning
- Nuscenes A Multimodal Dataset For Autonomous Driving -- evaluation dataset