GaussianFormer-2: Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Overview
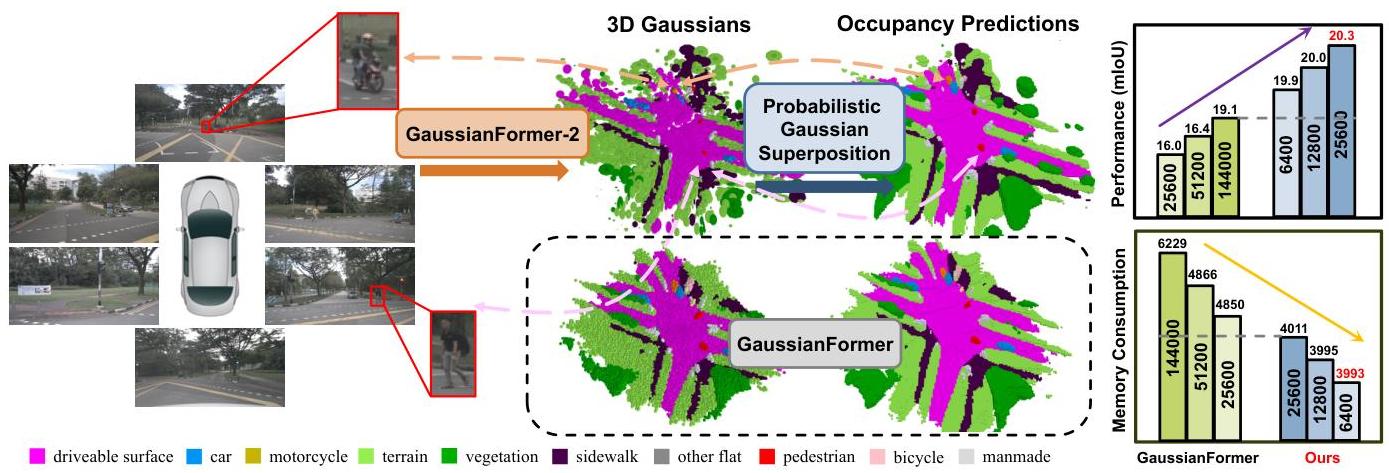
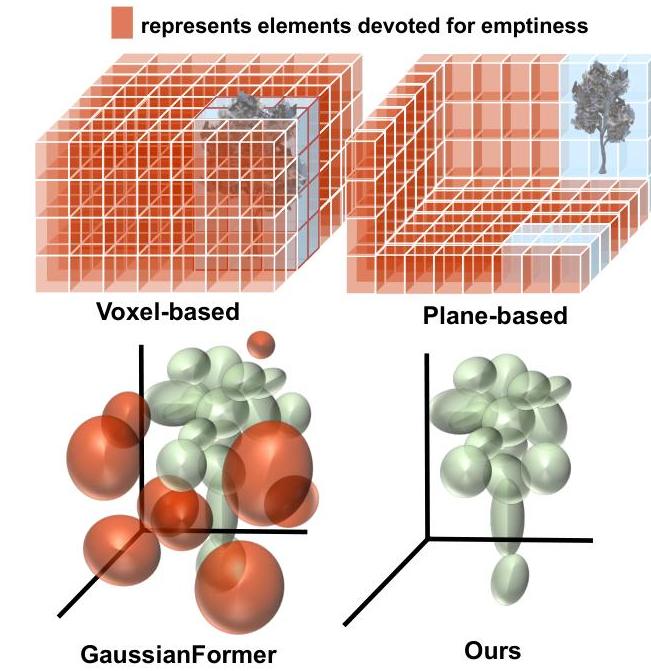
GaussianFormer-2 addresses 3D semantic occupancy prediction for vision-centric autonomous driving by rethinking how 3D Gaussians represent occupied space. The original GaussianFormer used 144,000 Gaussians with additive superposition, leading to excessive overlap and redundancy. GaussianFormer-2 introduces a probabilistic interpretation: each Gaussian represents a probability distribution of its neighborhood being occupied, and Gaussians combine via probabilistic multiplication rather than addition.
This probabilistic formulation naturally prevents unnecessary overlapping -- the overlap ratio drops from 10.99% to 3.91% -- enabling the model to achieve superior performance with only 8.9% of the Gaussians used by its predecessor in the nuScenes main result (12,800 vs 144,000). A distribution-based initialization module learns pixel-aligned occupancy distributions instead of surface depths, and a Gaussian mixture model handles semantic predictions with proper normalization. The result is roughly 51% memory savings on the nuScenes main setup (3,041 MB vs 6,229 MB) while improving mIoU on both nuScenes (+1.72pp absolute) and KITTI-360 (+0.98pp absolute, ~7.6% relative).
Key Contributions
- Probabilistic Gaussian superposition: Interprets each Gaussian as an occupancy probability distribution; uses multiplicative aggregation to derive overall geometry, naturally preventing redundant overlap
- Gaussian mixture model for semantics: Applies exact GMM for normalized semantic predictions, properly handling the different mathematical requirements of geometry vs. semantics
- Distribution-based initialization: Learns pixel-aligned occupancy distributions instead of surface depths, enabling more informative Gaussian placement without LiDAR
- Extreme efficiency: Achieves better results with 8.9% of the Gaussians in the nuScenes main result (12,800 vs 144,000) and ~51% memory reduction (3,041 MB vs 6,229 MB)
Architecture / Method

┌──────────────────────────────────────────────────────────────────┐
│ GaussianFormer-2 Pipeline │
│ │
│ ┌──────────┐ ┌──────────────┐ │
│ │ Multi-cam │───►│ Image │──► Multi-scale features │
│ │ Images │ │ Backbone │ │
│ └──────────┘ └──────┬───────┘ │
│ │ │
│ ┌───────────────▼────────────────┐ │
│ │ Distribution-based Init │ │
│ │ Per-ray occupancy distribution │ │
│ │ (replaces surface depth est.) │ │
│ └───────────────┬────────────────┘ │
│ │ │
│ Sparse Gaussian set (12.8K on nuScenes main result; │
│ 38.4K on KITTI-360, vs 144K baseline) │
│ │ │
│ ┌───────────────▼────────────────┐ │
│ │ Gaussian Encoder (iterative) │ │
│ │ ┌────────────────────────────┐ │ │
│ │ │ Self-encoding attention │ │ │
│ │ │ Image cross-attention │ │ │
│ │ │ Parameter refinement (MLP) │ │ │
│ │ └────────────────────────────┘ │ │
│ └───────────────┬────────────────┘ │
│ │ │
│ ┌────────────────────┴────────────────────┐ │
│ ▼ ▼ │
│ ┌────────────────────┐ ┌───────────────────────┐ │
│ │ Geometry: │ │ Semantics: │ │
│ │ Multiplicative │ │ Gaussian Mixture Model │ │
│ │ Probability │ │ (proper normalization) │ │
│ │ (product-of-experts │ └───────────┬───────────┘ │
│ │ reduces overlap) │ │ │
│ └─────────┬──────────┘ │ │
│ └──────────┬───────────────┘ │
│ ▼ │
│ ┌────────────────────┐ │
│ │ Dense Voxel Output │ │
│ │ (CE loss training) │ │
│ └────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
The system builds on an attention-based framework:
- Image feature extraction through a backbone network
- Distribution-based initialization: A predictor learns the pixel-aligned occupancy distribution along each camera ray, replacing depth-of-surface estimation with full occupancy probability
- Gaussian encoder: Iterative refinement via self-encoding attention and image cross-attention blocks
- Probabilistic aggregation: Geometry uses multiplicative probability (each Gaussian is P(occupied|neighbor)), semantics uses proper GMM normalization
- End-to-end training with cross-entropy loss
The key mathematical insight is that multiplicative combination of Gaussian probabilities yields a product-of-experts that concentrates probability mass where multiple Gaussians agree, naturally eliminating the overlapping artifacts of additive superposition.
Results
| Metric | GaussianFormer-2 | GaussianFormer | Change |
|---|---|---|---|
| nuScenes mIoU | 20.82% | 19.10% | +1.72pp |
| KITTI-360 mIoU | 13.90% | 12.92% | +0.98pp |
| Gaussians used (nuScenes main result) | 12,800 | 144,000 | 8.9% |
| Memory (nuScenes main result) | 3,041 MB | 6,229 MB | -51% |
| Overlap ratio | 3.91% | 10.99% | -64% |
- Overlap ratio drops by 64%, validating that multiplicative aggregation naturally prevents redundancy
- State-of-the-art performance on both nuScenes and KITTI-360 with significantly fewer Gaussians
Limitations
- Still requires supervised 3D occupancy labels for training; not self-supervised like GaussTR
- Even 12,800-38,400 Gaussians may still be insufficient for complex urban scenes with many small objects
- Probabilistic multiplication assumes independence between Gaussians, which may not hold in practice
- Evaluated only on camera-based perception; LiDAR fusion could further improve results
Connections
- Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- GaussianWorld uses Gaussians for temporal occupancy prediction; GaussianFormer-2 improves the static representation
- Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting -- Both use Gaussian representations for efficient 3D perception; GaussianLSS focuses on BEV, GaussianFormer-2 on full 3D occupancy
- Gausstsr Foundation Model Aligned Gaussian Transformer For Self Supervised 3D -- GaussTR uses Gaussians with self-supervised learning; GaussianFormer-2 uses supervised probabilistic formulation
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer established query-based BEV perception; GaussianFormer-2 extends to 3D Gaussian queries
- Perception -- Advances 3D occupancy prediction with Gaussian representations
- Autonomous Driving -- Efficient scene representation for camera-based driving