Overview
GaussianWorld introduces a world model paradigm for 3D occupancy prediction that explicitly models scene evolution over time, rather than treating frames as independent entities. Traditional approaches either process single frames independently or fuse multiple frames without modeling the continuous evolution of the scene. GaussianWorld reformulates occupancy prediction as a 4D forecasting task conditioned on current sensor input, viewing the scene as a continuous space that evolves through ego-vehicle motion, dynamic object movements, and the appearance of new areas.
The key insight is that autonomous driving scenes follow relatively simple evolution rules: static elements move according to ego-vehicle motion, dynamic objects follow their own physics, and new areas come into view as the vehicle progresses. GaussianWorld decomposes scene evolution into these three fundamental factors and models each explicitly using 3D Gaussians as the scene representation. Unlike discrete voxels, Gaussians provide continuous spatial distributions with explicit object property encoding (position, size, orientation).
Evaluated on nuScenes, GaussianWorld improves mean Intersection over Union (mIoU) by over 2% compared to single-frame methods without introducing additional computational overhead during inference, making it practical for real-world deployment.
Key Contributions
- Reformulates 3D occupancy prediction as a world modeling problem with explicit scene evolution decomposition into three factors: ego motion alignment, dynamic object movement, and new area completion
- Uses 3D Gaussians as scene representation, enabling continuous spatial distributions with explicit object property modeling
- Streaming inference architecture that leverages historical Gaussians without increased computational complexity at test time
- Two-stage training with probabilistic variable-length sequence modeling for robust temporal adaptation
- Demonstrates consistent improvements over single-frame and multi-frame fusion baselines on nuScenes occupancy benchmarks
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ GaussianWorld Pipeline │
│ │
│ ┌──────────────┐ ┌──────────────────────┐ │
│ │ Current Frame │ │ Historical Gaussians │ │
│ │ Multi-view │ │ (from prev frames) │ │
│ │ Images │ └──────────┬───────────┘ │
│ └──────┬───────┘ │ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌───────────────────────────────┐ │
│ │ Image Encoder │ │ Scene Evolution Decomposition │ │
│ └──────┬───────┘ │ │ │
│ │ │ 1. Ego Motion Alignment │ │
│ │ │ (transform to current ego) │ │
│ │ │ │ │
│ │ │ 2. Dynamic Object Movement │ │
│ │ │ (predict agent motion) │ │
│ │ │ │ │
│ │ │ 3. New Area Completion │ │
│ │ │ (random priors + refine) │ │
│ │ └───────────────┬───────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Gaussian World Layers │ │
│ │ ┌────────────────────────────────────────────────┐ │ │
│ │ │ Self-Encoding ──► Cross-Attention ──► Unified │ │ │
│ │ │ Module Module Refinement │ │ │
│ │ │ (delta Δ) │ │ │
│ │ └────────────────────────────────────────────────┘ │ │
│ └──────────────────────────┬───────────────────────────┘ │
│ │ │
│ Updated Gaussians ──► Occupancy Output │
│ (also stored for next frame) │
└──────────────────────────────────────────────────────────────────┘
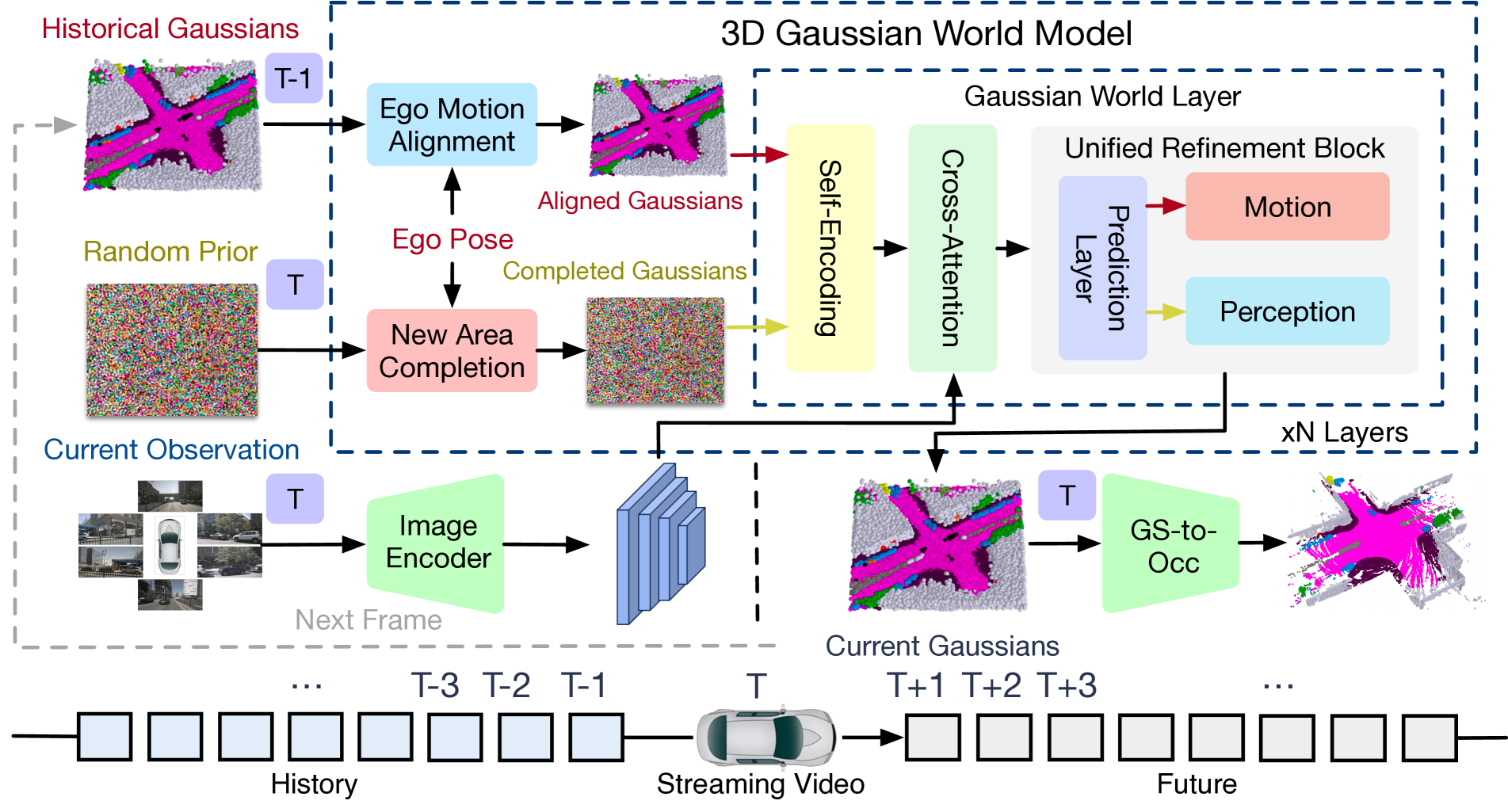
The architecture processes historical and current information through specialized modules:
Image Encoder: Extracts features from current frame multi-view images.
Scene Evolution Decomposition: 1. Ego Motion Alignment: Transforms historical Gaussians to the current coordinate system using ego-vehicle pose information. Handles static scene elements that appear to move due to vehicle motion. 2. New Area Completion: Generates Gaussians for newly observed areas using random priors refined by current observations. Handles previously occluded or out-of-view regions. 3. Dynamic Object Movement: Predicts motion of dynamic agents (vehicles, pedestrians) based on past trajectories and physics.
Gaussian World Layers (core processing): - Self-Encoding Module: processes Gaussians to extract features - Cross-Attention Module: integrates information between scene components - Unified Refinement Block: generates delta values to update Gaussian parameters for both aligned and completed Gaussians
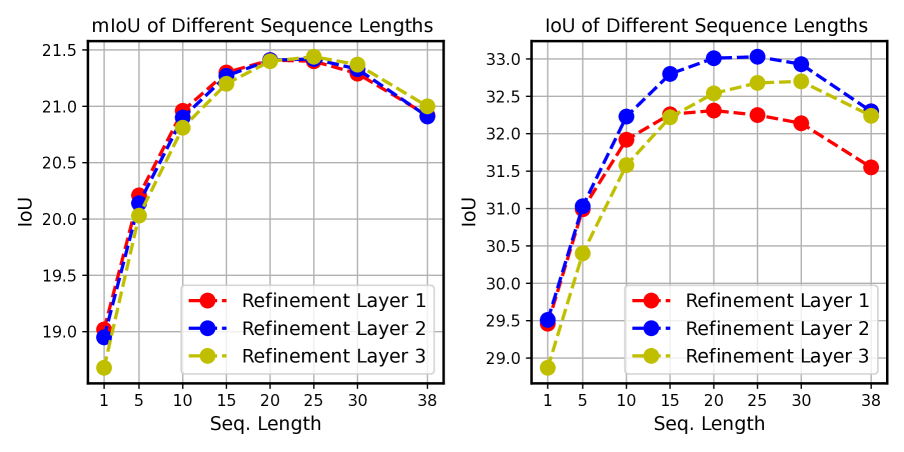
Training Strategy: 1. Pre-training on single-frame occupancy prediction 2. Fine-tuning with streaming strategy using variable-length sequences (1 to max). This teaches the model to adapt to different temporal contexts. Performance improves up to ~20-25 frames, then plateaus.
Results
| Method | Type | mIoU | Overhead |
|---|---|---|---|
| GaussianFormer (GF-B) | Single-frame | baseline | -- |
| GF-T (temporal fusion) | Temporal | +~1% | Increased |
| GaussianWorld | World model | +2%+ | None at inference |
Ablation Results: - Removing ego motion alignment: significant degradation for static elements - Disabling dynamic object prediction: reduced accuracy for moving objects - Additional refinement layers improve performance with diminishing returns after 2-3 layers - Longer sequences improve up to ~20-25 frames, then plateau or slightly decrease
Qualitative results show more temporally consistent predictions, particularly for dynamic objects, compared to single-frame and fusion baselines.
Limitations & Open Questions
- The Gaussian representation may struggle with highly irregular geometry (e.g., construction debris, vegetation) where axis-aligned or isotropic Gaussians are poor approximations
- Performance plateaus at ~20-25 frames suggest limited long-term memory; extending to longer horizons may require architectural changes
- Evaluated only on nuScenes; generalization to other driving datasets and real-world deployment conditions is untested
Connections
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer baseline; GaussianWorld extends BEV with temporal world modeling
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- Lift-Splat paradigm for camera-to-3D projection, foundational to this work
- Wote End To End Driving With Online Trajectory Evaluation Via Bev World Model -- Complementary BEV world model focused on planning verification rather than occupancy
- Nuscenes A Multimodal Dataset For Autonomous Driving -- Primary evaluation benchmark
- Planning Oriented Autonomous Driving -- UniAD's occupancy prediction module addresses similar perception needs