Overview
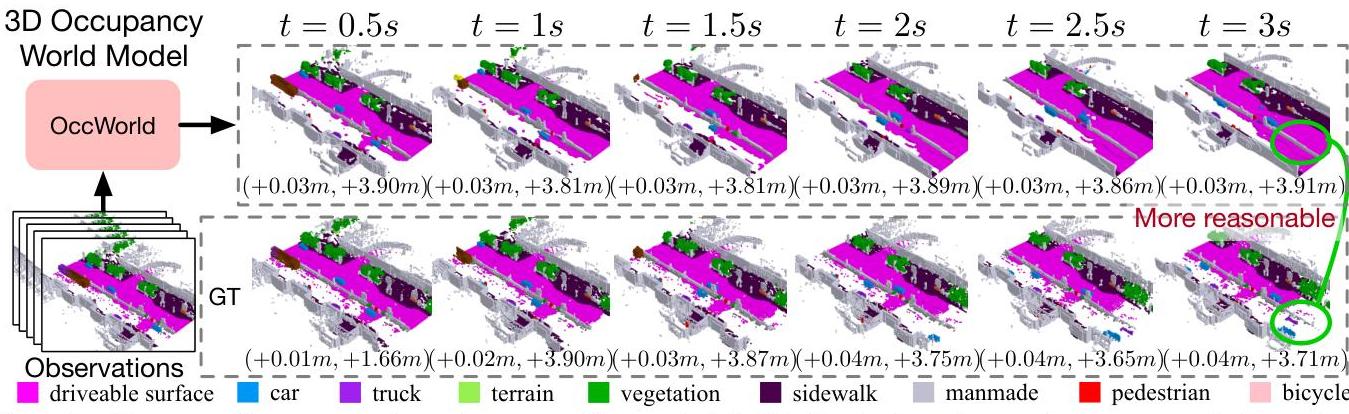
OccWorld introduces a generative world model that operates in 3D semantic occupancy space, jointly forecasting future scene evolution and ego vehicle trajectories. The key idea is to tokenize 3D occupancy volumes using a VQ-VAE, then train a GPT-like spatial-temporal transformer to autoregressively predict future scene tokens and ego motion. This enables the model to "imagine" future 3D scenes conditioned on ego actions, providing both occupancy forecasting for perception and trajectory evaluation for planning. Unlike detection-based approaches, occupancy representations naturally handle irregular objects (debris, construction equipment) that bounding boxes cannot model. OccWorld achieves competitive planning with UniAD despite requiring significantly less supervision -- no HD maps or instance-level annotations needed.
Note: This is the ORIGINAL OccWorld paper (ECCV 2024, arxiv 2311.16038). A different paper, Drive-OccWorld (AAAI 2025, arxiv 2408.14197), extends this work and is documented separately at Drive Occworld Driving In The Occupancy World.
Key Contributions
- 3D occupancy as world model substrate: Uses semantic occupancy voxels as the representation for generative world modeling, enabling expressiveness across sensor modalities without instance-level supervision
- Scene tokenization via VQ-VAE: Converts continuous 3D occupancy volumes to BEV, then encodes and quantizes them into discrete tokens using a learned codebook
- Spatial-temporal GPT transformer: Hierarchical autoregressive model with spatial aggregation within timesteps and temporal causal self-attention across timesteps for joint scene and ego prediction
- Minimal supervision: Competitive planning performance without HD maps or instance annotations, unlike UniAD which requires both
Architecture / Method
OccWorld Pipeline
─────────────────
3D Semantic ┌──────────────────────┐
Occupancy ──────►│ Height Compression │
(H x W x Z) │ (3D ──► BEV) │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ CNN Encoder │
│ (Downsample BEV) │
└──────────┬───────────┘
│
▼
┌──────────────────────┐ ┌────────────┐
│ Vector Quantization │◄─────│ Codebook │
│ z = argmin||f - c|| │ └────────────┘
└──────────┬───────────┘
│
┌──────────────────┼──────────────────┐
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌──────────────┐ ┌────────────────┐
│ CNN Decoder │ │ Scene │ │ Ego Tokens │
│ (Reconstruct │ │ Tokens │ │ (Vehicle │
│ 3D Occupancy) │ │ │ │ State) │
└─────────────────┘ └──────┬───────┘ └───────┬────────┘
│ │
└────────┬──────────┘
▼
┌───────────────────────┐
│ Spatial-Temporal GPT │
│ ┌─────────────────┐ │
│ │ Spatial Attn │ │
│ │ (within timestep)│ │
│ └────────┬────────┘ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ Temporal Causal │ │
│ │ Attn (across t) │ │
│ └────────┬────────┘ │
└───────────┼───────────┘
┌────────┴────────┐
▼ ▼
Future 4D Ego Trajectory
Occupancy Prediction
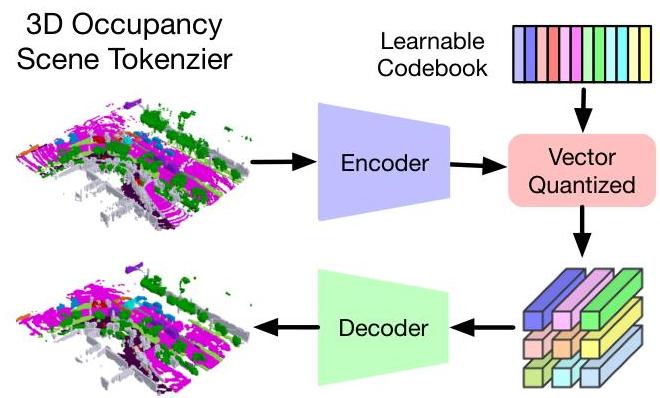
Scene Tokenizer (VQ-VAE): - Transforms 3D semantic occupancy into Bird's-Eye-View representation via height compression - CNN encoder extracts downsampled BEV features - Vector quantization maps features to nearest codebook entries: z_ij = argmin_c ||f_ij - c||_2 - Decoder reconstructs full 3D occupancy from quantized BEV tokens
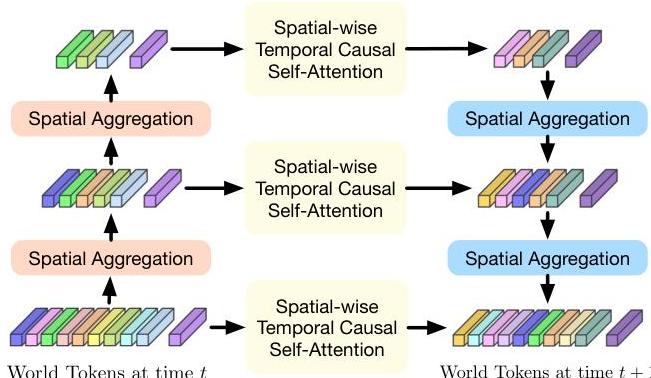
Generative Transformer: - Processes "world tokens" comprising scene tokens (quantized occupancy) and ego tokens (vehicle state) - Hierarchical multi-scale spatial processing within each timestep captures local and global scene structure - Temporal causal self-attention across timesteps: z_hat_{T+1,j,i} = Attention(z_{T,j,i}, z_{T-1,j,i}, ..., z_{T-t,j,i}) - Autoregressively generates future 4D occupancy and ego displacement
Results
4D Occupancy Forecasting (3-second horizon):
| Variant | mIoU | IoU | Supervision |
|---|---|---|---|
| OccWorld-O (ground-truth occ) | 17.14% | 26.63% | Oracle |
| OccWorld-D (dense supervision) | 8.62% | 16.53% | Dense LiDAR |
| OccWorld-T (sparse LiDAR) | 3.56% | 8.34% | Sparse LiDAR |
| OccWorld-S (self-supervised) | 0.26% | 5.00% | None |
Motion Planning:
| Method | Avg L2 (m) | L2 @1s | L2 @3s | Supervision |
|---|---|---|---|---|
| UniAD | 1.03 | -- | -- | HD maps + instances |
| OccWorld-O | 1.17 | 0.43 | 1.99 | Occupancy only |
| OccWorld-D | 1.34 | -- | -- | Dense LiDAR only |
OccWorld achieves competitive planning (1.17m vs UniAD 1.03m) despite requiring far less supervision.
Ablation Findings: - Removing spatial attention: mIoU drops from 17.14% to 10.07% - Removing temporal attention: mIoU drops to 8.98% - Eliminating ego joint modeling: L2 error degrades to 5.89m (vs 1.17m), confirming joint ego-scene modeling is essential
Limitations
- Self-supervised variant (OccWorld-S) performs poorly (0.26% mIoU), indicating occupancy tokenization still benefits substantially from supervision
- Planning results (1.17m L2) trail UniAD -- the occupancy representation is not yet sufficient to close the gap with detection-based scene understanding
- Evaluation is open-loop on nuScenes; no closed-loop validation
- VQ-VAE codebook size and spatial resolution create information bottlenecks that may limit fine-grained prediction quality
- Computational cost of 3D occupancy processing is higher than BEV-only methods
Connections
- Directly extended by Drive Occworld Driving In The Occupancy World (Drive-OccWorld, AAAI 2025) which adds semantic-conditional and motion-conditional normalization for improved occupancy forecasting and planning
- Related to Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction which reformulates occupancy world modeling using 3D Gaussians instead of voxels
- Complements Hermes A Unified Self Driving World Model For Simultaneous 3D Scene Understanding And Generation which unifies understanding and generation in a single LLM framework
- The VQ-VAE tokenization approach connects to Cosmos World Foundation Model Platform For Physical Ai which also uses tokenization for world modeling
- Perception -- occupancy as an alternative to detection for scene understanding
- Planning -- world model-based trajectory evaluation
- Autonomous Driving -- world models as a key paradigm in Era 3