Note: This is the CVPR 2024 Highlight paper on large-scale video prediction for driving, NOT the ECCV 2024 paper Genad Generative End To End Autonomous Driving which addresses generative trajectory modeling for E2E driving. Despite sharing the "GenAD" name, they are entirely different works.
Overview
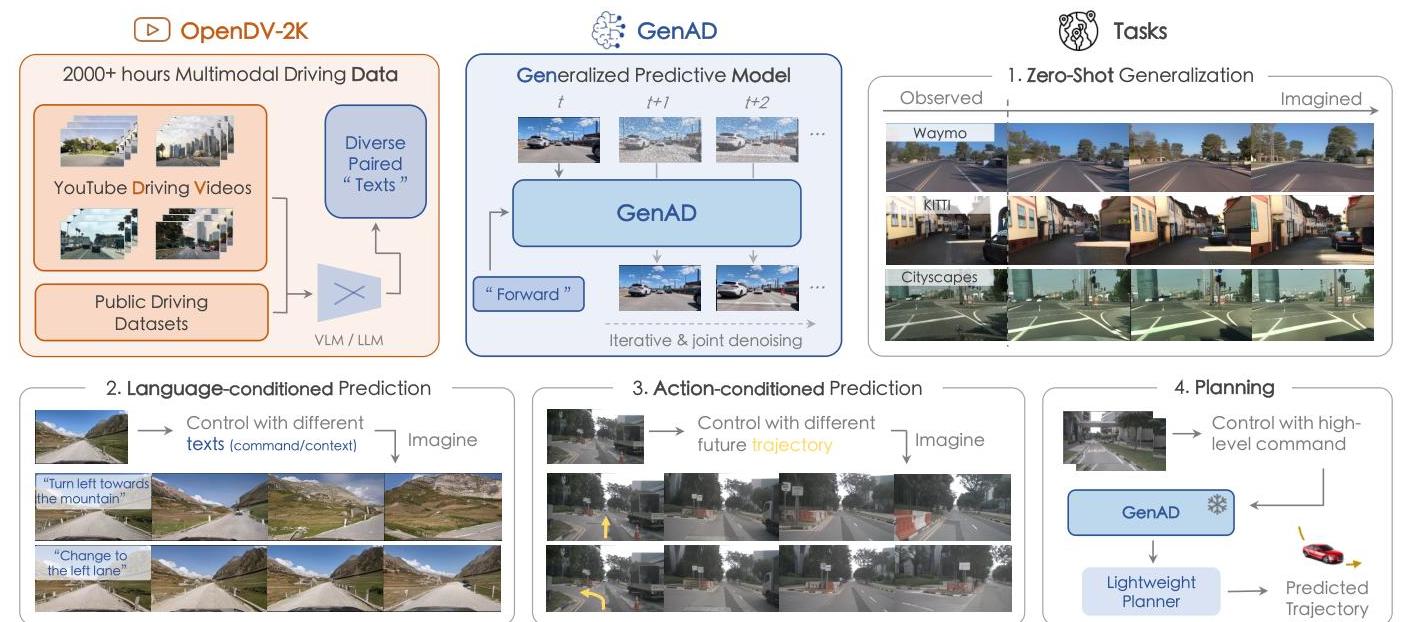
GenAD introduces a generalized predictive model for autonomous driving built on large-scale video prediction. The core insight is that driving videos serve as a "universal interface" for learning how driving environments operate -- if a model can accurately predict future video frames, it implicitly learns physics, agent behavior, and scene dynamics. Traditional modular AD systems require extensive domain-specific data collection and struggle to generalize across geographic locations, weather conditions, and driving scenarios. GenAD addresses this by pretraining on OpenDV-2K, the largest public driving video dataset containing over 2,000 hours of footage from 40+ countries and 244 cities.
The architecture adapts Stable Diffusion XL (SDXL) to the driving domain through a two-stage training process. The first stage fine-tunes SDXL on driving images to acquire domain-specific visual knowledge. The second stage adds temporal reasoning blocks with causal attention mechanisms that enforce realistic temporal causality -- future frames depend on past frames but not vice versa. A decoupled spatial attention mechanism handles the large pixel displacements caused by ego-motion, which distinguish driving video from typical video generation scenarios.
GenAD achieves a 44.5% improvement in Frechet Video Distance (FVD) compared to driving-specific video prediction alternatives, and demonstrates strong zero-shot generalization to unseen datasets (KITTI, Cityscapes, Waymo) without any additional training. Beyond video prediction, the model enables practical downstream applications: action-conditioned simulation (20.4% error reduction) and efficient planning adaptation (3,400x faster adaptation than comparable methods with 73x fewer parameters).
Key Contributions
- OpenDV-2K dataset: The largest public driving video dataset, combining 1,700+ hours of YouTube driving videos from 40+ countries with seven existing public datasets, providing unprecedented geographic and scenario diversity.
- Two-stage driving video diffusion architecture: Adapts SDXL with causal temporal attention and decoupled spatial attention designed specifically for the large ego-motion displacements in driving video.
- Zero-shot cross-dataset generalization: Maintains consistency and realism on completely unseen datasets (KITTI, Cityscapes, Waymo) without any fine-tuning, surpassing both general and driving-specific video prediction approaches.
- Downstream adaptability: Demonstrates practical utility through action-conditioned video simulation and efficient planning adaptation with minimal additional training.
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ GenAD: Two-Stage Video Prediction │
│ │
│ Stage 1: Driving Domain Adaptation │
│ ┌──────────┐ fine-tune ┌─────────────────────┐ │
│ │ SDXL │ ──────────────► │ Driving-Adapted │ │
│ │(pretrained│ on OpenDV-2K │ Image Diffusion │ │
│ │ text2img) │ driving imgs │ Model │ │
│ └──────────┘ └──────────┬──────────┘ │
│ │ │
│ Stage 2: Temporal Reasoning │ freeze spatial │
│ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ Spatial Layers (frozen) + Temporal Blocks (new) │ │
│ │ │ │
│ │ Frame t-2 ──► ┌──────────┐ │ │
│ │ Frame t-1 ──► │ Causal │ (future attends │ │
│ │ Frame t ──► │ Temporal │ only to past) │ │
│ │ │ Attention│ │ │
│ │ └────┬─────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌──────────────┐ │ │
│ │ │ Decoupled │ (handles large │ │
│ │ │ Spatial │ ego-motion │ │
│ │ │ Attention │ displacements) │ │
│ │ └──────┬───────┘ │ │
│ └─────────────────────┼─────────────────────────────┘ │
│ ▼ │
│ Predicted Future Frames │
│ │
│ Data: OpenDV-2K (2000+ hrs, 40+ countries, 244 cities) │
└─────────────────────────────────────────────────────────────┘
Stage 1: Driving Domain Adaptation
The first stage fine-tunes SDXL on driving images to adapt the pretrained text-to-image diffusion model to the driving visual domain. This produces a strong driving-specific image generation backbone that understands road layouts, vehicle appearances, weather conditions, and geographic diversity from the OpenDV-2K corpus.
Stage 2: Temporal Reasoning
The second stage freezes the spatial layers and introduces temporal reasoning blocks that are interleaved with the existing spatial layers. These temporal blocks contain two key innovations:
- Causal temporal attention: Enforces that the generation of frame t can only attend to frames 1 through t-1, preserving realistic temporal causality. This prevents information leakage from future frames and produces more physically plausible video sequences.
- Decoupled spatial attention: Standard video generation models assume small inter-frame motion. Driving video involves large pixel displacements from ego-motion (a car moving at highway speed shifts the scene substantially between frames). The decoupled spatial attention handles these large displacements by separating ego-motion-related transformations from scene-level spatial reasoning.
Deep interaction between temporal and spatial modules enables rich feature exchanges, allowing the model to reason jointly about what the scene looks like and how it evolves over time.
Training Data: OpenDV-2K
OpenDV-2K is constructed by: 1. Collecting 1,700+ hours of driving videos from YouTube spanning 40+ countries and 244 cities 2. Combining these with seven existing public driving datasets (nuScenes, nuPlan, ONCE, Honda-HAD/HDD, Talk2Car, etc.) 3. Annotating with multimodal captions describing weather, road type, agent behavior, and driving context
The geographic and scenario diversity is critical: models trained only on single-city datasets (e.g., nuScenes from Boston/Singapore) fail to generalize to different road styles, driving conventions, and environments.
Action-Conditioned Generation
For downstream simulation, GenAD conditions video generation on ego-vehicle actions (steering, speed), enabling controllable driving video synthesis. This transforms the video predictor into a lightweight world simulator that can evaluate planning policies by generating realistic visual futures conditioned on proposed actions.
Results
GenAD achieves strong quantitative results across video prediction and downstream tasks:
Video Prediction Quality
| Method | FVD ↓ | Zero-Shot Generalization |
|---|---|---|
| GenAD | best | Yes (KITTI, Cityscapes, Waymo) |
| Driving-specific baselines | 44.5% worse | Limited |
| General video prediction | Worse | No |
Downstream Applications
| Application | Improvement | Details |
|---|---|---|
| Action-conditioned simulation | 20.4% error reduction | Controllable driving video synthesis |
| Planning adaptation | 3,400x faster, 73x fewer params | Efficient transfer to planning tasks |
Zero-Shot Generalization
The model demonstrates consistent video quality on datasets it was never trained on (KITTI, Cityscapes, Waymo), maintaining realistic scene dynamics, lighting, and agent behavior. This is a significant result because most driving models degrade severely on out-of-distribution cities and road styles.
Limitations & Open Questions
- Caption quality: The multimodal annotations from YouTube videos are noisier than curated research datasets; caption quality limits conditioning effectiveness.
- Computational efficiency: Diffusion-based video generation remains expensive at inference time, limiting real-time deployment for planning.
- Long-term consistency: Video prediction quality degrades over longer time horizons; maintaining physical consistency across many frames remains challenging.
- Evaluation metrics: FVD and related metrics may not fully capture the aspects of video quality that matter most for downstream driving tasks.
- Bridge to planning: While the paper shows planning adaptation results, the gap between video prediction quality and planning utility is not fully characterized.
Connections
Related papers in the wiki:
- Genad Generative End To End Autonomous Driving — The OTHER GenAD paper (ECCV 2024), which uses generative modeling for trajectory prediction rather than video prediction. Complementary approaches: one generates future videos, the other generates future trajectories.
- Cosmos World Foundation Model Platform For Physical Ai — Cosmos is another large-scale world model platform for physical AI; GenAD can be seen as a driving-specific precursor to this broader vision.
- Denoising Diffusion Probabilistic Models — GenAD builds on the DDPM framework, adapting diffusion-based generation from images to temporally consistent driving video.
- Nuscenes A Multimodal Dataset For Autonomous Driving — One of the datasets included in OpenDV-2K and used for evaluation.
- Drive Occworld Driving In The Occupancy World — Another world model approach to driving, but using 4D occupancy rather than video as the prediction target.
- Hermes A Unified Self Driving World Model For Simultaneous 3D Scene Understanding And Generation — Unified world model for 3D scene understanding and generation; shares the world-model-for-driving vision.
- Drivegpt Scaling Autoregressive Behavior Models For Driving — DriveGPT also uses large-scale pretraining for driving behavior modeling, but via autoregressive tokens rather than diffusion video.
- Prediction — Video prediction as a form of scene-level forecasting.
- Autonomous Driving — Broader driving context.
- Foundation Models — GenAD exemplifies the foundation-model approach: pretrain large on diverse data, then adapt to specific tasks.