Overview
HERMES tackles a fundamental limitation in autonomous driving: existing systems treat 3D scene understanding and future scene generation as separate problems. Driving World Models excel at generating future scene predictions but function as black boxes unable to explain reasoning, while Large Language Models applied to driving provide rich interpretability but cannot predict future 3D environment states. This separation creates a critical gap in systems needing comprehensive situational awareness.
HERMES introduces a unified framework built around three key components: a Bird's-Eye View (BEV) tokenizer, a Large Language Model backbone, and a novel "world queries" mechanism for knowledge transfer between understanding and generation tasks. The BEV tokenizer compresses multi-view camera features into a manageable spatial representation, while world queries enable the LLM to share knowledge between textual scene understanding and 3D future prediction within a single forward pass.
The system achieves a 32.4% reduction in Chamfer Distance compared to ViDAR for future point cloud prediction, while outperforming OmniDrive by 8.0% on CIDEr for scene captioning. Scaling experiments from 0.8B to 3.8B parameters show consistent improvements, suggesting further gains with larger models.
Key Contributions
- First unified framework that simultaneously performs 3D scene understanding (captioning, QA) and future scene generation (point cloud prediction) within a single LLM (InternVL2)
- Novel "world queries" mechanism enabling cross-task knowledge transfer between understanding and generation through LLM causal attention
- BEV tokenization approach that compresses multi-view camera features into LLM-compatible spatial representations using BEVFormer v2
- Differentiable volume rendering pipeline (SDF-based, similar to NeRF) for converting BEV features into predicted 3D point clouds
- Demonstrated that unification improves generation quality over separated approaches, validating true synergy between understanding and generation
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ HERMES ARCHITECTURE │
│ │
│ Multi-View Cameras │
│ ┌─────┐┌─────┐┌─────┐ │
│ │Cam 1││Cam 2││Cam N│ │
│ └──┬──┘└──┬──┘└──┬──┘ │
│ └──────┼──────┘ │
│ ▼ │
│ ┌──────────────────┐ ┌──────────────────────┐ │
│ │ CLIP ConvNeX-L │────►│ BEVFormer v2 │ │
│ │ (frozen) │ │ (BEV Tokenizer) │ │
│ └──────────────────┘ └─────────┬────────────┘ │
│ │ BEV Features │
│ ┌─────────┴──────────┐ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌────────────────┐ │
│ │ Down-sample │ │ Max-Pool ──► │ │
│ │ + Project │ │ World Queries │ │
│ └──────┬───────┘ │ + Ego-Motion │ │
│ │ │ + Frame Embed │ │
│ │ └───────┬────────┘ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ LLM Backbone (InternVL2) │ │
│ │ [BEV tokens | Text tokens | World Q] │ │
│ │ Causal Attention ──► Knowledge │ │
│ │ Transfer (understanding ─► gen.) │ │
│ └────────┬──────────────┬───────────────┘ │
│ │ │ │
│ ┌─────────▼──┐ ┌──────▼──────────────┐ │
│ │ Text Output │ │ Current-to-Future │ │
│ │ (Captions, │ │ Cross-Attention │ │
│ │ QA) │ │ ▼ │ │
│ └────────────┘ │ Volume Rendering │ │
│ │ (SDF-based, NeRF) │ │
│ │ ▼ │ │
│ │ 3D Point Cloud │ │
│ │ Prediction │ │
│ └─────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
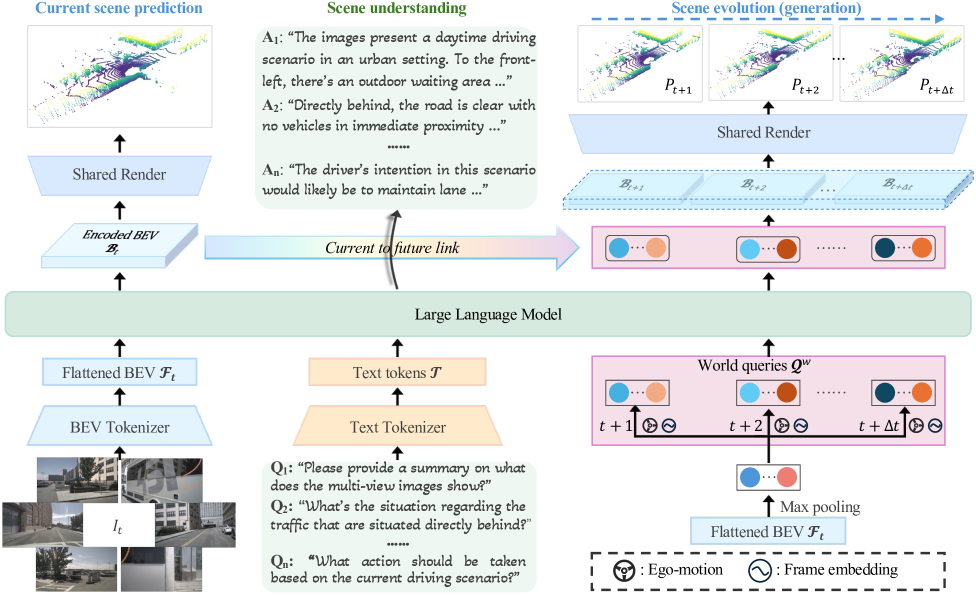
The architecture processes multi-view camera images through a pre-trained CLIP ConvNeX-L encoder, aggregating features into BEV representation via BEVFormer v2. BEV features are compressed through down-sampling and projection to fit within LLM context limits. The LLM backbone is InternVL2, evaluated at scales from 0.8B to 3.8B parameters.
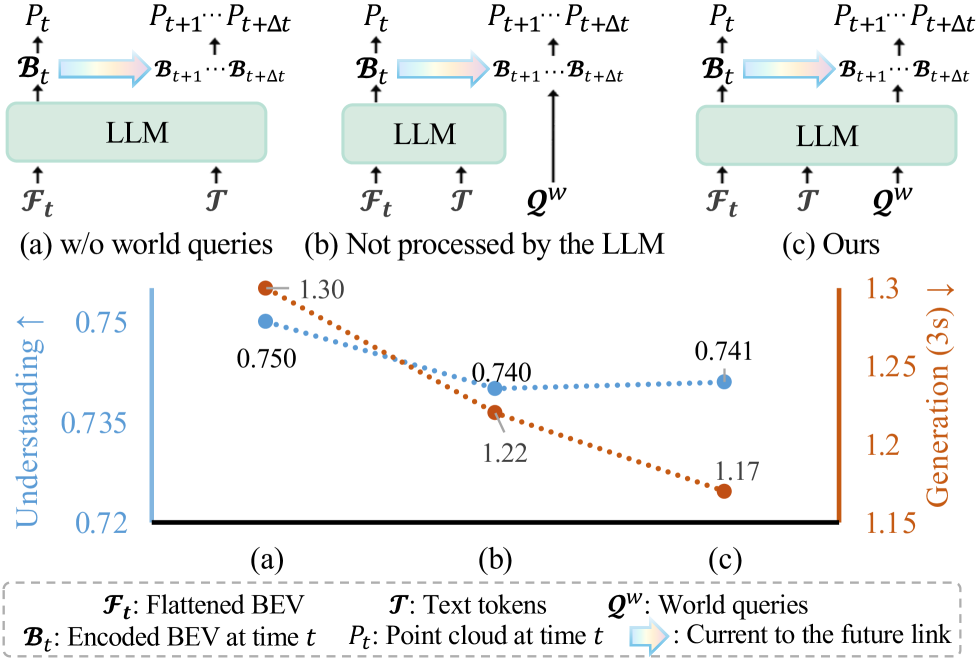
World Queries Mechanism: - Initialized by max-pooling raw BEV features to capture salient scene information - Enriched with ego-motion conditions and frame embeddings for controllable future generation - Appended to LLM input alongside BEV features and text tokens - LLM causal attention allows queries to access world knowledge from textual understanding - A "current-to-future link" module uses cross-attention to inject enriched knowledge into future BEV representations
Volume Rendering: HERMES converts BEV features into 3D point clouds using differentiable volume rendering. It predicts Signed Distance Function (SDF) values along sampled rays, similar to NeRF, producing dense 3D scene predictions.
Training: Multi-stage approach with loss $L = L_N + 10L_D$ where $L_N$ is next-token prediction loss and $L_D$ is L1 depth loss against ground-truth LiDAR. Stages progress through tokenizer pre-training, BEV-text alignment, and final unification.
Results
| Task | Metric | HERMES | Previous SOTA | Improvement |
|---|---|---|---|---|
| Future Point Cloud | Chamfer Distance | -- | ViDAR | -32.4% |
| Scene Captioning | CIDEr | -- | OmniDrive | +8.0% |
Ablation Insights: - World queries reduce Chamfer Distance by 10% for 3-second predictions - Processing queries through LLM (vs. bypass) further improves generation, confirming knowledge transfer - Unified approach outperforms separated baselines where understanding and generation share features but use separate models - Consistent scaling improvements from 0.8B to 3.8B parameters
The system demonstrates controllable generation, conditioning future predictions on different ego-motion commands ("stop", "turn right"), and provides contextually rich scene descriptions alongside 3D predictions.
Limitations & Open Questions
- Relies on BEVFormer v2 as a frozen perception backbone, inheriting its failure modes in adverse conditions
- Volume rendering quality is limited by BEV resolution; fine-grained details (small objects, distant regions) may be lost
- Whether the unified approach scales to longer prediction horizons (beyond 3 seconds) remains untested
Connections
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer provides the spatial feature backbone
- Wote End To End Driving With Online Trajectory Evaluation Via Bev World Model -- Complementary BEV world model approach focused on trajectory evaluation
- Learning Transferable Visual Models From Natural Language Supervision -- CLIP encoder used for visual feature extraction
- Planning Oriented Autonomous Driving -- UniAD's joint training philosophy extended to world modeling
- Nuscenes A Multimodal Dataset For Autonomous Driving -- Primary evaluation dataset